7장. 수십억 개의 웹페이지에서 0.3초 만에 찾기
“검색 엔진, 인덱싱, 알고리즘”
이번 장에서 알게 될 것
- 구글이 수십억 개의 웹페이지에서 0.3초 만에 결과를 보여주는 원리
- 인터넷의 모든 페이지를 수집하는 로봇이 실제로 존재한다는 것
- “검색 잘 되는 사이트“를 만들기 위한 보이지 않는 전쟁
- 배달앱에서 “치킨“을 검색하면 벌어지는 일
치킨 주문 여정: 서버에 도착했다
TCP의 보호를 받으며 데이터가 배달의민족 서버에 도착했습니다. 검색창에 “치킨“이라고 입력했습니다. 서버에는 수십만 개의 가게 정보가 있습니다. 이 중에서 우리에게 맞는 결과를 어떻게 골라낼까요?
책 한 권에서 “치킨“을 찾아라
구글에 뭔가를 검색하면 약 0.3초 만에 결과가 나옵니다. 수십억 개의 웹페이지 중에서입니다.
이것이 왜 놀라운지 이해하려면, 먼저 “검색“이 얼마나 어려운 일인지를 알아야 합니다.
도서관을 떠올려 보겠습니다. 100만 권의 책이 있는 도서관에서 “치킨 레시피“라는 단어가 들어간 책을 찾아야 합니다. 가장 단순한 방법은 1번 책부터 100만 번째 책까지 한 권씩 열어보는 것입니다. 이것을 순차 검색(Linear Search) 이라고 합니다. 최악의 경우 100만 권을 전부 확인해야 합니다.
사서라면 이렇게 하지 않을 겁니다. 책 뒤에 있는 “찾아보기(색인)” 를 펴겠죠.

“치킨“이라는 단어를 찾아서, 그 단어가 나오는 페이지 번호를 바로 확인합니다. 100만 권을 열어볼 필요 없이, 색인 하나를 펼치면 됩니다.
검색 엔진이 하는 일의 핵심이 바로 이것입니다. 인터넷 전체의 “찾아보기“를 미리 만들어 놓는 것입니다.
크롤러: 웹을 돌아다니는 로봇
색인을 만들려면 먼저 모든 책(웹페이지)을 읽어야 합니다. 이 일을 하는 것이 크롤러(Crawler) 입니다. 거미(spider)가 거미줄을 따라 돌아다니는 것처럼, 웹페이지의 링크를 따라 인터넷을 돌아다닌다고 해서 “웹 스파이더“라고도 합니다.
구글의 크롤러는 Googlebot이라는 이름을 가지고 있습니다.
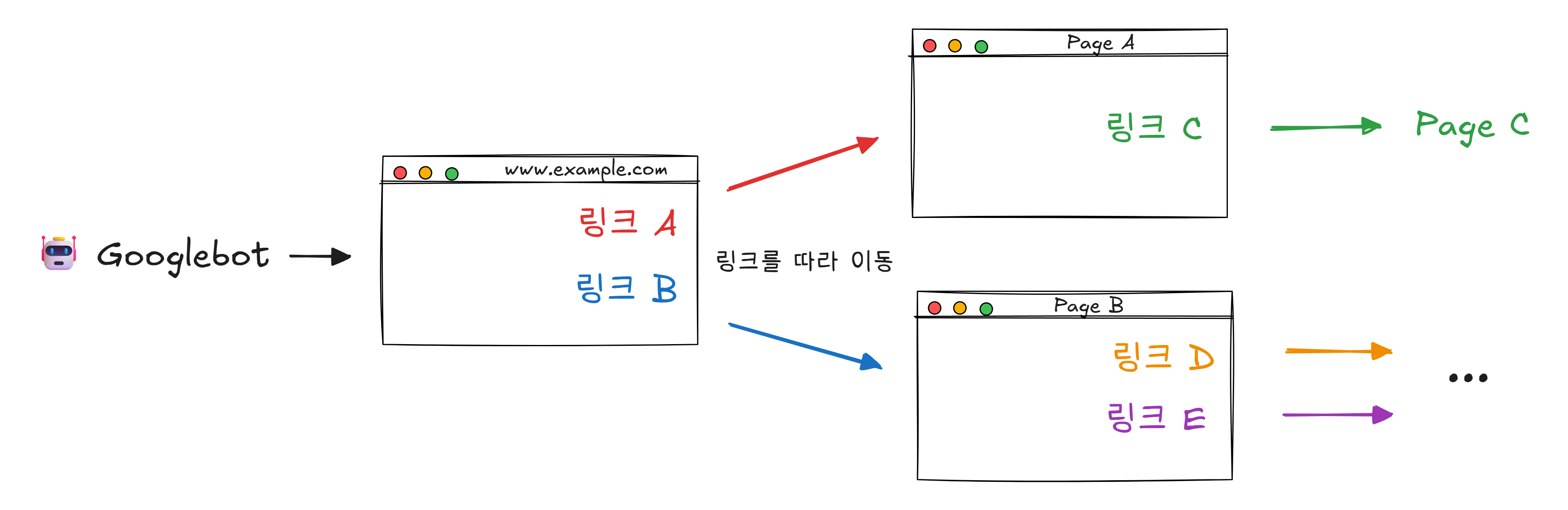
Googlebot은 하루에 수십억 개의 페이지를 방문합니다. 각 페이지의 내용을 읽고, 거기에 있는 링크를 목록에 추가하고, 다시 그 링크를 방문합니다. 이 과정을 끝없이 반복합니다.
