프롤로그: 치킨 한 마리 시키는 데 노벨상 수상자가 몇 명 필요할까?
금요일 저녁 9시. 소파에 누워 스마트폰을 꺼냅니다.
배달앱을 열고, “치킨“을 검색합니다. 몇 개의 가게를 둘러보고, 리뷰를 확인하고, 양념 반 후라이드 반을 장바구니에 담습니다. 결제 버튼을 누릅니다. “주문이 완료되었습니다.” 화면에 배달원의 위치가 실시간으로 찍힙니다. 30분 뒤, 초인종이 울립니다.
치킨이 도착했습니다.
이 과정에서 여러분이 한 일은 고작 화면을 몇 번 터치한 것뿐입니다. 하지만 그 몇 번의 터치가 만들어낸 여정은 놀랍도록 길고, 놀랍도록 복잡합니다.
여러분의 손가락이 화면에 닿는 순간, 유리판 아래 센서가 피부의 미세한 전기를 감지합니다. 그 신호는 운영체제에게 전달되고, 운영체제는 수십 개의 앱 중에서 정확히 여러분이 터치한 앱을 1초도 안 되어 실행시킵니다.
“치킨“이라는 글자를 입력하면, 이 데이터는 전파를 타고 스마트폰 밖으로 나갑니다. WiFi 공유기를 지나 광케이블을 타고, 때로는 해저케이블을 건너 수천 킬로미터를 이동합니다. 도착지는 어딘가의 데이터센터 — “클라우드“라는 멋진 이름으로 불리지만, 실체는 축구장만 한 건물 안에 빼곡히 들어찬 서버 수만 대입니다.
서버에 도착한 요청은 DNS라는 주소록을 뒤져 목적지를 찾고, TCP라는 프로토콜로 데이터가 빠짐없이 도착했는지 확인합니다. 검색 엔진이 수십만 개의 치킨집 중에서 여러분의 위치, 평점, 취향을 고려해 결과를 정렬합니다. 그 뒤에는 데이터베이스가 메뉴, 가격, 리뷰를 순식간에 꺼내놓습니다.
결제 버튼을 누르면, 여러분의 카드 정보는 수학적으로 암호화되어 인터넷을 건넙니다. 서비스는 여러분의 비밀번호를 저장하지 않고도 — 정확히는 저장할 수 없는 방식으로 — 여러분이 본인임을 확인합니다. 그리고 GPS 위성 4개가 배달원의 위치를 잡아내고, 경로 탐색 알고리즘이 최적의 길을 계산합니다. 다음번에 앱을 열면, 추천 알고리즘이 “이 치킨집은 어떠세요?“라고 물어올 겁니다. 여러분의 주문 패턴을 학습한 인공지능이 말입니다.
이 모든 일이 치킨 한 마리 시키는 10분 안에 벌어집니다.
여기에 동원되는 기술의 뿌리를 거슬러 올라가면, 노벨상 수상자가 줄줄이 등장합니다.
이 모든 것을 가능하게 한 트랜지스터를 발명한 쇼클리, 바딘, 브래튼은 1956년 노벨 물리학상을 받았습니다.1 광섬유 통신으로 2009년 노벨 물리학상을 받은 찰스 카오가 없었다면 치킨 사진 한 장이 바다를 건너는 데 몇 시간이 걸렸을 것입니다. GPS가 정확하려면 아인슈타인의 상대성이론으로 시간을 보정해야 합니다. 터치스크린의 원리인 정전용량은 19세기 패러데이의 전자기 연구까지 거슬러 올라갑니다.
치킨 한 마리 시키는 데 노벨상 수상자가 최소 대여섯 명은 필요한 셈입니다.
이 책은 여러분이 치킨을 시키는 10분 동안 벌어지는 일을 추적합니다. 손가락이 화면에 닿는 순간부터, 바다 밑 케이블을 건너고, 암호를 풀고, 위성의 도움을 받아 치킨이 문 앞에 도착하기까지.
이 정도 기술이 동원되는 일을 우리는 소파에 누워서 합니다. 매일, 대단한 일인 줄도 모르고.
그 첫 번째 장면으로 가보겠습니다. 여러분의 손가락이 유리판에 닿는 바로 그 순간입니다.
-
윌리엄 쇼클리, 존 바딘, 월터 브래튼. 반도체 연구와 트랜지스터 효과 발견으로 1956년 노벨 물리학상 공동 수상. — NobelPrize.org ↩
1장. 유리판이 내 손가락을 아는 법
“터치스크린, 디스플레이, 그리고 빛의 삼원색”
이번 장에서 알게 될 것
- 장갑을 끼면 왜 터치가 안 되는지
- OLED 폰과 LCD 폰의 “검은 화면“이 다른 이유
- 화면을 확대하면 보이는 빨강, 초록, 파랑 점의 정체
- 120Hz 주사율이 정확히 무엇을 의미하는지
치킨 주문 여정: 시작
소파에서 스마트폰을 집어 들었습니다. 화면에 손가락을 갖다 댑니다. 잠금이 풀리고, 배달앱 아이콘을 누릅니다. 이 당연한 동작 — 정확히 어떻게 작동하는 걸까요?
장갑 끼면 왜 터치가 안 될까?
겨울에 장갑을 끼고 스마트폰을 쓰려다 포기한 경험, 한 번쯤 있을 겁니다. 그런데 이상한 점이 있습니다. 얇은 비닐장갑은 되는데, 두꺼운 가죽장갑은 안 됩니다. 소시지로 터치하면 된다는 이야기도 돌았습니다. 실제로 됩니다.
왜 그럴까요?
답은 스마트폰 화면이 힘이 아니라 전기를 감지하기 때문입니다.
정전식 터치스크린의 원리
스마트폰 화면의 유리 아래에는 눈에 보이지 않는 전극 격자가 깔려 있습니다. 이 전극에는 미세한 전기장이 형성되어 있습니다. 핵심은 이겁니다 — 사람의 몸은 전기를 담을 수 있는 도체입니다. 우리 몸의 약 60%는 물이고, 그 물에는 이온이 녹아 있습니다.
손가락이 화면에 닿으면, 그 지점의 전기장이 미세하게 변합니다. 전극의 전하 일부가 도체인 손가락 쪽으로 빨려 들어가는 겁니다. 이 변화를 정전용량(Capacitance) 의 변화라고 합니다. 화면 아래의 컨트롤러가 이 변화를 감지해서 “아, 여기를 터치했구나“라고 판단합니다.
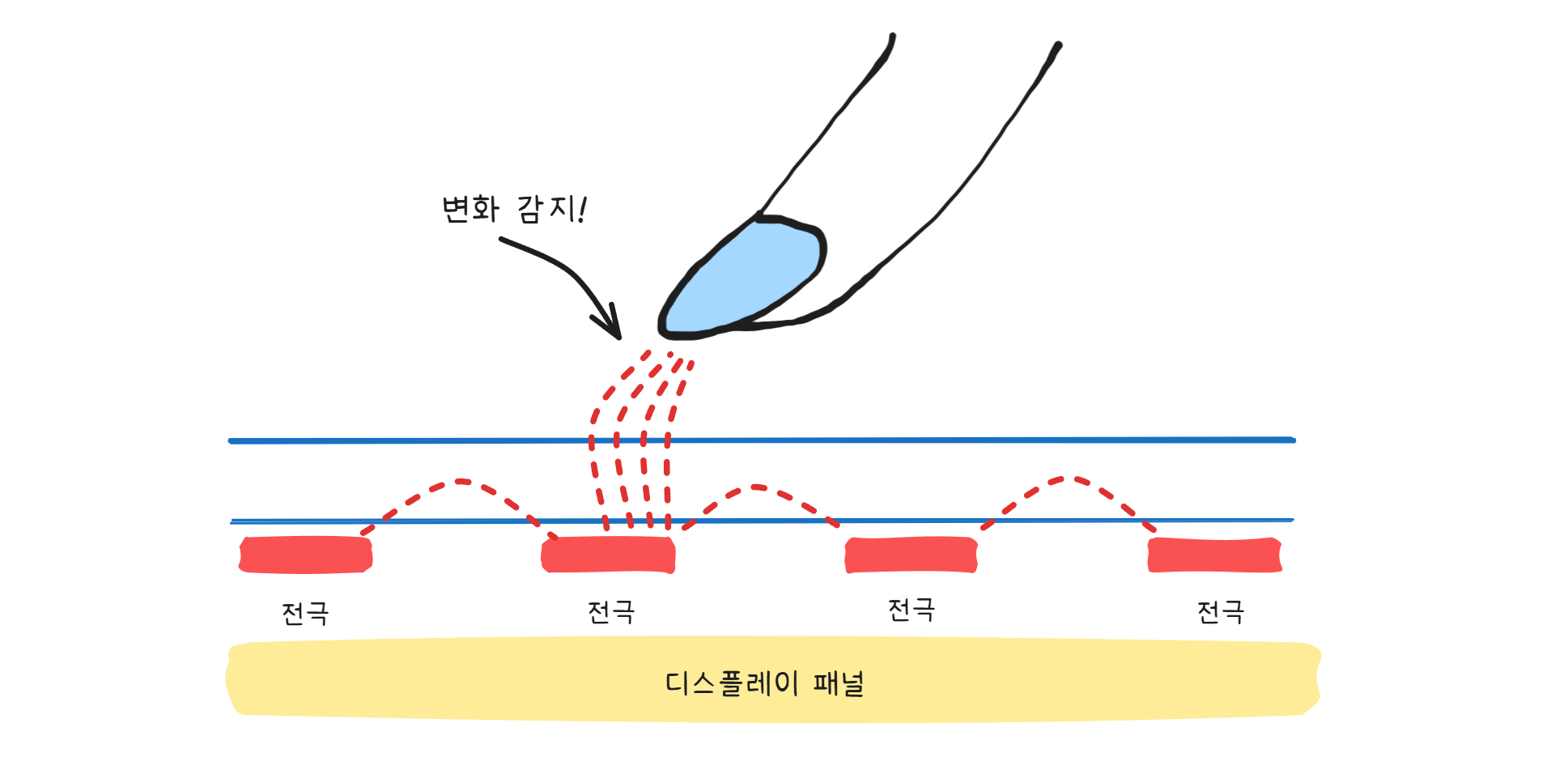
그래서 장갑의 수수께끼가 풀립니다.
- 맨손: 도체인 피부가 직접 닿으니 정전용량이 변합니다. 당연히 됩니다.
- 얇은 비닐장갑: 너무 얇아서 전기장이 관통합니다. 됩니다.
- 두꺼운 가죽장갑: 절연체가 두꺼워 전기장이 차단됩니다. 안 됩니다.
- 소시지: 수분과 이온이 풍부한 도체입니다. 됩니다.
- 터치 장갑: 손가락 끝에 전도성 실을 짜 넣어 전기가 통하게 만든 것입니다.
여기서 재밌는 사실이 있습니다. 이 방식을 정전식(Capacitive) 터치라고 합니다. 예전 ATM이나 키오스크에 쓰이던 감압식(Resistive) 터치와는 완전히 다릅니다. 감압식은 말 그대로 “누르는 힘“을 감지합니다. 그래서 손톱이든, 볼펜이든, 뭘로 눌러도 동작했습니다. 대신 반응이 둔하고, 멀티터치가 안 됐습니다. 닌텐도 DS의 터치스크린이 감압식이었습니다 — 작은 플라스틱 펜(스타일러스)으로 꾹꾹 눌러서 쓰는 방식이었죠.
스마트폰이 두 손가락으로 사진을 확대하고 줄이는 동작 — 핀치 투 줌(Pinch to Zoom) — 을 할 수 있는 건, 정전식이 여러 지점의 정전용량 변화를 동시에 감지할 수 있기 때문입니다.
화면은 어떻게 빛을 만드는가
손가락이 닿았다는 것은 알았습니다. 그런데 그 아래의 화면은 어떻게 글자와 이미지를 보여주고 있는 걸까요?
OLED vs LCD: “검은 화면“의 차이
어두운 방에서 스마트폰 화면을 완전히 검은색으로 만들어 보겠습니다. 폰 기종에 따라 두 가지 중 하나가 보일 겁니다.
- 진짜 검은 화면 — 화면과 베젤1의 경계가 보이지 않습니다. 꺼진 것처럼 보입니다.
- 회색빛 도는 검은 화면 — 어두운 방에서 보면 화면 전체가 은은하게 빛납니다.
1번이 OLED, 2번이 LCD입니다.
이유는 단순합니다. 빛을 만드는 방식이 근본적으로 다르기 때문입니다.
LCD(Liquid Crystal Display) 는 화면 뒤에 커다란 백라이트가 있습니다. 이 백라이트는 항상 켜져 있고, 액정이 빛을 통과시키거나 막아서 이미지를 만듭니다. 문제는 “막는다“고 해도 빛이 완전히 차단되지 않는다는 것입니다. 그래서 검은색을 표현해도 빛이 살짝 새어 나옵니다.
OLED(Organic Light-Emitting Diode) 는 완전히 다른 접근입니다. 백라이트가 없습니다. 화소 하나하나가 스스로 빛을 냅니다. 검은색을 표현할 때는? 해당 화소를 그냥 끕니다. 빛이 없으니 진짜 검은색입니다.
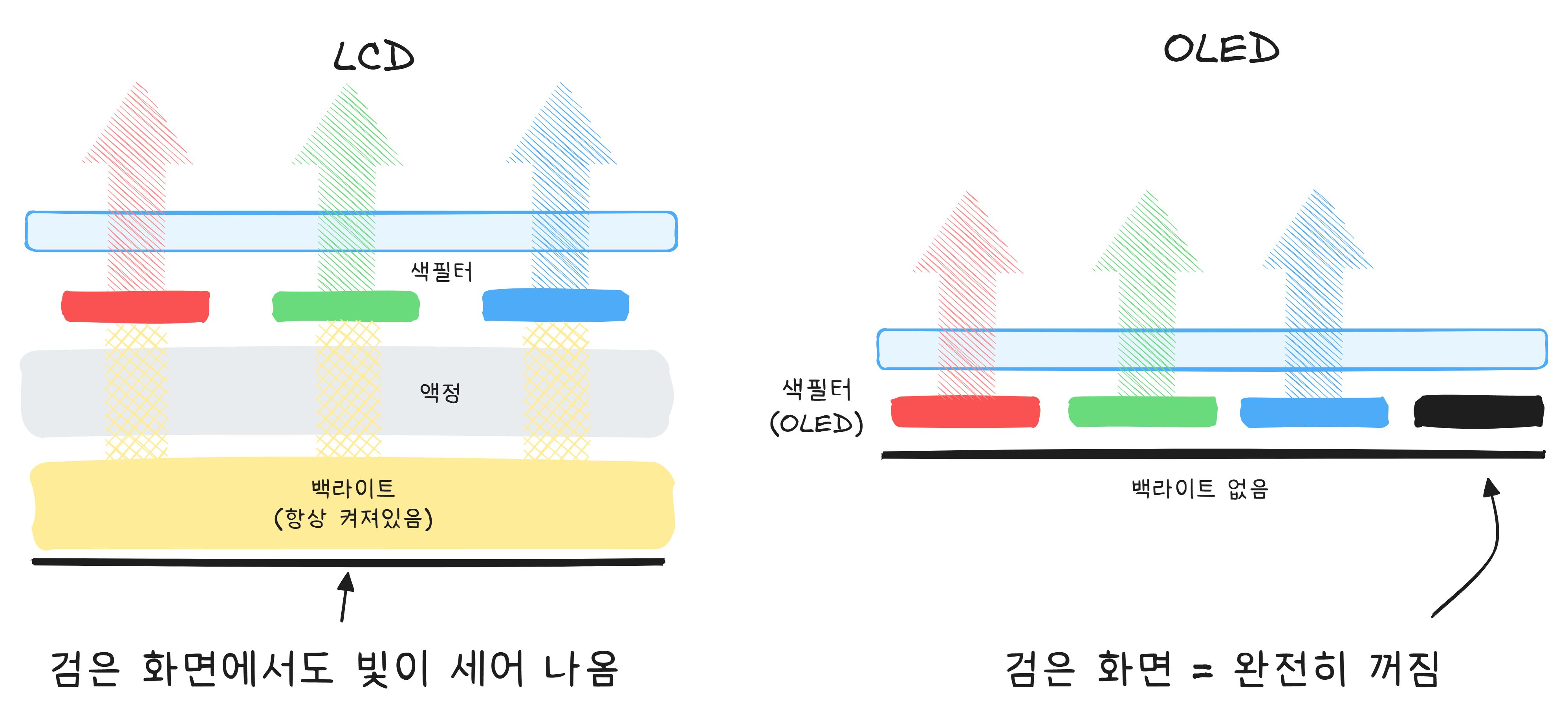
OLED에는 LCD가 할 수 없는 것이 하나 더 있습니다. 휘어집니다. LCD는 단단한 백라이트와 유리 기판이 필요하지만, OLED는 유기물 필름 위에 발광층을 쌓는 구조여서 구부릴 수 있습니다. 폴더블 폰이 반으로 접힐 수 있는 이유가 바로 이것입니다. 화면 가장자리가 옆면까지 휘어져 내려오는 “엣지 디스플레이“도 같은 원리입니다.