그런데 인터넷에는 새로운 페이지가 매초 수천 개씩 생겨납니다. 기존 페이지도 수시로 내용이 바뀝니다. 크롤러는 새 페이지도 찾아야 하고, 이미 방문한 페이지도 주기적으로 다시 방문해서 변경사항을 확인해야 합니다.
중요한 페이지(뉴스 사이트, 대형 쇼핑몰)는 몇 분에 한 번씩, 덜 중요한 페이지는 며칠에 한 번씩 방문합니다. 이 우선순위를 정하는 것도 알고리즘입니다.
역 인덱스: 인터넷의 “찾아보기”
크롤러가 수집한 페이지로 만드는 것이 역 인덱스(Inverted Index) 입니다.
일반적인 인덱스(목차)는 “페이지 → 그 안에 있는 단어들“입니다. 역 인덱스는 반대입니다. “단어 → 그 단어가 있는 페이지들” 입니다.

“치킨“을 검색하면, 역 인덱스에서 “치킨“을 찾기만 하면 됩니다. 수십억 개의 웹페이지를 하나씩 열어볼 필요가 없습니다. 미리 만들어 놓은 “찾아보기“에서 해당 항목을 꺼내면 됩니다.
이것이 0.3초의 비밀입니다. 구글이 빠른 이유는 검색할 때 인터넷을 뒤지는 것이 아니라, 이미 정리해 놓은 목록에서 꺼내기만 하는 것이기 때문입니다.
물론 “치킨“이라는 단어가 포함된 페이지는 수억 개일 수 있습니다. 중요한 것은 이 중에서 어떤 페이지를 먼저 보여줄 것인가입니다.
PageRank: 투표로 중요도를 정하다
1996년, 스탠퍼드 대학원생 래리 페이지와 세르게이 브린은 하나의 아이디어를 냅니다.
“많은 페이지가 링크하는 페이지는 중요한 페이지다.”
이것이 PageRank1입니다. 구글의 시작이었습니다.
논문을 떠올려 보겠습니다. 학술 논문의 가치는 “얼마나 많은 다른 논문이 이 논문을 인용하는가“로 측정됩니다. 100편의 논문이 인용한 논문은, 2편만 인용한 논문보다 중요할 가능성이 높습니다.
웹페이지의 링크도 마찬가지입니다. 다른 페이지가 “이 페이지를 봐라“며 링크를 거는 것은 투표와 같습니다.
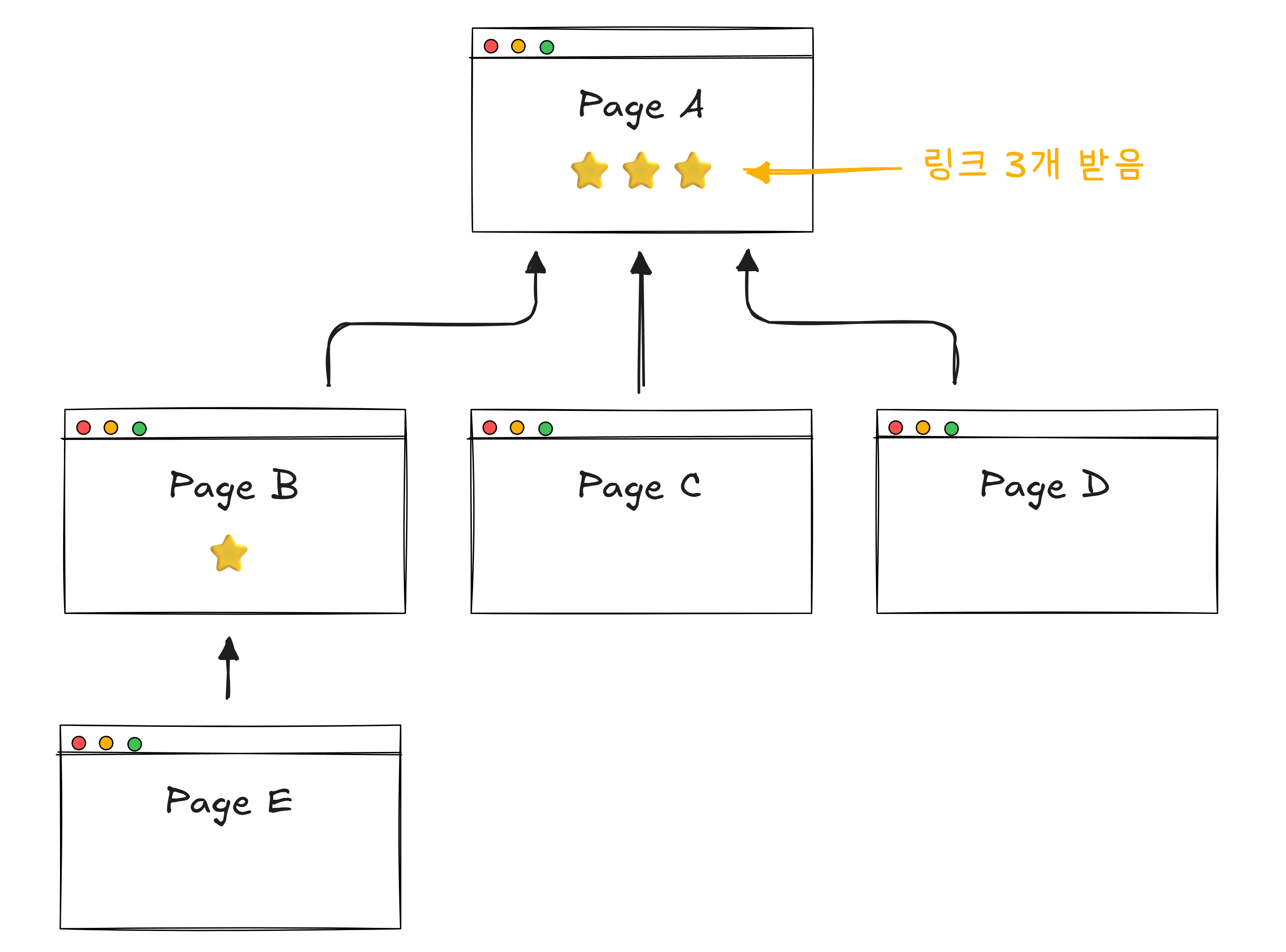
핵심은 “누가 링크했는가” 도 중요하다는 것입니다. 아무도 모르는 블로그가 링크하는 것보다, 뉴욕타임스가 링크하는 것이 더 높은 점수를 줍니다. 뉴욕타임스 자체가 이미 많은 링크(투표)를 받은 중요한 페이지이기 때문입니다.
PageRank 이전의 검색 엔진들은 “치킨“이라는 단어가 많이 나오는 페이지를 위에 보여줬습니다. 그래서 의미 없는 페이지에 “치킨 치킨 치킨 치킨…“을 도배하면 검색 상위에 올라갈 수 있었습니다. PageRank는 이 문제를 해결했습니다. 단어의 빈도가 아니라, 다른 페이지들의 “추천“으로 중요도를 판단하니까요.
물론 현재 구글의 검색 알고리즘은 PageRank 하나로 돌아가지 않습니다. 수백 개의 요소를 복합적으로 고려합니다. 검색어와의 관련성, 페이지의 최신성, 사용자의 위치, 모바일 친화성 등. 하지만 PageRank는 여전히 핵심 원리 중 하나이며, “링크 = 투표“라는 아이디어는 웹 검색의 패러다임을 바꿨습니다.