시계나 알림을 화면이 꺼진 상태에서도 보여주는 AOD(Always-On Display) 기능도 OLED이기에 가능합니다. 필요한 화소 몇 개만 켜고 나머지는 완전히 꺼두면 되니까요. LCD는 화소 하나만 켜려 해도 백라이트 전체를 켜야 해서, 이 기능을 쓰면 배터리가 급격히 줄어듭니다.
같은 원리로 다크 모드가 OLED 폰에서 배터리를 절약합니다. 화면의 넓은 영역이 검은색 — 즉, 꺼진 화소 — 이니까요. 반면 LCD에서는 다크 모드를 켜도 백라이트가 여전히 켜져 있으므로 배터리 차이가 거의 없습니다. “다크 모드가 배터리를 아낀다“는 말은 OLED 폰에서만 사실인 셈입니다.
물론 OLED에 단점이 없는 건 아닙니다. 유기물이 시간이 지나면 열화되는데, 색상별로 수명이 다릅니다. 파란색 화소가 가장 빨리 닳습니다. 같은 이미지를 오래 표시하면 그 부분만 눌러 앉는 번인(Burn-in) 현상이 생기는 것도 이 때문입니다. 화면 상단의 상태 바나, 항상 같은 위치에 있는 내비게이션 버튼 자국이 남는 경우가 바로 그것입니다.
빨강, 초록, 파랑 — 세 개의 점
OLED든 LCD든, 화면을 아주 가까이 — 돋보기가 있다면 더 좋습니다 — 들여다보면 놀라운 것이 보입니다. 모든 색이 딱 세 가지 빛의 조합으로 만들어지고 있습니다.
빨강(Red), 초록(Green), 파랑(Blue).
이 세 가지를 RGB 서브픽셀이라고 합니다. 하나의 점(픽셀)은 이 세 가지 서브픽셀로 구성됩니다.
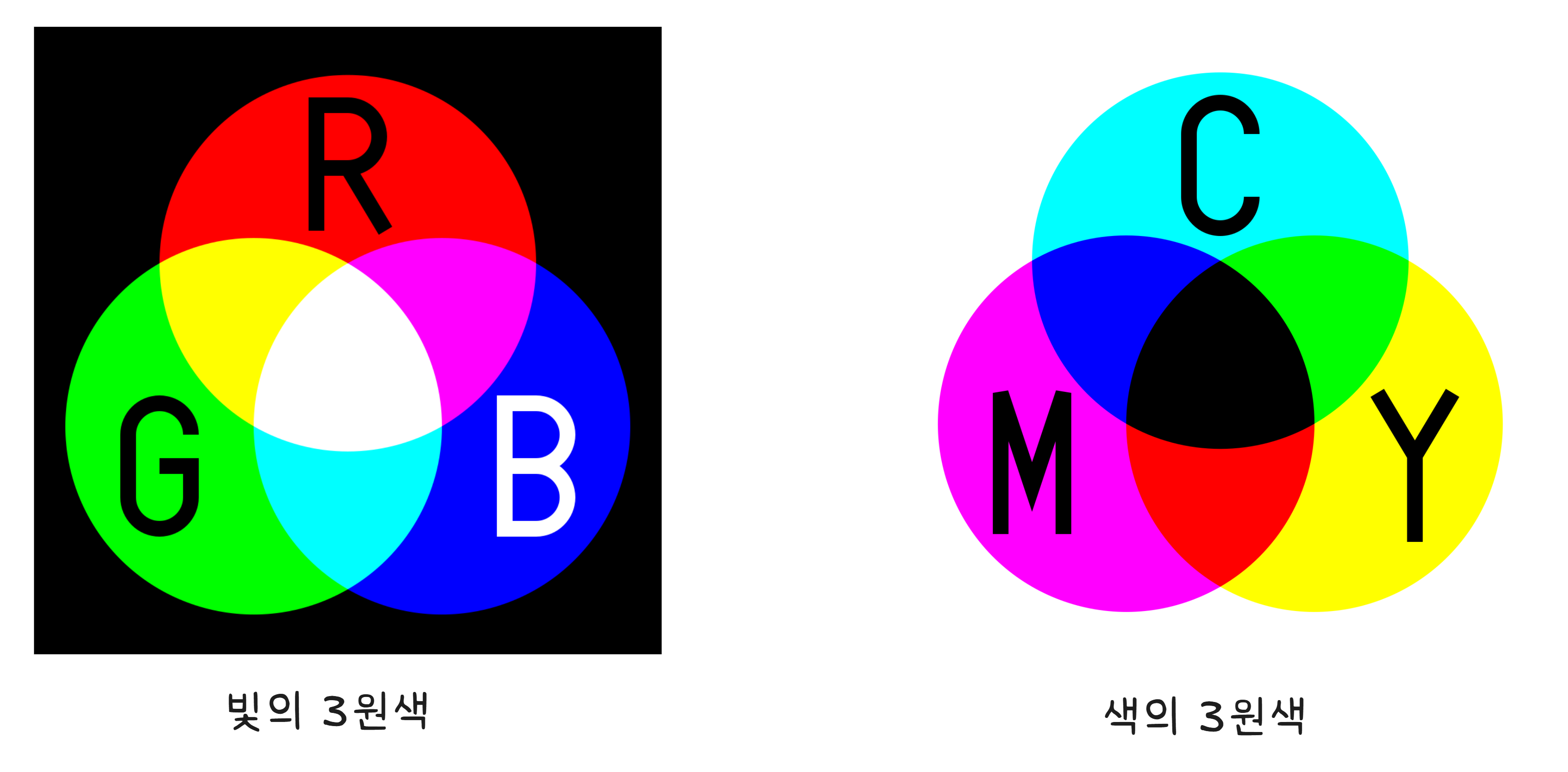
빛의 삼원색입니다.2 물감의 삼원색(빨강, 노랑, 파랑)과 다릅니다. 물감은 섞을수록 어두워지지만(감산 혼합), 빛은 섞을수록 밝아집니다(가산 혼합). TV, 모니터, 스마트폰 — 빛을 내는 모든 화면은 이 원리로 동작합니다.
해상도와 PPI
그렇다면 이 픽셀이 얼마나 촘촘하게 들어차 있는가 — 이것이 해상도입니다.
“Full HD“라고 하면 가로 1,920개, 세로 1,080개의 픽셀이 있다는 뜻입니다. 총 약 207만 개. 요즘 스마트폰은 이보다 더 많은 픽셀을 6인치 남짓한 화면에 우겨넣습니다.
같은 픽셀 수라도 화면 크기가 다르면 선명도가 달라집니다. 이걸 측정하는 단위가 PPI(Pixels Per Inch) — 1인치에 들어가는 픽셀 수입니다. 65인치 TV와 6인치 스마트폰이 같은 해상도라면, 스마트폰의 PPI가 10배 이상 높습니다. 그래서 스마트폰 화면을 코앞에 갖다 대도 픽셀이 잘 보이지 않습니다.
유튜브에서 해상도를 360p로 낮추면 뿌옇게 보이는 이유도 이것입니다. 고밀도 화면에 적은 수의 픽셀을 억지로 늘려 채우니, 점 하나하나가 눈에 보일 만큼 커지면서 경계가 뭉개지는 겁니다. 반대로, 같은 영상을 작은 화면에서 보면 훨씬 선명하게 보입니다.
1초에 120번 다시 그린다
화면에 보이는 이미지는 정지해 있는 것처럼 보이지만, 사실은 끊임없이 다시 그려지고 있습니다.
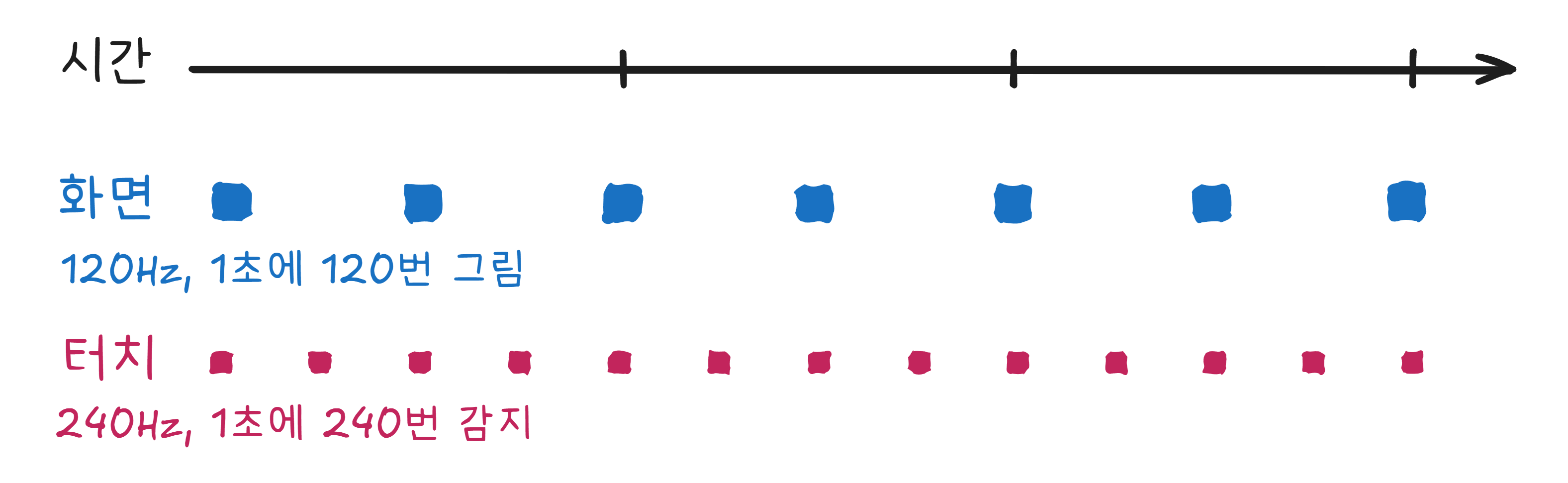
주사율(Refresh Rate) 이 60Hz라는 것은, 화면이 1초에 60번 새로 그려진다는 뜻입니다. 120Hz면 120번. 우리 눈이 이걸 인식하지 못할 만큼 빠르기 때문에 정지 화면처럼 보이는 것뿐입니다.
영화가 24프레임인 것은 유명합니다. 1초에 24장의 사진을 빠르게 넘기면 움직이는 것처럼 보입니다. 스마트폰은 이것의 5배 속도로 화면을 갱신하고 있는 겁니다.
그런데 60Hz와 120Hz의 차이를 실제로 느낄 수 있을까요? 웹 서핑이나 영상 시청에서는 거의 차이가 없습니다. 하지만 손가락으로 화면을 빠르게 스크롤할 때 — 배달앱에서 치킨집 목록을 훑어 내릴 때 — 차이가 드러납니다. 60Hz에서는 글자가 미세하게 끊기지만, 120Hz에서는 물 흐르듯 부드럽게 따라옵니다. 게임에서는 그 차이가 더 극적입니다.
헷갈리기 쉬운 것이 하나 있습니다. 스마트폰 스펙에 “터치 샘플링 레이트 240Hz“라고 적혀 있는 걸 본 적 있을 겁니다. 이건 주사율과 다른 개념입니다. 주사율은 화면이 그림을 다시 그리는 속도이고, 터치 샘플링 레이트는 화면이 손가락의 위치를 확인하는 속도입니다. 화면은 1초에 120번 그리지만, 터치 위치는 240번 감지합니다. 그래서 빠르게 손가락을 움직여도 지연 없이 따라오는 것처럼 느껴집니다.
최근에는 가변 주사율 기술도 쓰입니다. 화면에 변화가 없을 때는 주사율을 10Hz, 심지어 1Hz까지 낮추고, 스크롤하는 순간 120Hz로 올립니다. 시계만 띄워놓은 화면을 1초에 120번 다시 그릴 이유가 없으니까요. 이 기술 덕분에 120Hz 폰도 배터리를 크게 잡아먹지 않게 되었습니다.
사건: 갤럭시 노트7, “작게 만들기“의 대가
2016년 8월, 삼성 갤럭시 노트7이 출시됩니다.
출시 직후부터 전 세계에서 배터리 폭발 사고가 보고되기 시작합니다. 충전 중에 타는 것은 물론, 주머니에서, 비행기 안에서, 심지어 어린이 손에서 폰이 불을 뿜었습니다. 삼성은 리콜을 진행하고 교환폰을 보냈지만, 교환폰마저 폭발합니다.
결국 미국 교통부(DOT)와 연방항공청(FAA)은 모든 항공편에서 갤럭시 노트7의 반입을 금지합니다.3 비행기 탑승 전 “갤럭시 노트7을 소지하고 계신 분은 전원을 끄고 신고해 주십시오“라는 안내 방송이 나왔습니다. 삼성은 전량 리콜 후 단종을 결정합니다. 출시부터 단종까지 단 두 달. 피해액은 삼성 공식 추산 약 6조 원.
원인은 무엇이었을까요?
배터리를 더 얇은 본체에 넣기 위해 양극과 음극 사이의 간격을 극한까지 줄인 것이 문제였습니다. 일부 배터리에서는 제조 과정의 미세한 결함으로 양극과 음극이 접촉하면서 단락(Short Circuit)이 발생했습니다. 단락이 일어나면 에너지가 한꺼번에 방출되면서 열이 폭주하고 — 발화합니다.
더 얇게, 더 가볍게, 더 많은 배터리 용량을. 스마트폰의 모든 부품이 밀리미터 단위로 최적화되어 있다는 것의 이면입니다.
알쓸신잡
-
비행기에서 터치가 오작동하는 이유: 기내 기압이 낮아지면 공기가 건조해지고, 피부 표면의 수분이 줄어듭니다. 정전식 터치는 피부의 전기적 특성에 의존하기 때문에, 건조한 환경에서 감도가 떨어질 수 있습니다. 비 오는 날 화면에 물방울이 떨어지면 오작동하는 것도 같은 원리의 반대 방향입니다 — 물도 도체이기 때문에 손가락이 아닌 곳에서 정전용량 변화가 생기는 겁니다.
-
“레티나 디스플레이“의 유래: 2010년, 스티브 잡스가 아이폰 4를 발표하면서 “레티나 디스플레이“라는 이름을 붙였습니다. “일반적인 시청 거리에서 사람의 망막(Retina)이 픽셀을 구분할 수 없는 밀도“라는 뜻이었습니다. 당시 326PPI. 기술적 공식 용어가 아니라 마케팅 용어였지만, 고해상도 디스플레이 경쟁에 불을 붙인 이름이 되었습니다.
-
최초의 터치스크린은 언제?: 정전식 터치스크린의 역사는 스마트폰보다 훨씬 오래되었습니다. 1965년, 영국 왕립 레이더 연구소의 E.A. 존슨이 항공 관제 시스템을 위해 최초의 정전식 터치스크린을 개발했습니다.4 휴대폰에 본격 도입된 것은 2007년입니다. LG 프라다가 최초의 정전식 터치 휴대폰이었고, 같은 해 아이폰이 멀티터치를 앞세워 대중화에 성공했습니다 — 개발부터 상용화까지 42년이 걸린 셈입니다.
터치가 전기 신호가 되었고, 화면은 그 신호를 빛으로 바꿔 보여주고 있습니다. 그런데 이 신호를 받아서 “배달앱을 실행하라“고 판단하는 건 누구일까요? 수십 개의 앱 중에서 정확히 하나를 골라 실행시키고, 화면에 메뉴를 띄우고, 터치할 때마다 반응하게 만드는 — 그 보이지 않는 관리자는 대체 누구일까요?
-
베젤(Bezel): 화면 주위의 테두리. 화면이 아닌 검은 가장자리 부분. ↩
-
그림 출처: Wikimedia Commons (Public Domain) ↩
-
E.A. Johnson, “Touch Display — A Novel Input/Output Device for Computers”, Electronics Letters, 1965. — Wikipedia: Touchscreen ↩
2장. 이 앱은 어떻게 실행되는가
“운영체제, 프로세스, 메모리”
이번 장에서 알게 될 것
- 앱을 많이 켜면 왜 폰이 느려지는지
- CPU가 동시에 여러 일을 하는 것처럼 보이는 비밀
- “앱 강제종료“가 실제로 하는 일
- 2038년에 전 세계 컴퓨터에 닥칠 수 있는 문제
치킨 주문 여정: 앱이 켜진다
화면을 터치했습니다. 전기 신호가 발생했습니다. 그런데 이 신호를 받아서 “배달앱을 열어라“고 판단하는 건 누구일까요? 스마트폰 안에는 보이지 않는 관리자가 있습니다.
앱을 많이 켜면 왜 느려질까?
카카오톡, 유튜브, 배달앱, 브라우저, 음악 앱. 스마트폰에서 앱을 잔뜩 열어두면 점점 느려집니다. 그러다 앱 하나를 다시 열면 처음부터 새로 로딩되기도 합니다. 분명 끄지 않았는데 말입니다.
왜 그럴까요? 이걸 이해하려면, 스마트폰 안에서 벌어지는 두 가지를 알아야 합니다. CPU가 어떻게 일하는지, 그리고 메모리가 어떻게 쓰이는지.
CPU는 한 번에 하나만 한다
스마트폰에서 음악을 틀어놓고, 카카오톡으로 대화하면서, 배달앱을 검색합니다. 세 가지가 동시에 돌아가는 것처럼 보입니다.
사실은 아닙니다.
CPU는 한 순간에 하나의 작업만 처리할 수 있습니다. 그런데 엄청나게 빠르게 작업을 바꿔가면서 처리합니다. 음악 앱에 0.001초, 카카오톡에 0.001초, 배달앱에 0.001초. 이걸 너무 빠르게 반복하니까 우리 눈에는 세 개가 동시에 돌아가는 것처럼 보이는 겁니다.
이 작업 전환을 컨텍스트 스위칭(Context Switching) 이라고 합니다.
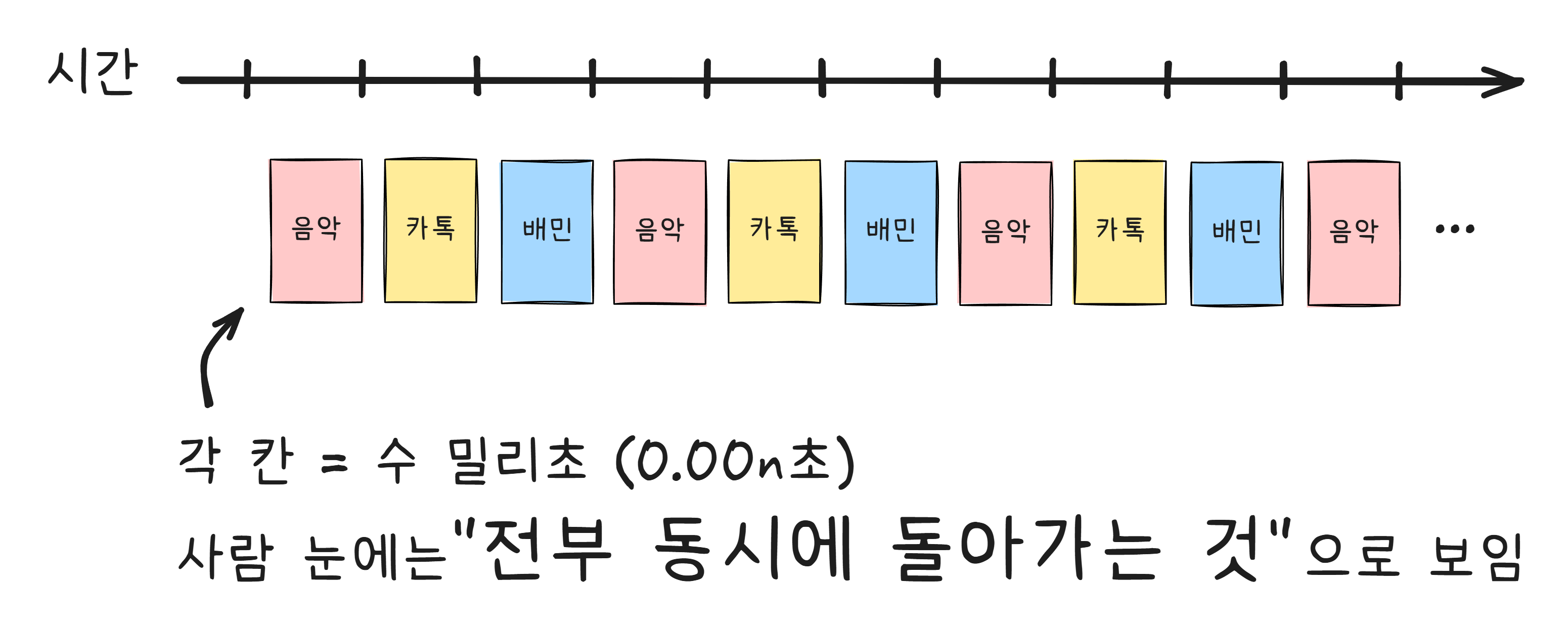
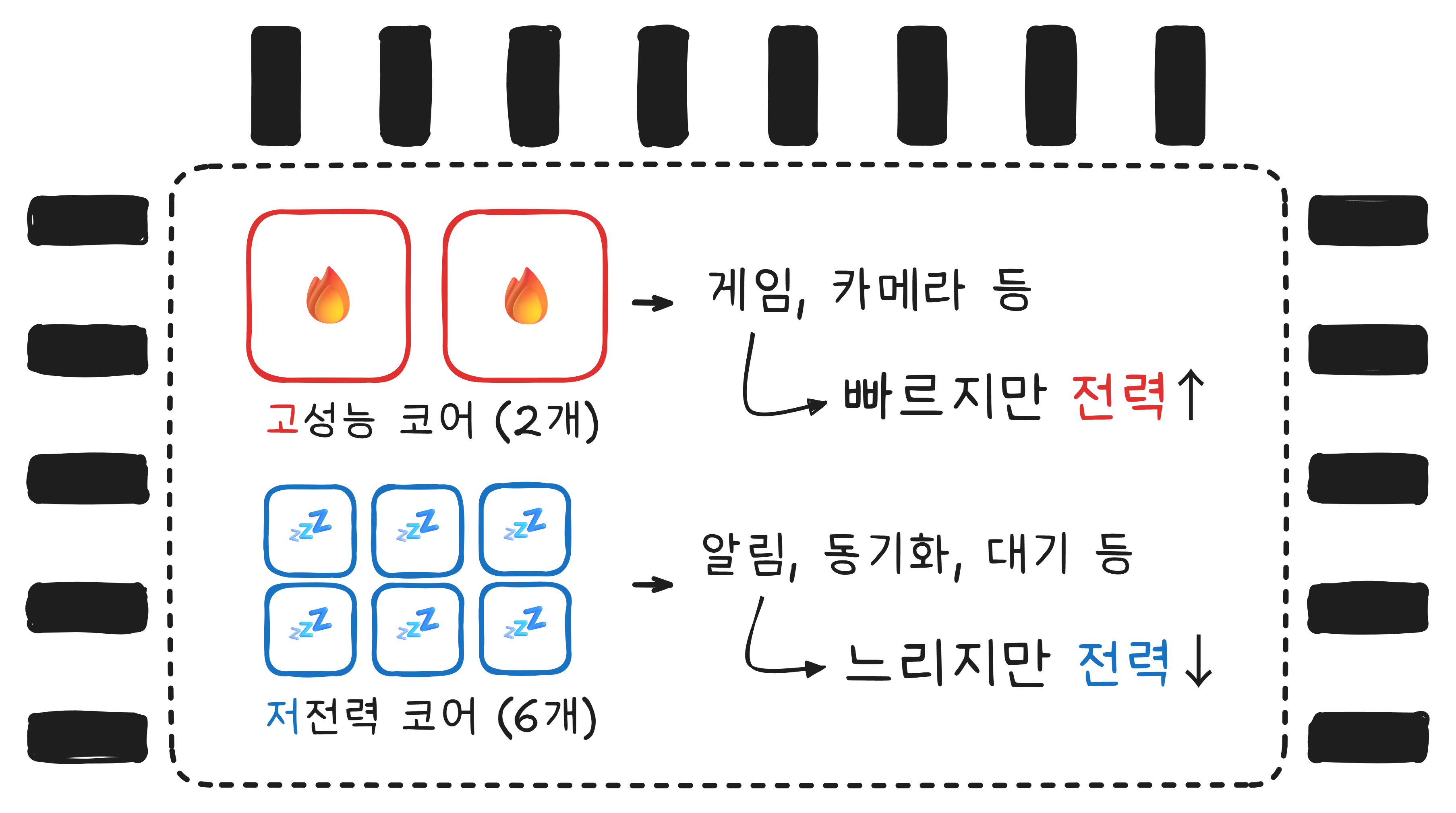
요즘 스마트폰 CPU는 코어가 여러 개입니다. “옥타코어“라는 건 코어가 8개라는 뜻이고, 이 경우 진짜로 8개의 작업을 동시에 처리할 수 있습니다. 하지만 실행 중인 앱과 백그라운드 프로세스를 합치면 수십에서 수백 개에 달하기 때문에, 여전히 컨텍스트 스위칭은 끊임없이 일어납니다.
그런데 이 8개의 코어가 전부 같지는 않습니다. 대부분의 스마트폰은 고성능 코어와 저전력 코어를 섞어서 씁니다. 게임처럼 무거운 작업은 고성능 코어가, 알림 확인이나 시계 표시 같은 가벼운 작업은 저전력 코어가 처리합니다.
왜 이렇게 나눌까요? 전부 고성능 코어로 채우면 배터리가 순식간에 닳기 때문입니다. 실제로 스마트폰이 하는 일의 대부분은 가벼운 작업입니다. 메시지 수신 대기, 화면 갱신, 백그라운드 동기화. 이런 일에 고성능 코어를 깨우는 건, 편의점에 우유 하나 사러 가는데 대형 트럭을 모는 것과 같습니다.
RAM은 책상이다
CPU가 일하는 속도를 이해했으니, 이번에는 공간 이야기입니다.
비유를 하나 들어보겠습니다. 여러분이 공부를 한다고 합시다.
- 책상 위에는 지금 보고 있는 교재, 노트, 필기구가 올라와 있습니다. 손만 뻗으면 바로 씁니다.
- 서랍장 에는 나머지 책들이 들어 있습니다. 필요하면 꺼내와야 합니다. 시간이 좀 걸립니다.
스마트폰에서 RAM이 책상이고, 저장장치(SSD/Flash) 가 서랍장입니다.
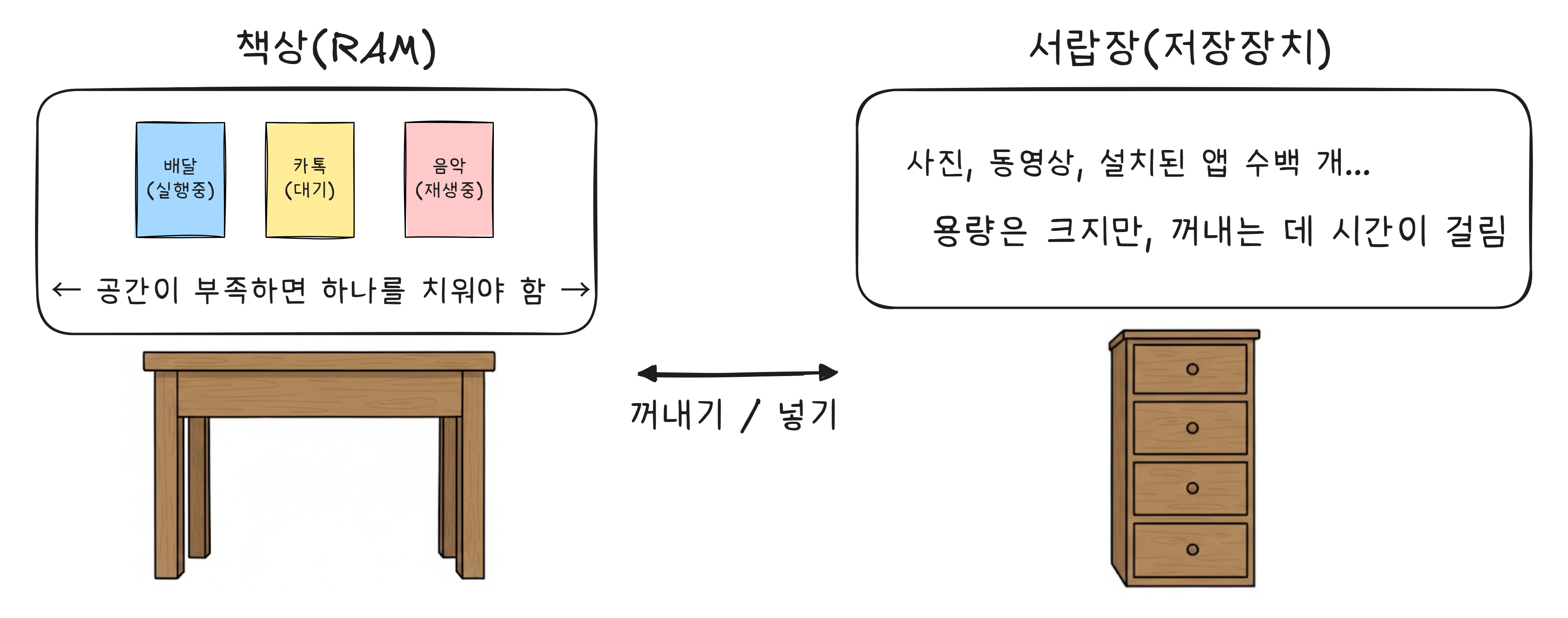
앱을 여는 것은 서랍에서 교재를 꺼내 책상 위에 올리는 것과 같습니다. 앱이 RAM에 올라와야 CPU가 처리할 수 있습니다.