검색어 자동완성: 타이핑할 때마다 서버에 물어본다
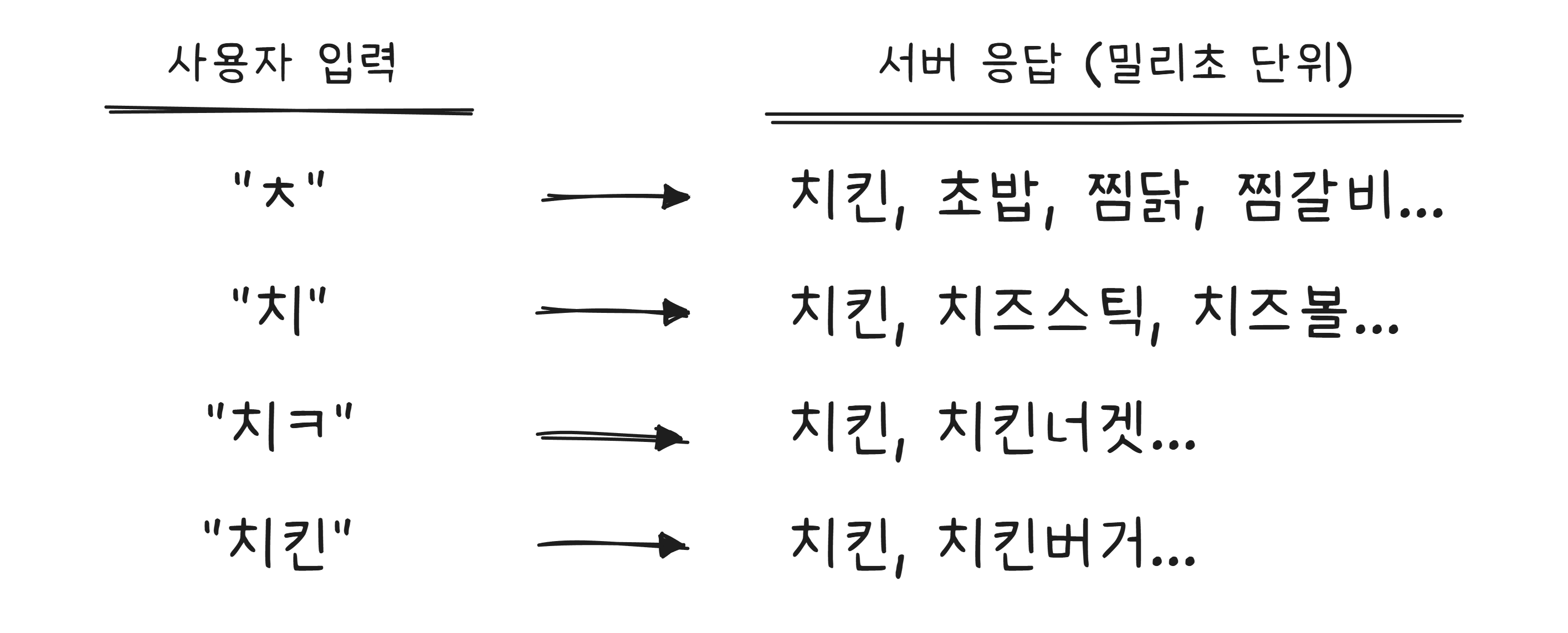
배달앱에서 “치“를 입력하면 “치킨”, “치즈스틱”, “치즈볼“이 자동으로 나타납니다. “치ㅋ“까지 입력하면 “치킨“만 남습니다.
이것은 글자를 입력할 때마다 서버에 요청을 보내는 겁니다. “ㅊ” → 서버 요청 → “치” → 서버 요청 → “치ㅋ” → 서버 요청. 타이핑 속도에 맞춰 밀리초 단위로 응답이 와야 하므로, 자동완성은 검색 시스템에서 가장 빠른 응답 속도를 요구하는 기능 중 하나입니다.
이 속도를 가능하게 하는 자료구조2가 트라이(Trie) 입니다. 트라이는 문자열을 한 글자씩 나무(트리) 형태로 저장합니다.
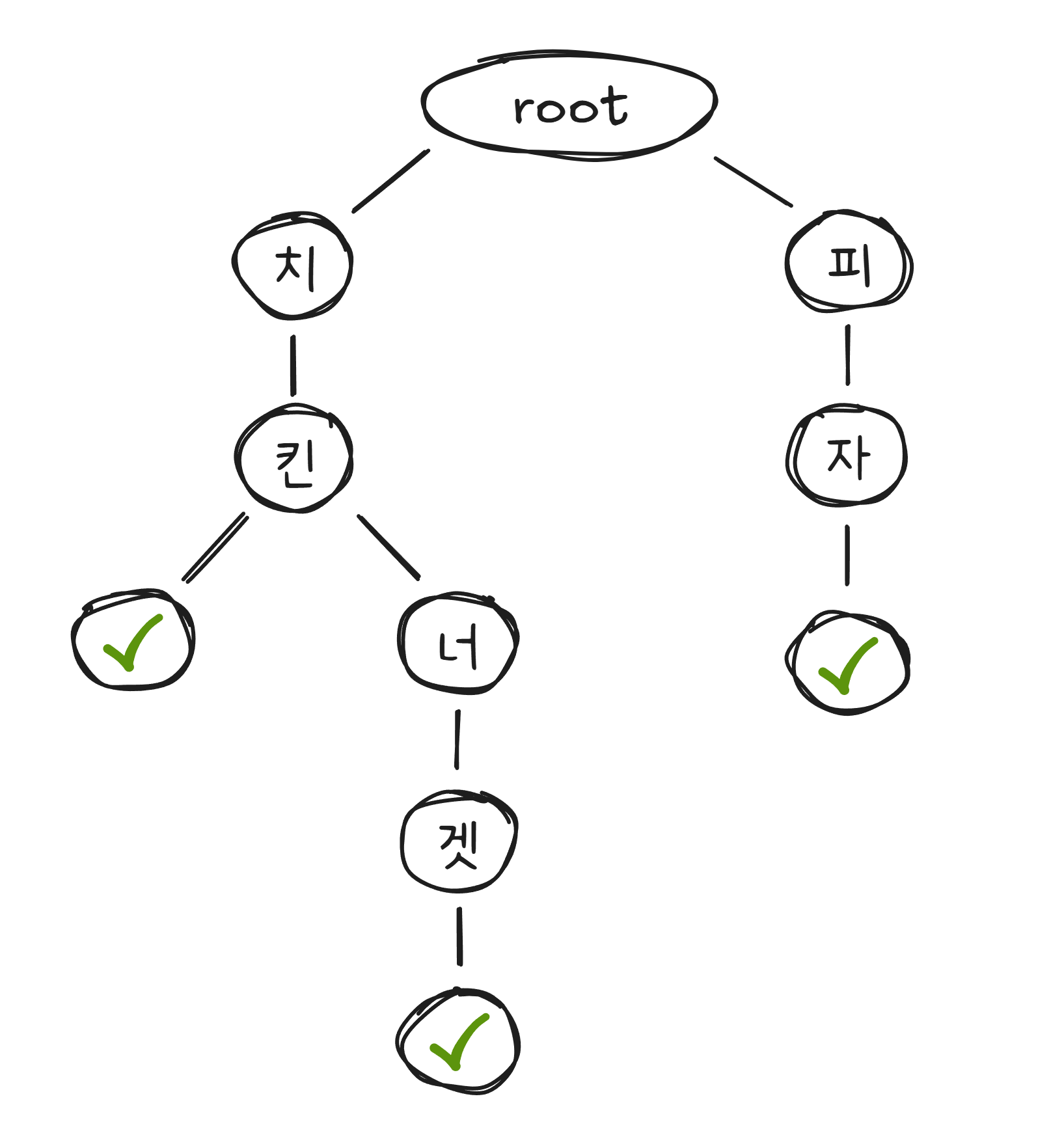
“치“까지 입력하면 트라이에서 “치” 노드로 이동하고, 그 아래에 달린 모든 단어를 후보로 보여줍니다. 처음부터 전체 목록을 검색하는 것이 아니라, 입력한 글자만큼만 트리를 따라 내려가면 되므로 매우 빠릅니다.
배달앱의 검색은 더 복잡하다
구글은 “치킨“을 검색하면 전 세계의 치킨 관련 페이지를 보여줍니다. 하지만 배달앱에서 “치킨“을 검색하면 내 주변 치킨집만 보여줍니다. 단순한 텍스트 검색이 아니라, 여러 조건을 동시에 고려해야 합니다.