문제는 책상 크기에 한계가 있다는 겁니다. RAM이 8GB인 폰에서 앱을 20개 열면, 책상이 꽉 찹니다. 그러면 운영체제는 가장 오래 안 쓴 앱을 책상에서 치웁니다 — 서랍에 다시 넣는 겁니다. 나중에 그 앱을 다시 열면 서랍에서 꺼내와야 하니까, 처음부터 새로 로딩되는 것입니다.
“앱을 많이 켜면 느려진다“의 정체가 이겁니다. CPU가 느려지는 게 아니라, RAM이 부족해서 앱을 내렸다 올렸다 반복하느라 느려지는 것입니다.
운영체제: 보이지 않는 총 관리자
그렇다면 어떤 앱을 RAM에 올리고, 어떤 앱을 내릴지 결정하는 건 누구일까요? CPU 시간을 어떤 앱에 얼마나 배분할지 정하는 건?
운영체제(Operating System, OS) 입니다.
안드로이드, iOS, 윈도우, 맥OS — 이것들이 전부 운영체제입니다. 운영체제가 하는 일을 한마디로 요약하면 이렇습니다.
하드웨어와 앱 사이의 통역
앱은 하드웨어를 직접 제어하지 않습니다. “화면에 빨간 버튼을 그려라”, “스피커에서 소리를 내라”, “인터넷에 데이터를 보내라” — 이런 요청을 운영체제에게 합니다. 운영체제가 대신 하드웨어에 명령을 내립니다.
이렇게 하는 이유는 안전 때문입니다. 앱 하나가 하드웨어를 마음대로 조작할 수 있으면, 다른 앱의 데이터를 읽거나, 시스템 전체를 망가뜨릴 수 있습니다. 운영체제는 각 앱에게 허용된 범위만 쓰게 합니다. “카메라 접근을 허용하시겠습니까?” 같은 팝업이 뜨는 것도 이 때문입니다.
전원 버튼을 누르면 무슨 일이 벌어질까
운영체제가 모든 것을 관리한다면, 운영체제 자체는 누가 실행시킬까요?
전원 버튼을 누르면 가장 먼저 실행되는 것은 운영체제가 아닙니다. 칩에 내장된 아주 작은 프로그램 — 부트로더(Bootloader) — 가 먼저 깨어납니다. 부트로더는 하드웨어가 정상인지 간단히 확인한 뒤, 저장장치에서 운영체제를 찾아 RAM에 올립니다. 그제서야 운영체제가 주도권을 잡고 나머지를 실행합니다.
이 과정이 부팅(Booting) 입니다. 컴퓨터를 켤 때마다 로고가 뜨면서 잠시 기다리는 시간 — 그게 운영체제가 저장장치에서 RAM으로 올라오는 시간입니다. SSD가 빠른 컴퓨터에서 부팅이 빠른 이유도, 서랍(저장장치)에서 책상(RAM)으로 꺼내오는 속도가 빠르기 때문입니다.
프로세스: 실행 중인 앱의 진짜 이름
앱 아이콘을 누르면 “프로그램“이 실행됩니다. 이 실행 중인 프로그램을 프로세스(Process) 라고 합니다.
프로그램과 프로세스의 차이는 이렇습니다. 프로그램은 저장장치에 저장된 파일입니다 — 서랍 속의 교재입니다. 프로세스는 그 프로그램이 RAM에 올라와 실행되고 있는 상태입니다 — 책상 위에 펼쳐진 교재입니다. 같은 프로그램을 두 번 실행하면 프로세스가 2개 생깁니다.
“앱 강제종료“가 하는 일이 바로 이 프로세스를 죽이는(kill) 것입니다. RAM에서 해당 앱의 흔적을 완전히 지워버립니다. 책상 위의 교재를 덮어서 서랍에 집어넣는 게 아니라, 아예 책상 밖으로 치워버리는 겁니다.
가비지 컬렉션: 메모리 청소부
앱이 실행되면서 RAM에는 온갖 데이터가 쌓입니다. 이미지, 텍스트, 변수, 임시 계산 결과. 그런데 이 중 일부는 더 이상 필요 없어집니다. 이전 화면의 데이터, 이미 처리된 네트워크 응답 같은 것들입니다.
이 쓸모없어진 데이터를 자동으로 찾아서 치워주는 것이 가비지 컬렉션(Garbage Collection) 입니다. 말 그대로 쓰레기 수거입니다.
책상 위에 쓰다 만 메모지, 다 마신 커피잔이 쌓이면 공간이 부족해지는 것처럼, RAM에도 안 쓰는 데이터가 계속 쌓이면 공간이 모자라집니다. 가비지 컬렉션이 주기적으로 돌면서 “이건 아직 쓰이나? 이건?” 확인하고, 안 쓰이는 것을 정리합니다.
이 과정에서 앱이 잠깐 멈추는 경우가 있습니다. 가비지 컬렉션이 돌아가는 동안 앱의 실행이 일시 중단될 수 있기 때문입니다. 스마트폰이 간헐적으로 미세하게 버벅이는 원인 중 하나가 이것입니다.
참고로 모든 프로그래밍 언어에 가비지 컬렉션이 있는 것은 아닙니다. C나 C++ 같은 언어는 프로그래머가 직접 메모리를 관리합니다. 책상 위를 누가 치워주는 게 아니라, 본인이 알아서 정리해야 하는 겁니다. 실수로 안 치우면 메모리가 새는 메모리 누수(Memory Leak) 가 발생하고, 이미 치운 것을 또 치우려 하면 프로그램이 죽습니다. 자유가 큰 대신 위험도 큰 방식입니다.
사건: 1970년 1월 1일로 시간을 돌리면
2016년 2월, 아이폰 사용자들 사이에 소문이 돌았습니다.1
“날짜를 1970년 1월 1일로 설정하면 특별한 이스터에그가 나온다.”
이스터에그는 없었습니다. 대신 폰이 벽돌이 되었습니다. 전원을 꺼도, 다시 켜도, 아무것도 할 수 없는 상태. 복구하려면 애플 서비스 센터에 가야 했습니다.
왜 하필 1970년 1월 1일일까요?
컴퓨터는 시간을 숫자로 저장합니다. 1970년 1월 1일 자정을 기준점으로 삼고, 그 이후 흐른 초(秒) 수를 세는 방식입니다. 이걸 유닉스 시간(Unix Epoch) 이라고 합니다.
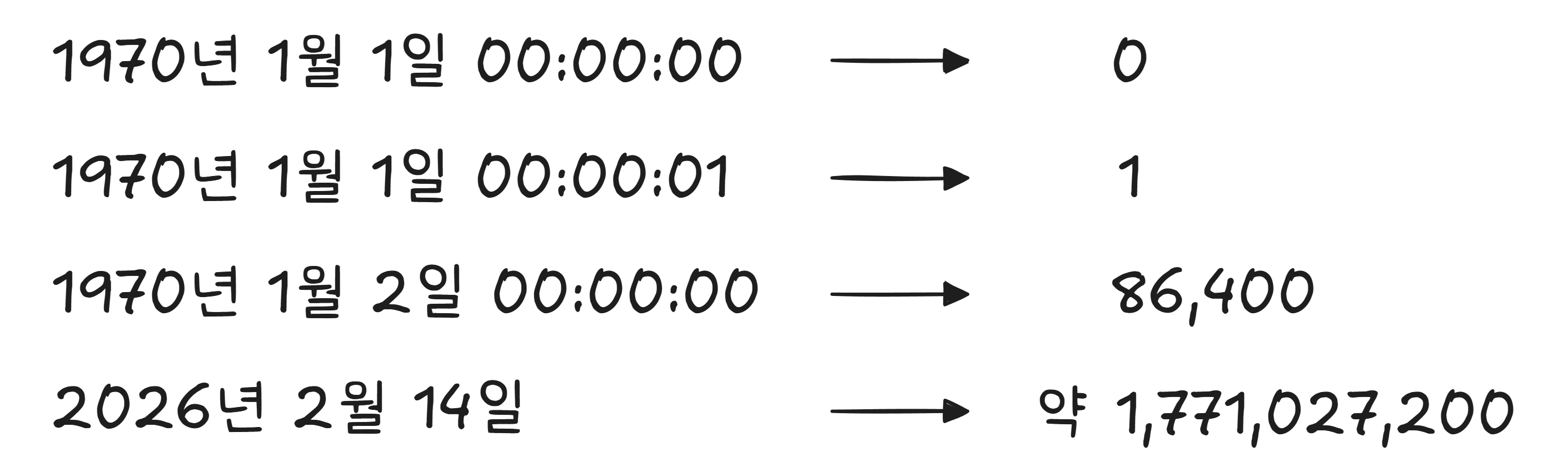
날짜를 1970년 1월 1일로 설정하면 이 값이 0이 됩니다. 문제는 시간대(타임존) 보정 과정에서 이 값이 0 아래로 — 음수로 — 내려갈 수 있다는 것입니다. 한국은 UTC+9이므로, 1970년 1월 1일 0시(한국 시각)는 유닉스 시간으로 -32,400이 됩니다. 시스템이 이 음수를 처리하지 못하면서 계산이 폭주한 것입니다.
이 사건은 “컴퓨터가 시간을 어떻게 다루는가“를 보여주는 사례입니다. 그리고 이 방식에는 유통기한이 있습니다.
2038년 문제
유닉스 시간은 전통적으로 32비트 정수로 저장됩니다. 32비트 정수의 최대값은 2,147,483,647. 이 숫자에 해당하는 날짜가 2038년 1월 19일 03:14:07(UTC) 입니다.
이 시점을 넘어가면? 숫자가 넘쳐서(오버플로) 음수가 됩니다. 컴퓨터가 갑자기 1901년 12월 13일로 되돌아간 것으로 인식할 수 있습니다.2
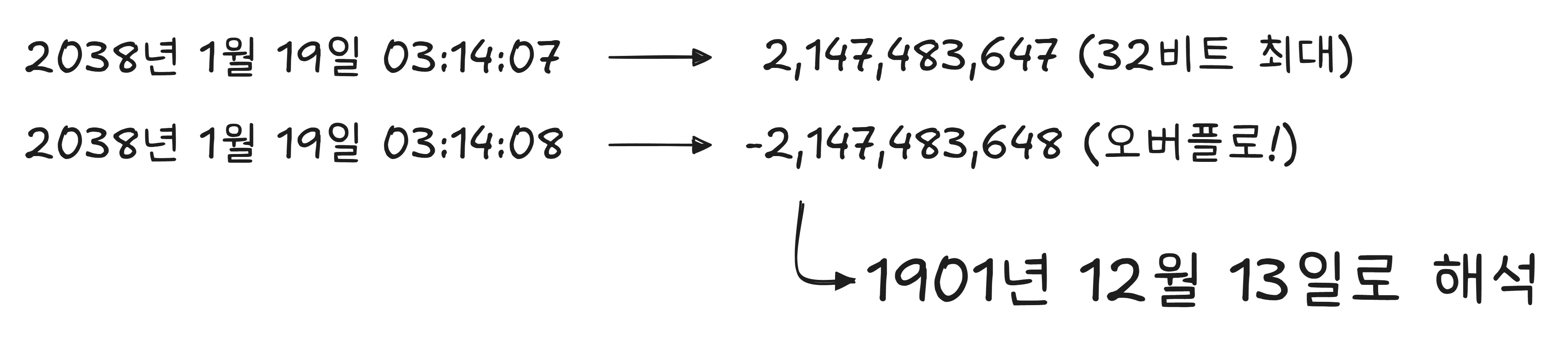
2000년을 앞두고 전 세계가 공포에 떨었던 Y2K 문제의 후속편입니다. Y2K는 연도를 두 자리로 저장해서 생긴 문제였고, 2038년 문제는 시간을 32비트로 저장해서 생기는 문제입니다. 대부분의 현대 시스템은 이미 64비트로 전환했지만, 오래된 임베디드 시스템3 — ATM, 산업용 장비, 자동차 ECU4 — 중에는 아직 32비트를 쓰는 것들이 남아 있습니다.
알쓸신잡
-
왜 컴퓨터는 0부터 셀까?: 프로그래밍에서 배열의 첫 번째 칸은 1번이 아니라 0번입니다. 이건 메모리 주소 계산과 관련이 있습니다. “시작 위치에서 얼마나 떨어져 있는가“를 나타내는 것이기 때문에, 첫 번째 칸은 시작 위치에서 0만큼 떨어진 곳 — 0번입니다. 이것 때문에 프로그래머들은 “첫 번째“를 0이라고 부르는 습관이 있습니다. 1월 1일을 “0일“이라고 부르지는 않지만, 엘리베이터 층수는 유럽에서 0층부터 시작합니다.
-
블루스크린(BSOD)의 정체: 윈도우에서 파란 화면에 흰 글씨가 뜨면서 컴퓨터가 멈추는 현상. 정식 명칭은 “Blue Screen of Death”. 운영체제가 더 이상 안전하게 실행할 수 없는 오류를 만났을 때 나타납니다. “이대로 계속 실행하면 데이터가 망가질 수 있으니, 차라리 멈추겠다“는 운영체제의 판단입니다. 2024년 CrowdStrike 사태 때 전 세계 공항, 병원, 은행의 윈도우 컴퓨터에 이 파란 화면이 동시에 떴습니다. 이 이야기는 3장에서 다시 만납니다.
-
앱 강제종료, 자주 하면 좋을까?: 결론부터 말하면, 대부분의 경우 의미가 없습니다. 운영체제가 알아서 메모리를 관리하고 있기 때문입니다. 오히려 강제종료 후 다시 열면 서랍에서 꺼내오는 과정을 처음부터 다시 해야 하므로, 배터리와 시간이 더 들 수 있습니다. 앱이 응답하지 않거나 오작동할 때만 쓰는 것이 맞습니다.
배달앱이 실행되었고, 화면에 검색창이 떴습니다. “치킨“이라고 입력하고 검색 버튼을 누릅니다. 이 데이터는 이제 스마트폰 밖으로 나가야 합니다. 그런데 주머니 속 이 작은 기계에서 데이터가 어떻게 밖으로 나갈까요? 선은 연결되어 있지도 않은데 말입니다.
-
Year 2038 problem. 대부분의 현대 OS는 64비트 시간으로 전환 완료. — Wikipedia ↩
-
임베디드 시스템(Embedded System): 특정 기능만 수행하도록 만들어진 소형 컴퓨터. ATM, 가전제품, 산업용 장비 등에 내장되어 있다. ↩
-
ECU(Electronic Control Unit): 자동차의 엔진, 브레이크 등을 제어하는 소형 컴퓨터. ↩
3장. 보이지 않는 고속도로
“WiFi, LTE/5G, 블루투스, 그리고 전자레인지”
이번 장에서 알게 될 것
- WiFi가 잘 터지는 방과 안 터지는 방이 다른 이유
- 전자레인지를 돌리면 WiFi가 느려지는 이유
- 5G가 빠르다면서 왜 건물 안에서는 잘 안 잡히는지
- 블루투스 이름이 왜 “파란 이빨“인지
치킨 주문 여정: 폰 밖으로
배달앱이 실행되었고, “치킨“을 검색했습니다. 이 검색 데이터는 이제 스마트폰 밖으로 나가야 합니다. 그런데 스마트폰에는 선이 꽂혀 있지 않습니다. 데이터는 어떻게 나갈까요?