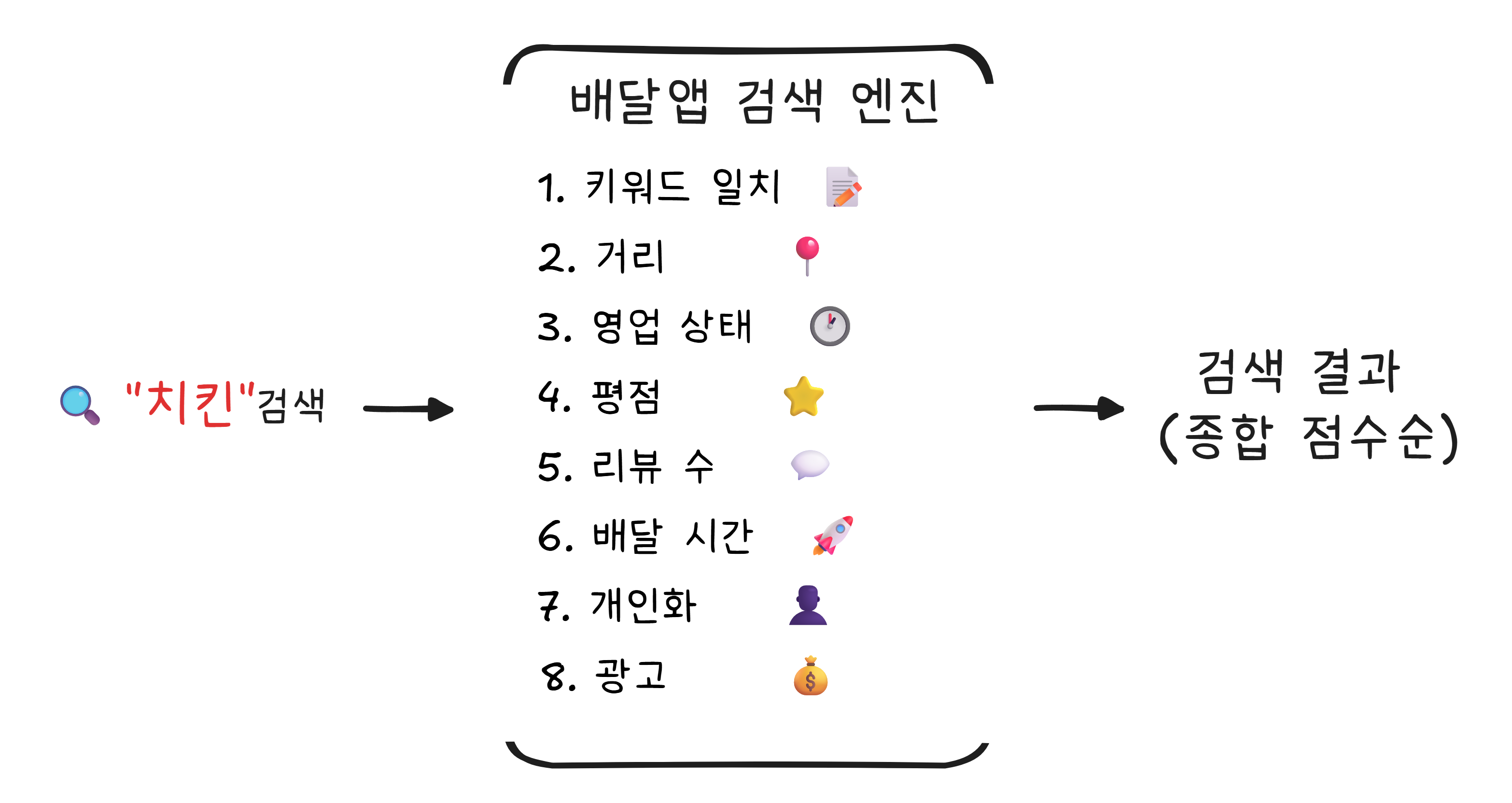
이 모든 조건에 가중치를 매기고, 종합 점수가 높은 순서대로 결과를 보여줍니다. 같은 “치킨“을 검색해도, 강남에서 검색하는 사람과 부산에서 검색하는 사람이 보는 결과는 완전히 다릅니다.
검색 결과의 맨 위에 “광고“라고 표시된 가게가 있는 것도 알고리즘의 일부입니다. 기본적으로는 관련성 순으로 정렬하되, 광고비를 낸 가게에게 상위 노출 기회를 주는 것. 이것이 배달앱의 수익 모델이기도 합니다.