WiFi가 잘 터지는 방, 안 터지는 방
거실에서는 잘 되던 WiFi가 안방에 들어가면 느려지고, 화장실에서는 거의 끊깁니다. 공유기 바로 옆에서는 빠른데, 방 하나만 건너면 영상이 버퍼링에 걸립니다.
WiFi는 눈에 보이지 않지만, 물리적인 한계가 있는 전파입니다. 빛처럼 직진하고, 벽에 부딪히면 약해지고, 다른 전파와 섞이면 느려집니다.
이 장에서는 스마트폰이 데이터를 밖으로 보내는 방법 — 전파의 세계 — 를 다룹니다.
전파: 보이지 않는 빛
WiFi, LTE, 블루투스, FM 라디오, 심지어 전자레인지까지. 이것들의 공통점이 있습니다.
전부 전자기파입니다.
전자기파라고 하면 어렵게 느껴지지만, 사실 우리가 매일 보는 “빛“도 전자기파의 일종입니다. 가시광선, 적외선, 자외선, X선, 전파 — 전부 같은 종류이고, 주파수만 다릅니다.
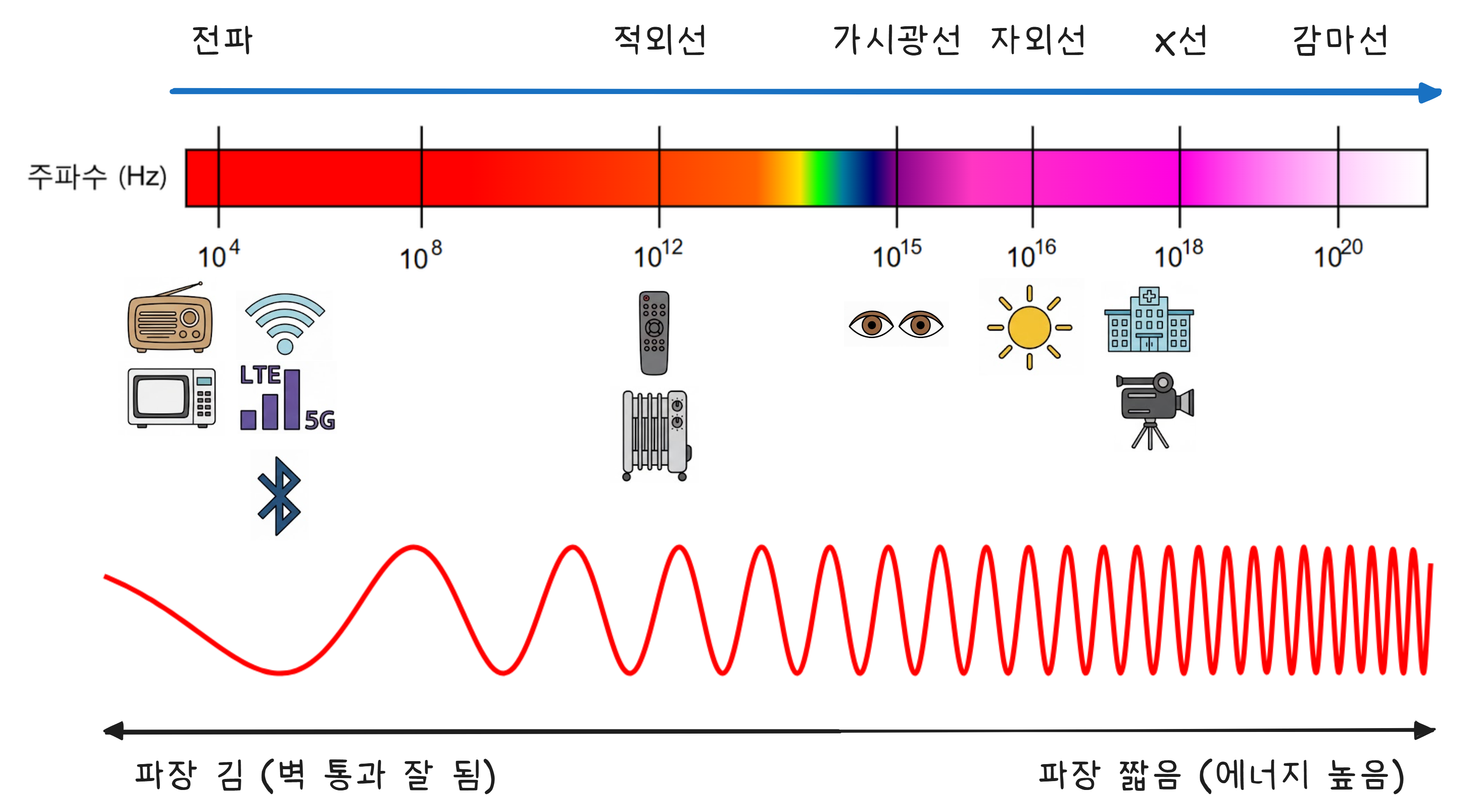
핵심은 이겁니다1 — 주파수가 높을수록 데이터를 많이 실어 보낼 수 있지만, 장애물에 약합니다.
FM 라디오가 산 뒤편에서도 들리는 건 주파수가 낮아서(88~108MHz) 파장이 길기 때문입니다. 파장이 길면 장애물을 돌아갈 수 있습니다. 반면 주파수가 높으면 파장이 짧아져서 벽이나 건물에 흡수되거나 반사됩니다.
WiFi도 이 법칙을 따릅니다.
2.4GHz vs 5GHz: 왜 WiFi가 두 개인가
공유기 설정을 보면 WiFi가 두 개 — 가끔 세 개 — 잡히는 경우가 있습니다. 같은 공유기인데 이름 뒤에 “5G“가 붙어 있거나, 주파수가 다르다고 표시됩니다.
이건 같은 공유기가 두 가지 주파수 대역으로 동시에 신호를 쏘기 때문입니다.
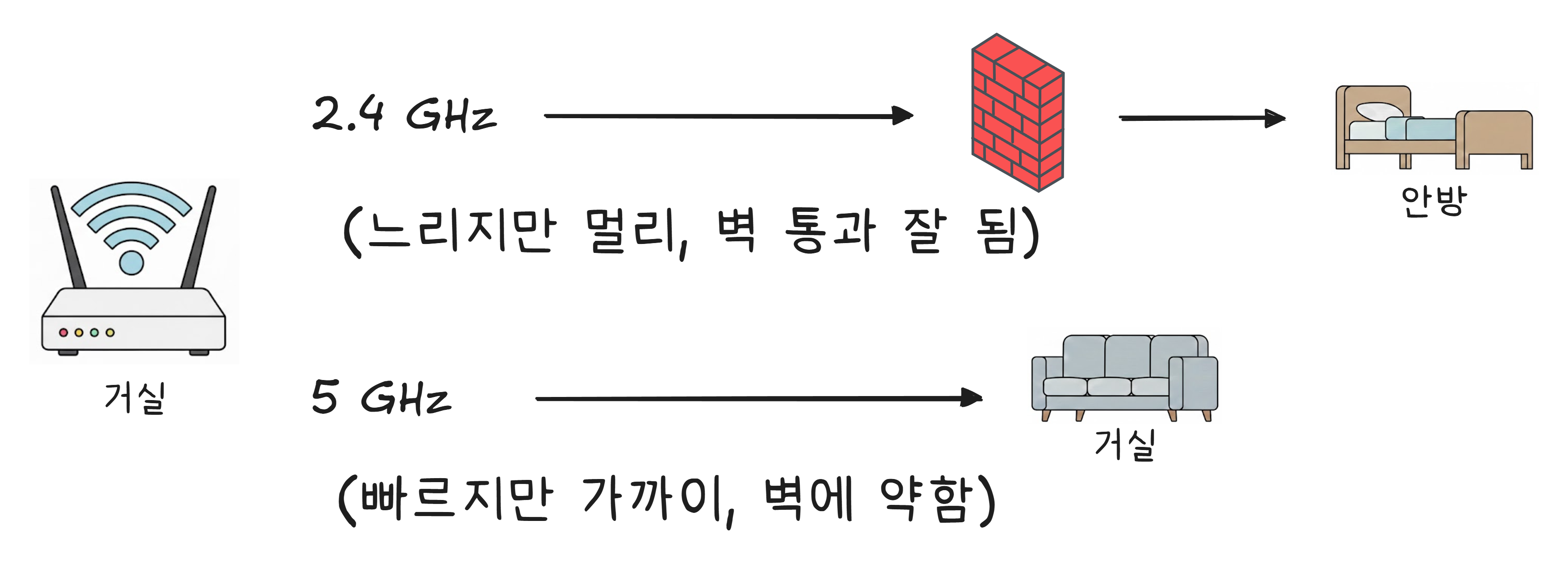
| 2.4GHz | 5GHz | |
|---|---|---|
| 파장 | ~12.5cm (긴 편) | ~6cm (짧은 편) |
| 속도 | 느림 | 빠름 |
| 벽 통과 | 잘 됨 | 약함 |
| 채널 수 | 3개 (혼잡) | 25개 (여유) |
| 적합한 상황 | 집 전체 커버 | 같은 방에서 빠른 속도 |
거실에서 영상을 보려면 5GHz가 좋고, 안방까지 신호가 닿아야 한다면 2.4GHz가 낫습니다. 이 선택은 결국 물리 법칙의 트레이드오프입니다 — 속도를 얻으면 도달 거리를 잃고, 도달 거리를 얻으면 속도를 잃습니다.
집이 넓거나 층이 다르면 공유기 하나로는 한계가 있습니다. 이 문제를 해결하기 위해 나온 것이 메시 WiFi(Mesh WiFi) 입니다. 공유기 여러 대를 집 곳곳에 놓고, 서로 무선으로 연결해서 집 전체를 하나의 WiFi 네트워크로 덮는 방식입니다. 기기가 방을 이동하면 가장 가까운 공유기로 자동 전환됩니다.
전자레인지를 돌리면 WiFi가 느려진다
여기서 재밌는 사실이 있습니다.
전자레인지도 2.4GHz를 사용합니다.
전자레인지는 2.45GHz 전자기파로 음식 속 물 분자를 진동시켜 열을 냅니다. WiFi도 2.4GHz 대역을 사용합니다. 같은 주파수 대역이니까 — 간섭이 발생합니다.
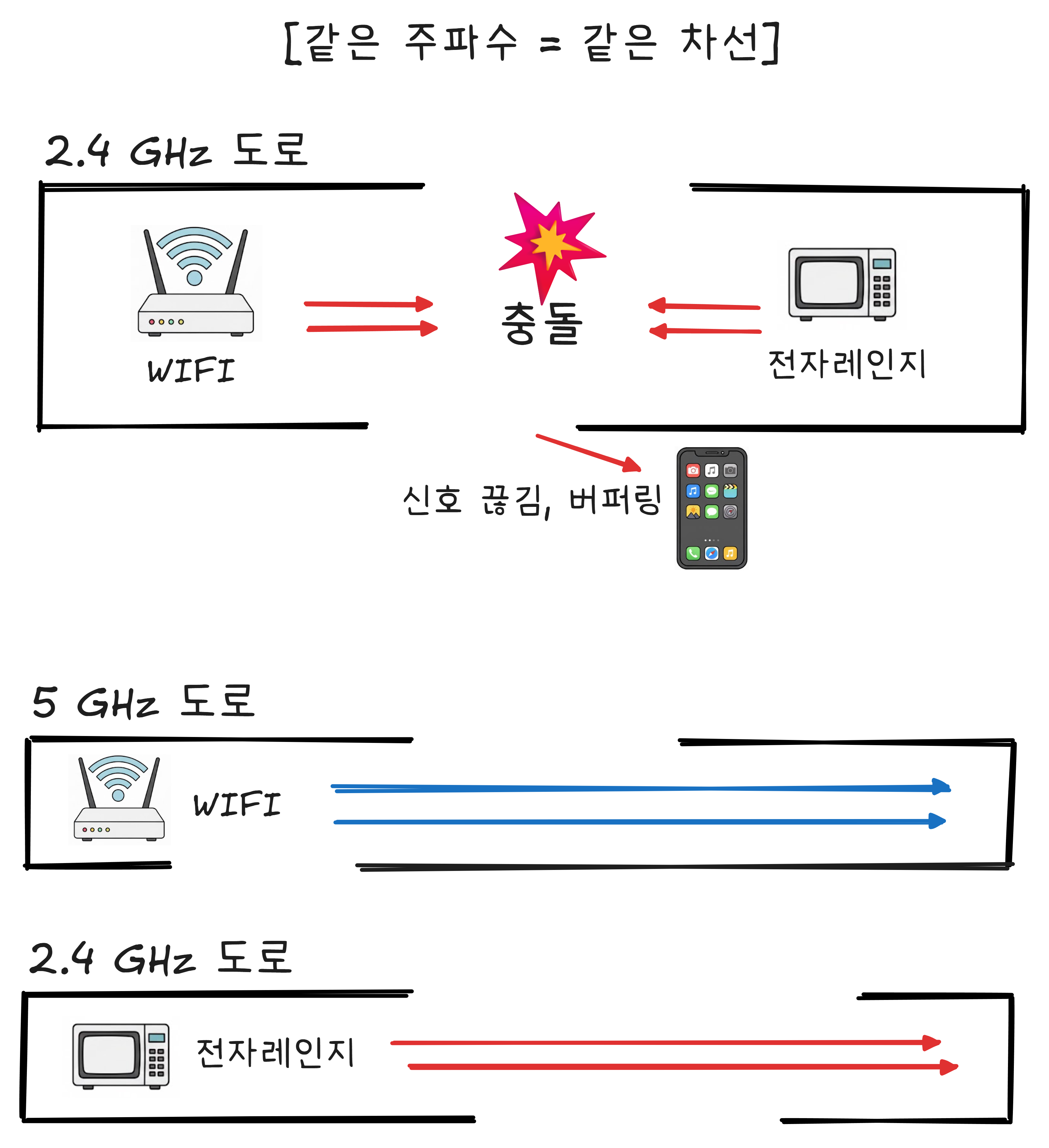
왜 굳이 같은 주파수를 쓰는 걸까요? 2.4GHz는 ISM 밴드(Industrial, Scientific, Medical) 라는 주파수 대역에 속합니다. 이 대역은 면허 없이 누구나 쓸 수 있는 “무료 주파수“입니다. 전자레인지도, WiFi도, 블루투스도 전부 이 무료 대역을 사용합니다. 무료니까 다 같이 쓰고, 다 같이 쓰니까 서로 간섭합니다.
해결법은 간단합니다. 5GHz WiFi를 쓰면 됩니다. 전자레인지와 주파수가 다르니까 간섭이 없습니다.
WiFi에도 세대가 있다
이동통신에 3G, 4G, 5G가 있듯이 WiFi에도 세대가 있습니다. 예전에는 “802.11n”, “802.11ac” 같은 복잡한 이름을 썼지만, 2018년부터 간단한 번호 체계로 바뀌었습니다.
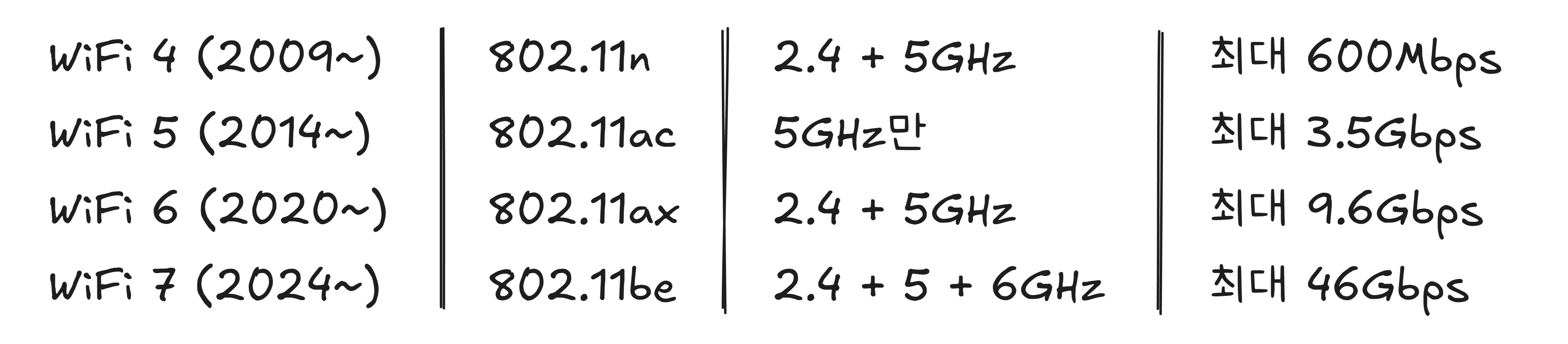
숫자만 보면 세대마다 몇 배씩 빨라지지만, 실제 체감 속도는 이론 수치와 다릅니다. WiFi 6의 핵심 개선점은 단순한 속도가 아니라 여러 기기가 동시에 접속했을 때의 효율입니다. 가족 4명이 각자 스마트폰, 태블릿, 노트북을 쓰면서 TV로 스트리밍까지 할 때, 예전 WiFi는 차례를 기다려야 했지만 WiFi 6부터는 여러 기기에 동시에 데이터를 보낼 수 있습니다.
LTE와 5G: 이동통신의 세대
WiFi는 공유기 근처에서만 됩니다. 밖에 나가면 LTE나 5G로 바뀝니다. 이건 통신사 기지국2과 연결되는 것입니다.
“G“는 Generation(세대)입니다. 1G부터 5G까지, 세대마다 속도가 크게 올랐습니다.

5G가 빠른 건 맞습니다. 이론상 LTE의 20배 속도입니다. 하지만 5G에도 종류가 있습니다.
Sub-6GHz vs 밀리미터파
5G는 두 가지 주파수 대역을 사용합니다.
Sub-6GHz(6GHz 이하)는 기존 LTE와 비슷한 주파수 대역입니다. 속도는 LTE의 2~3배 정도. 벽도 잘 통과합니다. 우리가 일상에서 쓰는 5G는 대부분 이겁니다.
밀리미터파(mmWave)(28GHz~)는 진짜로 빠릅니다. 하지만 주파수가 극도로 높아서 벽은커녕 손바닥으로 가려도 신호가 끊길 수 있습니다. 건물 안에서는 거의 쓸 수 없고, 기지국에서 수백 미터 이내에서만 작동합니다.
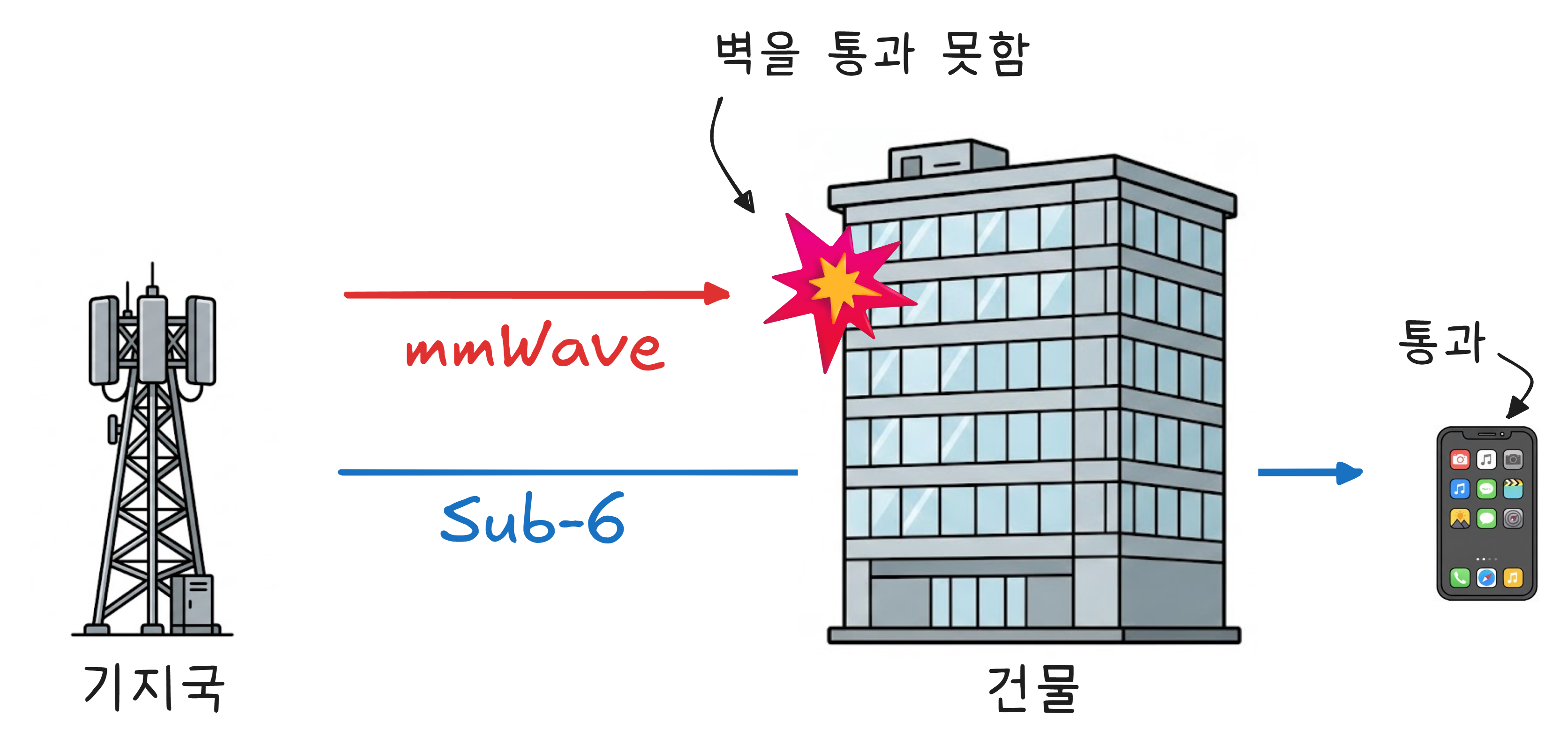
“5G인데 왜 체감이 안 나지?” 하는 이유가 여기에 있습니다. 대부분의 환경에서는 Sub-6GHz를 쓰고 있기 때문에, LTE보다 약간 빠른 정도에 그치는 것입니다. 밀리미터파의 진짜 속도를 체감하려면 기지국이 보이는 야외에 있어야 합니다.
5G의 진짜 가치는 단순한 속도보다 초저지연에 있습니다. LTE의 지연 시간이 약 30~50ms라면, 5G는 1~10ms까지 낮아집니다. 사람이 느끼기엔 둘 다 빠르지만, 자율주행차나 원격 수술처럼 밀리초 단위의 반응이 필요한 분야에서는 결정적인 차이입니다.
블루투스: 파란 이빨의 왕
무선 이어폰, 스마트워치, 키보드. 이런 기기를 폰과 연결하는 건 WiFi가 아니라 블루투스(Bluetooth) 입니다.
블루투스도 2.4GHz 대역을 사용하지만, WiFi와는 다른 방식으로 동작합니다. 블루투스는 2.4GHz 안에서 79개 채널을 1초에 수백 번 바꿔가며 데이터를 보냅니다. 이걸 주파수 호핑(Frequency Hopping) 이라고 합니다. 한 채널에서 간섭이 생겨도 바로 다른 채널로 뛰어넘으니까, 안정적으로 연결을 유지할 수 있습니다.
속도는 WiFi보다 훨씬 느립니다. 대신 전력 소모가 적어서 배터리로 동작하는 작은 기기에 적합합니다. 무선 이어폰이 하루 종일 가는 이유입니다.
그런데 이 기술의 이름이 왜 “파란 이빨“일까요?
10세기 덴마크 왕 하랄드 블로탄(Harald Bluetooth) 에서 따온 것입니다. 이 왕은 분열된 덴마크를 통일하고 노르웨이까지 지배한 인물입니다.3 블루투스 기술도 서로 다른 기기들을 하나로 연결한다는 의미에서 이 이름을 붙였습니다. 블루투스 로고도 하랄드의 이니셜 H와 B를 룬 문자로 합친 것입니다.
사건: 2024 CrowdStrike — 보안 업데이트 하나가 세계를 멈추다
2024년 7월 19일, 전 세계가 동시에 멈추었습니다.
미국 항공편 수천 편이 결항되었고, 영국 병원의 예약 시스템이 마비되었고, 호주 슈퍼마켓의 결제 시스템이 멈추었습니다. 원인은 해킹이 아니었습니다.
보안 회사 CrowdStrike가 배포한 소프트웨어 업데이트 파일 하나에 오류가 있었습니다.4
CrowdStrike의 보안 프로그램 “Falcon Sensor“는 전 세계 수백만 대의 윈도우 컴퓨터에 설치되어 있었습니다. 이 프로그램은 운영체제의 가장 깊은 곳 — 커널(Kernel) 수준 — 에서 동작합니다. 2장에서 운영체제가 “하드웨어와 앱 사이의 통역“이라고 했는데, 커널은 그 통역의 핵심부입니다.
이 핵심부에서 동작하는 프로그램이 잘못된 업데이트를 받았으니, 운영체제 자체가 부팅되지 못합니다. 결과는 파란 화면 — 2장에서 알쓸신잡으로 언급한 바로 그 블루스크린(BSOD)이었습니다.
피해 규모는 약 850만 대의 윈도우 컴퓨터. 전체 윈도우 기기의 1%도 안 되는 수치지만, 항공, 의료, 금융 등 핵심 인프라에 집중되어 있었기에 피해는 막대했습니다.
문제는 자동으로 고칠 수 없었다는 겁니다. 컴퓨터가 켜지지 않으니 원격 수정이 불가능합니다. IT 담당자가 한 대 한 대 직접 안전 모드로 부팅해서 문제 파일을 삭제해야 했습니다. 850만 대를.
하나의 잘못된 업데이트가 항공, 의료, 금융, 방송, 유통을 동시에 마비시켰습니다. 우리가 사는 세계가 소프트웨어 위에 얼마나 빈틈없이 올라가 있는지를 보여준 사건입니다.
알쓸신잡
-
비행기 모드는 정말 필요한가?: 비행기 모드의 원래 목적은 스마트폰 전파가 항공 장비에 간섭을 일으킬 가능성을 차단하는 것이었습니다. 실제로 현대 항공기에 영향을 주는지는 확실히 입증된 적이 없습니다. 하지만 수백 명의 승객이 동시에 기지국을 찾는 신호를 보내면 지상 통신망에 부담을 줄 수 있고, 만에 하나라도 위험 가능성이 있으니 규정으로 유지하고 있는 것입니다. 요즘은 기내 WiFi가 제공되는 항공편이 많아서, 비행기 모드를 켠 채로 WiFi만 따로 켜는 경우가 흔합니다.
-
LAN 케이블이 꼬여 있는 이유: 이더넷 케이블(LAN선)을 잘라보면 내부에 꼬인 선 4쌍(8가닥)이 들어 있습니다. 전류가 흐르는 선 주위에는 전자기장이 생기는데, 두 선이 나란히 놓여 있으면 서로 간섭합니다(크로스토크). 선을 꼬면 전자기장이 반 바퀴마다 방향이 뒤집혀서 간섭이 상쇄됩니다. 이 기술을 발명한 사람은 전화기의 발명자 알렉산더 그레이엄 벨입니다. 1881년 특허(US 244,426).5 전화선 간섭을 줄이기 위해 만든 것이 140년 뒤에도 인터넷 케이블에 쓰이고 있습니다.
-
WiFi 이름에 재밌는 이름 짓기: 공유기의 WiFi 이름(SSID)은 자유롭게 설정할 수 있습니다. 해외에서는 “FBI Surveillance Van”(FBI 감시 차량), “Pretty Fly for a Wi-Fi”, “It Hurts When IP” 같은 이름이 유명합니다. 한국에서는 “비밀번호는1234”, “옆집것쓰지마세요” 같은 이름이 돌아다닙니다.
이제 데이터가 전파를 타고 스마트폰을 빠져나왔습니다. 공유기를 지나 통신사 네트워크에 도달했습니다. 그런데 이 데이터가 태평양 건너 미국 서버까지 닿으려면, 대체 어떤 길을 따라가는 걸까요?
-
그림 출처: Wikimedia Commons, Inductiveload, CC BY-SA 3.0 기반 재구성 ↩
-
기지국: 스마트폰과 통신사 네트워크를 연결하는 안테나 장비. 건물 옥상이나 철탑 위에서 흔히 볼 수 있다. ↩
-
하랄드 블로탄(Harald Bluetooth, c.958~c.986). — Bluetooth.com 공식 유래 ↩
-
2024년 7월 19일. 약 850만 대의 윈도우 기기가 영향을 받았다. — CrowdStrike 사고 보고서 ↩
-
Alexander Graham Bell, US Patent 244,426 (1881). — Google Patents ↩
4장. 바다 밑의 실
“해저케이블, 데이터센터, 클라우드의 정체”
이번 장에서 알게 될 것
- “클라우드“의 정체가 무엇인지
- 바다 밑 케이블이 정말로 존재하는지, 얼마나 굵은지
- 광섬유 안에서 빛이 어떻게 데이터를 나르는지
- 상어가 인터넷을 끊을 수 있는지
치킨 주문 여정: 바다를 건너다
데이터가 전파를 타고 스마트폰을 빠져나왔습니다. 공유기를 지나 통신사 네트워크에 도달했습니다. 여기서부터 데이터는 케이블을 타고 이동합니다. 때로는 바다 밑을 지나서.
“클라우드“라는 이름이 만든 착각
“클라우드에 사진을 백업했다”, “클라우드에 저장했다” — 이런 표현을 자주 씁니다. 클라우드(Cloud)라는 단어 때문에 데이터가 어딘가 하늘 위의 구름 속에 떠 있는 것 같은 느낌이 듭니다.
실제는 이렇습니다.
“The Cloud is just someone else’s computer.” (클라우드는 그냥 남의 컴퓨터다.)
클라우드에 파일을 저장한다는 것은, 지구 어딘가에 있는 거대한 건물 안에 빼곡히 들어선 서버의 하드디스크에 파일을 저장한다는 뜻입니다. 그 건물을 데이터센터라고 합니다.
그리고 여러분의 스마트폰과 그 데이터센터를 연결하는 건, 결국 물리적인 케이블입니다.