사건: SEO 전쟁 — 검색 결과 1페이지를 차지하라
검색 결과의 첫 페이지에 나오는 것과 두 번째 페이지에 나오는 것은 하늘과 땅 차이입니다. 통계에 따르면 검색 사용자의 약 75% 가 첫 페이지 너머로 넘어가지 않습니다. “시체를 숨기기 가장 좋은 곳은 구글 검색 결과 2페이지“라는 우스갯소리가 있을 정도입니다.
그래서 SEO(Search Engine Optimization)3 전쟁이 벌어집니다.
초기 검색 엔진 시절에는 노골적인 수법이 통했습니다.
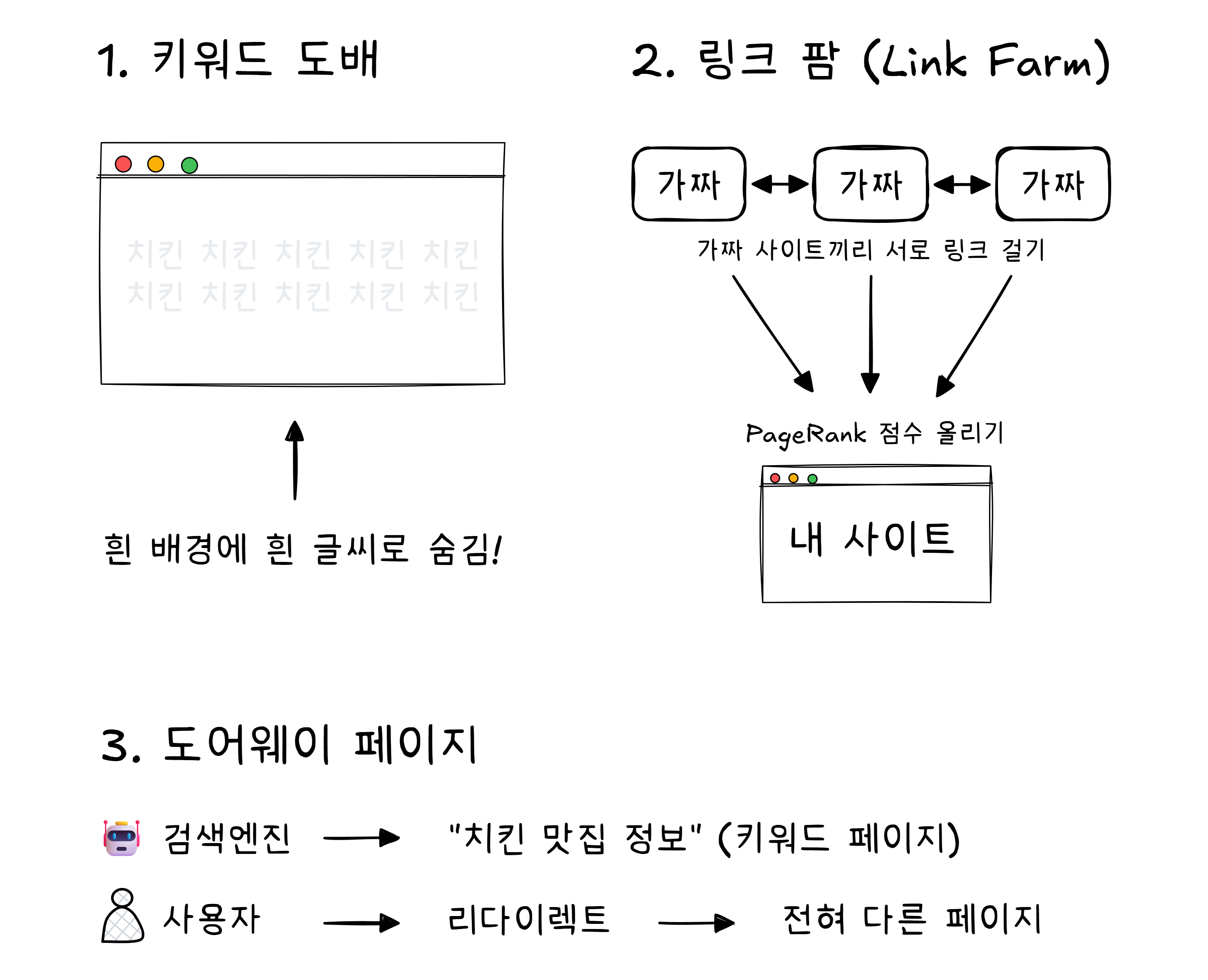
구글은 이를 막기 위해 알고리즘을 계속 업데이트합니다. 대표적인 것이 2011년의 판다 업데이트4와 2012년의 펭귄 업데이트5입니다. 판다는 저품질 콘텐츠를 걸러내고, 펭귄은 부정한 링크 조작을 감지합니다.