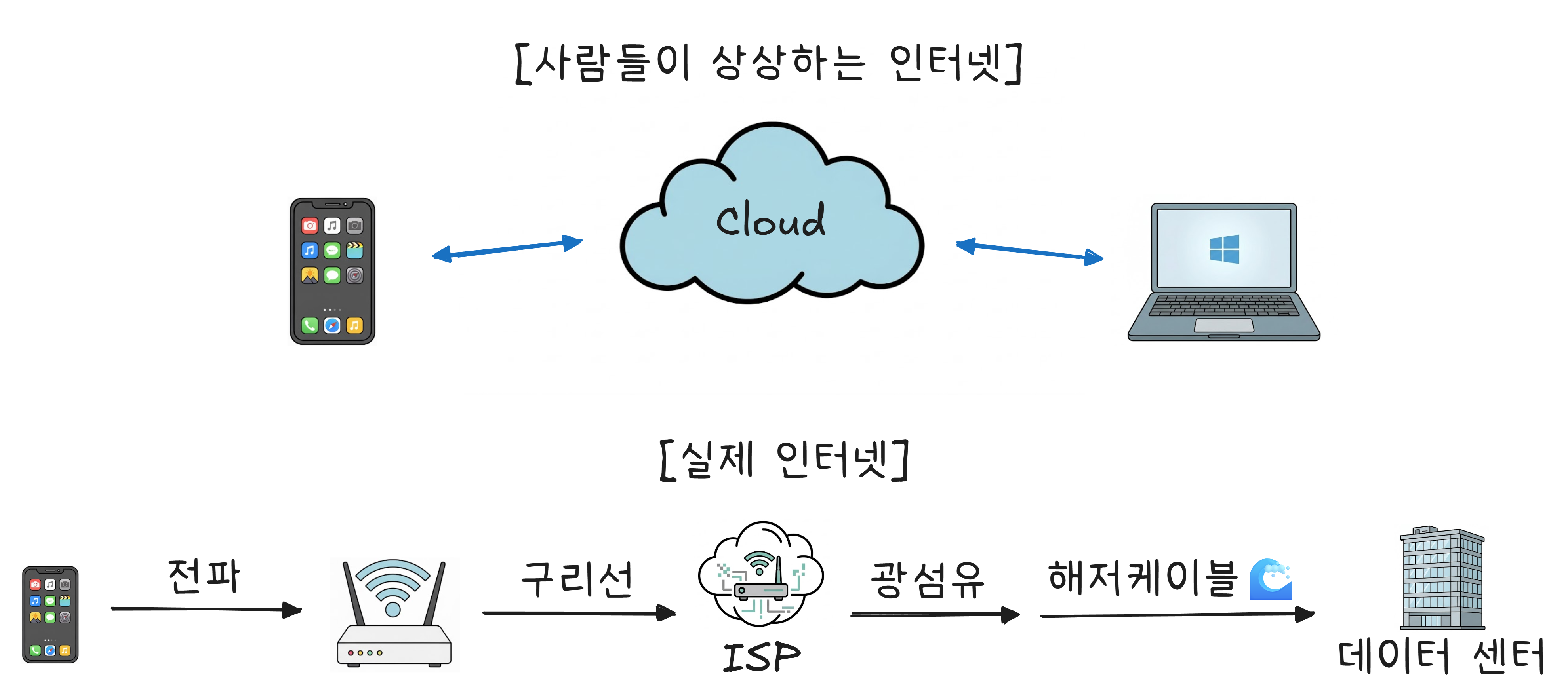
WiFi는 집 안에서 공유기까지의 마지막 구간만 무선일 뿐입니다. 공유기 뒤로는 ISP1를 거쳐 전부 유선입니다. 구리선, 광섬유, 그리고 바다 밑 해저케이블. 인터넷의 99%는 물리적인 선으로 연결되어 있습니다.
바다 밑에 정말 케이블이 깔려 있다
현재 전 세계에 깔려 있는 해저케이블은 약 600개 이상. 총 길이 약 150만 km입니다. 지구에서 달까지 거리가 약 38만 km이니, 달까지 거의 네 번 갈 수 있는 길이입니다.
대서양, 태평양, 인도양 — 거의 모든 바다 밑에 케이블이 깔려 있습니다. 유럽과 미국, 한국과 미국, 아프리카와 유럽이 전부 바다 밑 케이블로 연결되어 있습니다. 세계 대륙 간 인터넷 트래픽의 95% 이상이 이 해저케이블을 통해 이동합니다. 위성이 아닙니다. 케이블입니다.
정원 호스보다 가늘다
해저케이블이라고 하면 거대한 파이프를 상상하기 쉽습니다. 실제로는 놀라울 정도로 가늡니다.

위 사진에서 볼 수 있듯, 해저케이블은 구간에 따라 굵기가 다릅니다.2 연안 구간은 선박 앵커나 상어로부터 보호하기 위해 철갑층이 덧대어져 두껍고, 심해 구간은 외부 위협이 적어 훨씬 가늡니다. 심해 구간의 전체 굵기는 약 17mm — 엄지손가락 정도입니다.
광섬유 한 가닥의 굵기는 클래딩(외피)을 포함해 125마이크로미터 — 머리카락 한 올과 비슷합니다. 빛이 실제로 지나가는 코어는 그보다 훨씬 가는 약 9마이크로미터에 불과합니다. 이 가느다란 유리 실 안에서 빛이 반사되면서 데이터가 이동합니다. 하나의 케이블에 이런 광섬유가 여러 가닥 들어 있고, 각 가닥에서 서로 다른 파장(색)의 빛을 동시에 보내면 하나의 케이블로 수백 Tbps3 의 데이터를 전송할 수 있습니다.
지구-달 4배 거리의 케이블을 통해 흐르는 전 세계 인터넷의 95%가, 머리카락보다 가는 유리 실 안의 빛입니다.
광섬유: 빛이 유리 안에서 튕기는 원리
광섬유 안에서 빛은 어떻게 수천 킬로미터를 이동할까요? 직선이 아니라 바다 밑 곡선을 따라 깔려 있는데 말입니다.
비밀은 전반사(Total Internal Reflection) 입니다.
수영장 바닥에서 물 위를 올려다본 적이 있다면, 특정 각도 이상으로 비스듬히 보면 수면이 거울처럼 보이는 것을 경험했을 겁니다. 빛이 밀도가 다른 물질의 경계면에서 완전히 반사되는 현상입니다.
광섬유는 이 원리를 이용합니다. 유리 섬유 안쪽(코어)의 굴절률이 바깥쪽(클래딩)보다 높습니다. 빛이 코어 안으로 들어가면 경계면에서 전반사를 반복하면서 앞으로 나아갑니다. 유리 섬유가 휘어져 있어도 빛은 안쪽 벽에서 계속 튕기면서 따라갑니다.
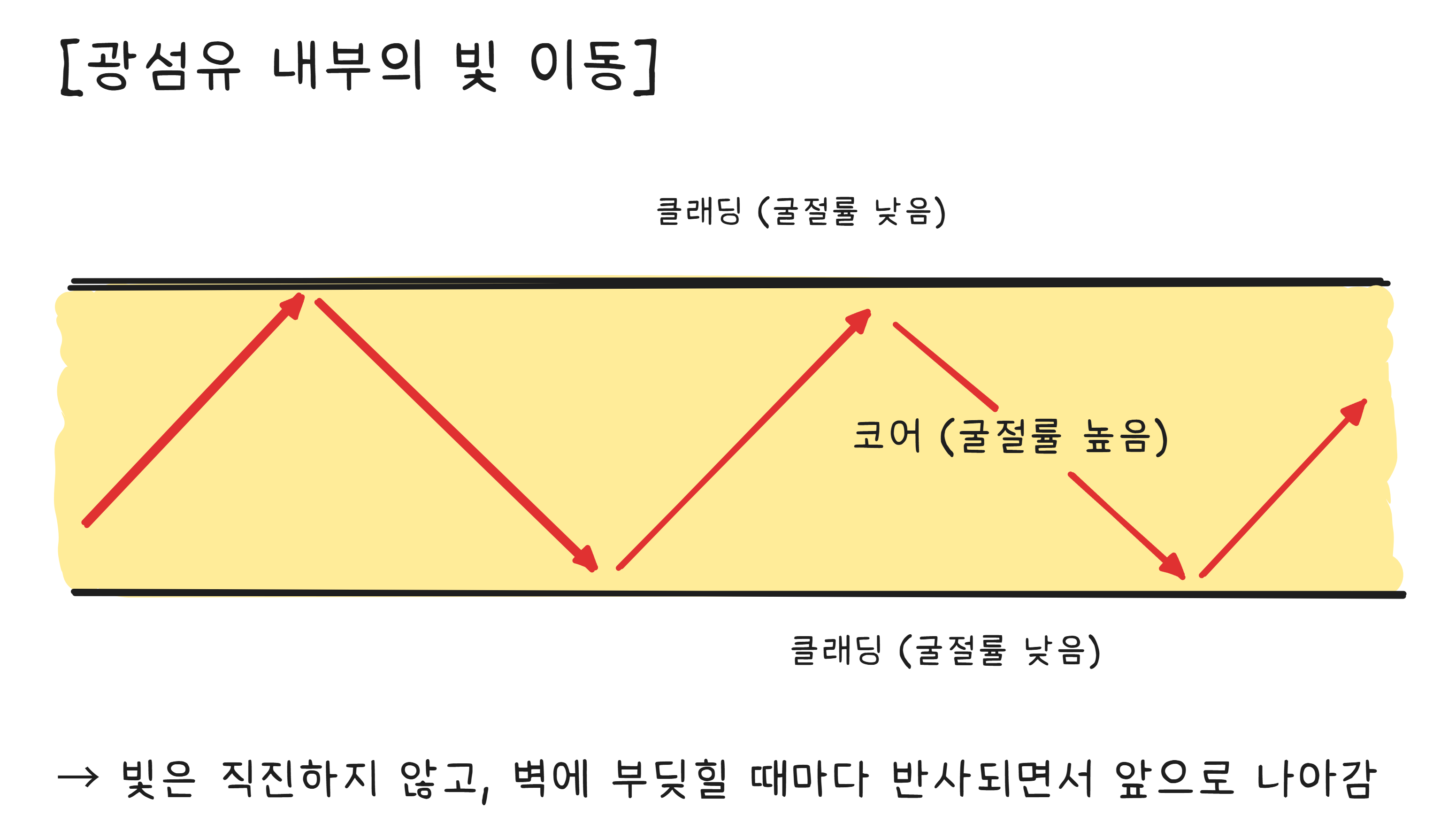
집에서 이 원리를 확인할 수 있는 방법이 있습니다. 어두운 방에서 수도꼭지를 틀어 가느다란 물줄기를 만들고, 레이저 포인터를 물줄기에 비추면 — 빛이 물줄기를 따라 휘어지는 것을 볼 수 있습니다. 물과 공기의 경계에서 전반사가 일어나기 때문입니다. 광섬유도 정확히 같은 원리입니다.
광섬유 안에서 빛의 속도는 진공에서보다 약간 느립니다. 유리의 굴절률 때문에 진공 대비 약 2/3 속도로 이동합니다. 그래도 초속 약 20만 km. 태평양 횡단 약 9,000km를 빛이 이동하는 데 약 0.045초, 왕복 0.09초입니다.
데이터센터: 클라우드의 실체
데이터가 해저케이블을 건너 도착하는 곳. 데이터센터입니다.
데이터센터는 서버 수만에서 수십만 대가 들어찬 거대한 건물입니다. 구글, 아마존(AWS), 마이크로소프트(Azure)가 전 세계에 수십 곳씩 운영하고 있습니다. 우리가 사용하는 대부분의 인터넷 서비스 — 검색, 유튜브, 넷플릭스, 배달앱 — 의 데이터가 이 건물들 안에 있습니다.
데이터센터를 만들 때 가장 중요한 문제는 세 가지입니다.
1. 전력
서버는 24시간 365일 돌아갑니다. 대형 데이터센터 하나의 전력 소비량은 수만 가구와 맞먹습니다. 전 세계 데이터센터의 전력 소비량을 합치면 일부 국가 전체 전력 소비량보다 많습니다. 그래서 데이터센터는 전력이 싸고 안정적인 곳에 들어섭니다.
2. 냉각
서버가 돌아가면 열이 납니다. 수만 대가 한 건물에 모여 있으니, 냉각이 안 되면 서버가 과열로 멈춥니다. 데이터센터가 기온이 낮은 지역을 선호하는 이유입니다. 페이스북(메타)의 데이터센터가 스웨덴 북극권 근처에 있고, 마이크로소프트가 해저에 데이터센터를 가라앉히는 실험(Project Natick)을 한 이유입니다.
3. 위치 (네트워크 근접성)
아무리 빛의 속도라고 해도, 물리적 거리가 멀면 지연시간4이 생깁니다. 서울에서 미국 서부까지 왕복 약 0.1초. 0.1초가 짧아 보이지만, 이것이 누적되면 체감 속도에 영향을 줍니다. 대형 IT 기업들이 전 세계 곳곳에 데이터센터를 분산 배치하는 이유입니다.
인터넷의 수도: 버지니아주 애쉬번
미국 버지니아주 애쉬번(Ashburn)이라는 작은 도시에는 전 세계 인터넷 트래픽의 상당 부분이 지나가는 데이터센터가 밀집해 있습니다. 아마존(AWS), 마이크로소프트(Azure), 구글(GCP)의 데이터센터가 모여 있는 이 도시는 “인터넷의 수도“라고 불립니다.
이유는 역사적입니다. 1990년대 초 미국 인터넷 교환점(MAE-East)이 이 지역에 설치되었고, 이후 데이터센터들이 주변에 하나둘씩 들어서기 시작했습니다. 네트워크 인프라가 이미 깔려 있으니 새 데이터센터도 가까이에 짓는 것이 유리합니다. 눈덩이처럼 불어나서 지금의 밀집도가 된 것입니다.
위성 인터넷은 대안이 될 수 있을까?
해저케이블이 이렇게 중요하다면, 위성으로 대체하면 안 될까요?
SpaceX의 스타링크(Starlink) 가 이 질문에 도전하고 있습니다. 저궤도(550km) 위성 수천 개를 띄워 어디서든 인터넷에 접속할 수 있게 만드는 프로젝트입니다.
스타링크의 장점은 확실합니다. 해저케이블이 없는 오지, 섬, 선박, 비행기에서도 인터넷을 쓸 수 있습니다. 하지만 해저케이블을 대체하는 것은 불가능합니다.
이유는 단순합니다. 대역폭 차이가 압도적이기 때문입니다.

그리고 위성 인터넷도 결국 지상의 기지국을 거쳐 해저케이블에 연결됩니다. 위성은 중계기 역할일 뿐, 최종 목적지인 데이터센터와는 케이블로 연결되어야 합니다.
위성 인터넷은 해저케이블이 닿지 않는 곳의 보완재이지, 대체재가 아닙니다.
사건: 2022년 통가 — 해저케이블이 끊기면 벌어지는 일
2022년 1월 15일, 남태평양 통가에서 해저 화산 훙가통가-훙가하파이(Hunga Tonga-Hunga Ha’apai)가 폭발합니다. 인류 역사상 위성으로 관측된 가장 강력한 화산 폭발 중 하나였습니다.
폭발의 충격파는 지구를 여러 바퀴 돌았습니다. 그리고 해저 화산재와 잔해가 통가를 연결하는 해저케이블을 절단했습니다.5
통가의 인구는 약 10만 명. 이 나라의 국제 인터넷 연결은 해저케이블 단 1개에 의존하고 있었습니다. 케이블이 끊어지자 통가는 사실상 디지털 세계에서 사라졌습니다.