이 업데이트들이 적용될 때마다, 부정한 방법으로 상위에 올라와 있던 사이트들이 하루아침에 검색 결과에서 사라졌습니다. 어떤 기업들은 검색 유입이 90% 이상 급감해서 실질적으로 사업이 망하기도 했습니다.
현재도 이 전쟁은 계속되고 있습니다. 구글은 검색 알고리즘의 상세 내용을 공개하지 않으며, 매년 수천 번의 알고리즘 변경을 합니다. SEO 업계는 구글의 변경을 분석하고 대응합니다. 구글은 다시 새로운 대책을 내놓습니다. 검색 결과 1페이지를 둘러싼 이 보이지 않는 전쟁은 끝날 기미가 없습니다.
알쓸신잡
-
구글에서 가장 많이 검색하는 단어는 “youtube”: 전 세계에서 구글에 가장 많이 입력되는 검색어 1위는 “youtube“입니다. “google”, “facebook”, “amazon” 같은 사이트 이름도 최상위권입니다. 주소창에 URL을 직접 입력하는 대신 검색해서 들어가는 사람이 그만큼 많다는 뜻입니다. 웹 브라우저의 주소창과 검색창이 하나로 합쳐진 이유이기도 합니다.
-
“Google“이 동사가 된 날: 2006년, 옥스퍼드 영어 사전에 “google“이 동사로 등재됩니다. “Just google it(그냥 구글에 검색해 봐).” 브랜드 이름이 일반 동사가 된 드문 사례입니다. 한국에서도 “검색해 봐” 대신 “구글링해 봐“라는 표현을 쓸 정도로, 검색의 대명사가 된 사례입니다.
-
딥웹과 다크웹은 다르다: 구글 검색에 나오지 않는 인터넷 영역을 딥웹(Deep Web) 이라고 합니다. 이메일 받은편지함, 은행 계좌 페이지, 기업 내부 시스템 등 로그인해야 볼 수 있는 모든 페이지가 딥웹입니다. 전체 인터넷의 약 90~95% 가 딥웹입니다. 다크웹(Dark Web) 은 딥웹의 극히 일부로, Tor6 같은 특수 브라우저로만 접속 가능한 익명 네트워크입니다. 딥웹 자체는 위험한 것이 아닙니다 — 여러분의 이메일도 딥웹이니까요.
치킨집 검색 결과가 나왔습니다. 메뉴, 리뷰, 가격, 배달 예상 시간 — 화면에 보이는 이 정보들은 어디에 저장되어 있을까요? 수천만 사용자가 동시에 접속해도 데이터가 뒤섞이지 않는 이유는 무엇일까요?
-
PageRank: 래리 페이지(Larry Page)의 이름을 딴 알고리즘. “Page“는 웹페이지와 발명자의 이름을 동시에 의미하는 절묘한 이중 의미를 가진다. ↩
-
자료구조(Data Structure): 데이터를 효율적으로 저장하고 검색하기 위한 조직 방식. 사전의 가나다순 정렬, 도서관의 분류 체계 같은 것이 현실 세계의 자료구조다. ↩
-
SEO(Search Engine Optimization): 검색 엔진 최적화. 웹사이트가 검색 결과에서 더 높은 순위에 나오도록 개선하는 작업. ↩
-
구글 판다 업데이트 (2011). 저품질 콘텐츠 필터링. — Google Search Central Blog ↩
-
구글 펭귄 업데이트 (2012). 부정 링크 조작 감지. — Google Search Central Blog ↩
-
Tor(The Onion Router): 양파 라우터. 데이터를 여러 겹의 암호화로 감싸서 전송하는 익명 네트워크. 양파 껍질처럼 중간 단계마다 한 겹씩 벗겨지며, 최종 목적지만 전체 내용을 볼 수 있다. 이 기술을 기반으로 만들어진 “토르 브라우저(Tor Browser)“가 널리 알려져 있다. ↩