- 국제 전화와 인터넷이 완전히 두절
- 긴급 구호 요청도 통신 불가
- 피해 규모 파악조차 며칠간 불가능
- 위성 전화와 제한적 위성 인터넷으로 간신히 연락
케이블 수리에는 약 5주가 걸렸습니다. 전 세계에 해저케이블 수리 전문선이 약 60척밖에 없고, 가장 가까운 수리선이 도착하는 데만 시간이 걸렸기 때문입니다. 수리는 해저에서 절단된 케이블 양쪽 끝을 끌어올려 광섬유를 마이크로미터 단위로 정밀하게 이어 붙이는 작업입니다.
5주 동안 통가 국민들은 인터넷 없는 삶을 살았습니다. 해외 가족과 연락이 끊겼고, 온라인 금융 거래가 불가능했고, 뉴스를 볼 수 없었습니다.
해저케이블 하나가 한 나라 전체를 디지털 세계에서 단절시킨 사건입니다.
구글과 메타가 직접 케이블을 까는 이유
과거에는 통신사가 해저케이블을 깔고, IT 기업은 통신사에 돈을 내고 사용했습니다. 그런데 최근에는 구글, 메타(페이스북), 아마존, 마이크로소프트가 직접 해저케이블을 투자하고 건설합니다.
이유는 두 가지입니다.
첫째, 트래픽이 너무 많습니다. 유튜브, 구글 검색, 구글 클라우드의 트래픽은 통신사 케이블을 공유해서는 감당이 안 되는 수준입니다. 자체 케이블을 깔면 대역폭을 독점할 수 있습니다.
둘째, 통신사에 의존하면 비용과 품질을 통제할 수 없습니다. 자체 케이블이 있으면 경로, 속도, 비용을 직접 관리할 수 있습니다.
구글이 투자하거나 소유한 해저케이블만 해도 Curie, Dunant, Equiano, Grace Hopper, Firmina 등 여러 개입니다. 메타도 2Africa라는 아프리카 전체를 감싸는 해저케이블 프로젝트에 투자했습니다.
“클라우드“라는 이름과 달리, IT 공룡들은 바다 밑 물리적 인프라에 수십억 달러를 쏟아붓고 있습니다.
한국의 인터넷이 빠른 이유
한국은 세계에서 인터넷 속도가 가장 빠른 나라 중 하나입니다. 이건 우연이 아니라 물리적 인프라 덕분입니다.
한국은 국토가 좁고 인구 밀도가 높습니다. 아파트 밀집 구조 덕분에 건물 하나에 광섬유 하나만 끌어오면 수백 세대를 커버할 수 있습니다. 미국처럼 집집마다 수 킬로미터씩 케이블을 까는 것과는 효율이 다릅니다.
또한 2000년대 초반 정부가 적극적으로 광섬유 인프라에 투자했습니다. “IT 강국“이라는 타이틀은 소프트웨어만으로 얻은 것이 아니라, 물리적 케이블을 전국에 깔았기 때문에 가능한 것입니다.
알쓸신잡
-
상어가 해저케이블을 무는 이유: 상어는 먹이를 찾을 때 머리의 로렌치니 기관으로 전기장을 감지합니다. 해저케이블에서 발생하는 미세한 전자기장을 먹이로 오인하고 물어뜯는 것입니다. 구글은 태평양 해저케이블을 케블라(방탄복 소재) 로 보호합니다. 그 외에도 선박 앵커, 트롤 어선, 지진이 해저케이블의 주요 위협입니다.
-
대만의 “실리콘 방패”: 대만에 연결된 해저케이블은 약 14개. 세계 파운드리(반도체 위탁생산) 시장의 60% 이상을 점유하는 TSMC가 대만에 있습니다. 대만의 해저케이블이 끊어지면 반도체 설계 데이터 전송이 불가능해지고, 전 세계 공급망이 흔들립니다. 대만의 반도체 산업 자체가 외부 침략을 억제하는 방패 역할을 한다는 의미에서 “실리콘 방패(Silicon Shield)“라는 말이 나왔습니다.
-
마이크로소프트의 해저 데이터센터: 2018년 마이크로소프트는 855대의 서버가 든 컨테이너를 스코틀랜드 해저에 가라앉혔습니다(Project Natick). 해저의 차가운 물로 냉각하겠다는 실험이었습니다. 2년 뒤 끌어올렸을 때, 지상 데이터센터보다 고장률이 8분의 1 수준이었다고 합니다. 인간이 접근하지 않으니 먼지, 부식, 충격이 없었기 때문입니다.
-
넷플릭스는 바다를 건너지 않는다: 넷플릭스 영상을 볼 때, 데이터가 미국에서 해저케이블을 타고 오는 것은 아닙니다. 넷플릭스는 ISP의 데이터센터 안에 전용 서버를 직접 설치합니다. 인기 있는 콘텐츠를 미리 복사해 놓으면, 사용자에게 가장 가까운 서버에서 바로 전송할 수 있습니다. 이런 구조를 CDN(Content Delivery Network) 이라고 합니다.
데이터가 케이블을 타고 이동하고 있습니다. 그런데 전 세계에 서버가 수억 대 있고, 웹사이트가 수십억 개 있습니다. 우리의 치킨 검색 데이터는 이 중에서 정확히 어디로 가야 할까요? 인터넷에도 주소 체계가 있습니다. 그리고 그 주소를 찾아주는 전화번호부가 있습니다.
-
ISP(Internet Service Provider): KT, SKT, LG U+ 같은 인터넷 서비스 제공업체. 매달 인터넷 요금을 내는 그 통신사. ↩
-
그림 출처: Wikimedia Commons, Lonnie Hagadorn, CC BY-SA 4.0 기반 한국어 번역 재구성. ↩
-
Tbps(Terabits per second): 초당 테라비트. 1Tbps면 1초에 고화질 영화 약 250편 분량. ↩
-
지연시간(Latency, 레이턴시): 데이터가 출발지에서 도착지까지 걸리는 시간. ↩
5장. 주소를 찾아서
“DNS, IP, 라우팅 — 인터넷의 내비게이션”
이번 장에서 알게 될 것
- 인터넷에 연결된 모든 기기가 갖고 있는 “주소“의 정체
- 43억 개의 주소가 바닥나도 인터넷이 작동하는 이유
- “google.com“을 치면 벌어지는 눈에 보이지 않는 질문 릴레이
- 전 세계 인터넷을 6시간 동안 멈춘 설정 실수 하나
치킨 주문 여정: 주소를 찾아라
데이터가 해저케이블을 타고 이동할 준비가 되었습니다. 그런데 어디로? 전 세계에 서버가 수억 대이고, 웹사이트가 수십억 개입니다. “배달의민족 서버“가 어디에 있는지, 우리의 스마트폰은 어떻게 알까요?
인터넷에도 주소가 있다
택배를 보내려면 주소가 필요합니다. 인터넷도 마찬가지입니다.
인터넷에 연결된 모든 기기 — 스마트폰, 노트북, 서버, 심지어 스마트 냉장고까지 — 에는 고유한 주소가 할당됩니다. 이 주소를 IP 주소(Internet Protocol Address) 라고 합니다.
IP 주소는 이렇게 생겼습니다.

네 개의 숫자를 점으로 구분한 형태입니다. 각 숫자는 0부터 255까지의 범위를 가지고, 전체는 32비트로 구성됩니다. 이 방식을 IPv4(Internet Protocol version 4) 라고 합니다.
32비트로 만들 수 있는 주소의 개수는 2^32 = 4,294,967,296. 약 43억 개입니다.
43억이면 충분해 보입니다. 1980년대에 이 체계를 설계한 사람들도 그렇게 생각했습니다. 그런데 2025년 현재, 전 세계 인구는 약 80억 명이고, 인터넷에 연결된 기기는 150억 대를 넘습니다. 스마트폰, 노트북, 태블릿, 스마트워치, 스마트 TV, 공유기, IoT 센서… 한 사람이 여러 대의 기기를 사용하는 시대가 온 것입니다.
IPv4 주소는 2011년에 공식적으로 고갈되었습니다.
하지만 우리는 2025년에도 인터넷을 잘 쓰고 있습니다. 어떻게?
아파트 호수의 비밀: NAT
답은 NAT(Network Address Translation, 네트워크 주소 변환) 에 있습니다.
여러분의 집에는 인터넷에서 보이는 공식 주소가 하나 있습니다. 공인 IP라고 합니다. 그리고 집 안의 기기들 — PC, 스마트폰, 태블릿, 스마트 TV — 은 각각 별도의 내부 주소를 갖습니다. 사설 IP라고 합니다.
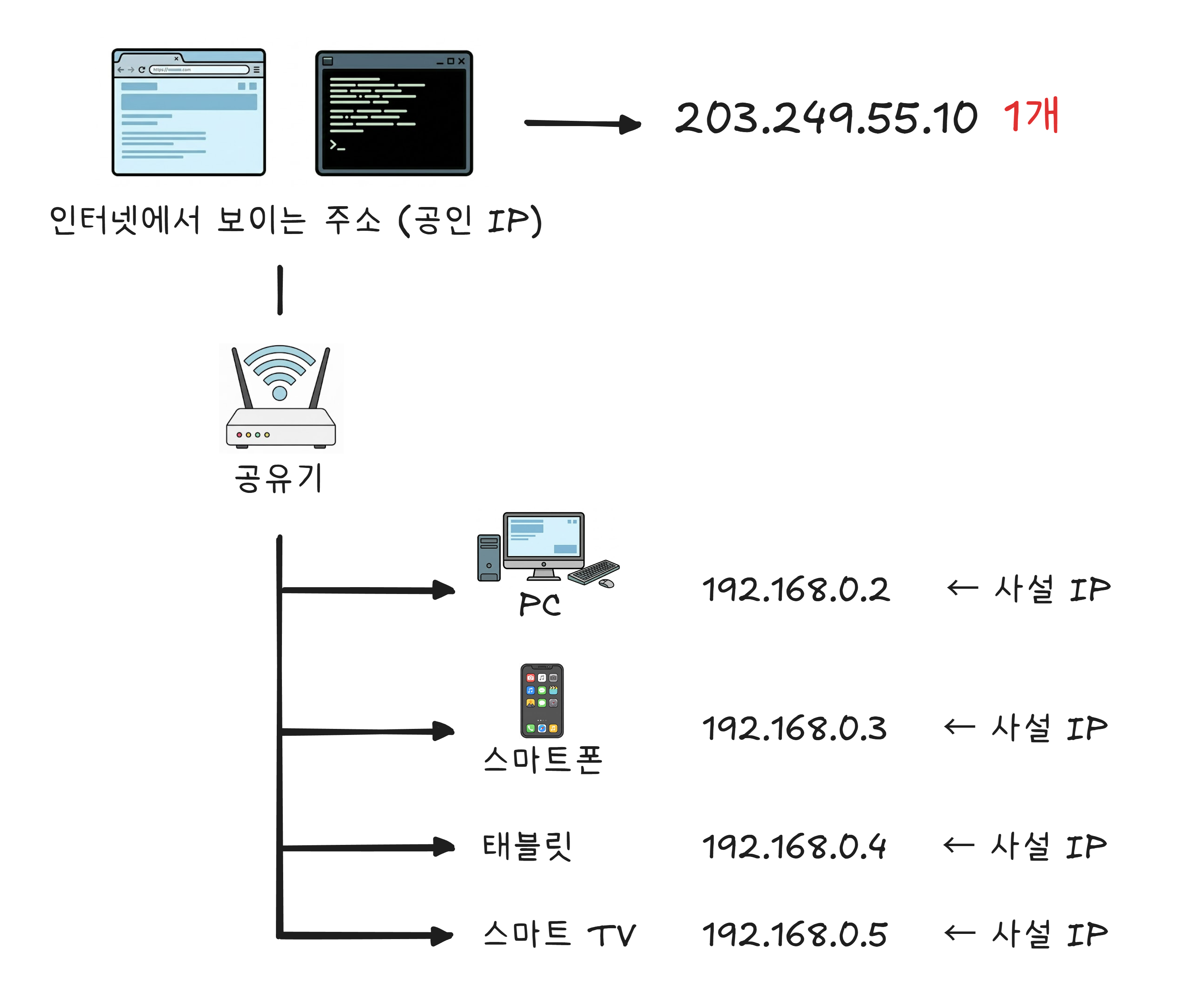
아파트를 생각해 보겠습니다. 택배 기사에게 필요한 주소는 “서울시 강남구 XX아파트“입니다. 이것이 공인 IP입니다. 아파트 안에서 각 세대를 구분하는 “101호, 102호, 201호“는 사설 IP에 해당합니다.
공유기가 아파트 관리실 역할을 합니다. 밖에서 택배(데이터)가 오면, 공유기는 “이건 102호(스마트폰)가 요청한 거니까 102호로 전달“하고 판단합니다. 안에서 밖으로 나가는 택배도 마찬가지입니다. 공유기가 발신 주소를 공인 IP로 바꿔서 내보냅니다.
이 덕분에 공인 IP 하나로 집 안의 기기 수십 대가 동시에 인터넷을 사용할 수 있습니다. 전 세계가 43억 개의 IPv4 주소로 아직까지 버틸 수 있는 가장 큰 이유입니다.
192.168.x.x, 10.x.x.x, 172.16.x.x로 시작하는 주소를 본 적이 있다면, 그것은 사설 IP입니다. 인터넷 밖으로는 나갈 수 없고, 여러분의 네트워크 안에서만 유효합니다.
WiFi 설정에서 IP 주소가
192.168.0.x로 시작하는 것을 본 적 있을 겁니다. 그건 여러분의 공유기가 할당한 사설 IP입니다. 옆집도192.168.0.x를 쓸 수 있습니다. 아파트 “101호“가 어느 아파트에나 있는 것처럼, 사설 IP는 각 네트워크 안에서만 의미가 있습니다.
IPv6: 우주의 모래알에도 주소를
NAT는 응급 처치였습니다. 근본적인 해결책은 주소를 더 많이 만드는 것입니다.
그래서 등장한 것이 IPv6(Internet Protocol version 6) 입니다.

128비트로 만들 수 있는 주소의 수는 2^128 ≈ 3.4 × 10^38개입니다.
이 숫자가 얼마나 큰지 감이 잘 안 옵니다. 이렇게 비교해 보겠습니다.
- 지구 위의 모래알 하나하나에 수만 조 개씩 주소를 부여해도 남습니다
- 관측 가능한 우주의 모든 별에 각각 수백 조 개의 주소를 줄 수 있습니다
- 사실상 무한입니다
그런데 IPv6가 2011년부터 권장되었는데, 2025년 현재 전 세계 보급률은 약 40% 정도입니다. 14년이 지났는데 절반도 안 됩니다.
이유는 간단합니다. “잘 돌아가는 걸 왜 바꿔?”
NAT로 충분히 버티고 있고, IPv4와 IPv6는 서로 호환되지 않아서 두 체계를 동시에 운영해야 합니다. 라우터, 방화벽, 소프트웨어를 전부 업데이트하려면 비용이 어마어마합니다. 그래서 전환이 이렇게 느린 것입니다.
기술의 세계에서도 “작동하는 코드를 건드리지 마라“는 원칙은 강력합니다.
DNS: 인터넷의 전화번호부
IP 주소 이야기를 했으니, 한 가지 실험을 해보겠습니다.
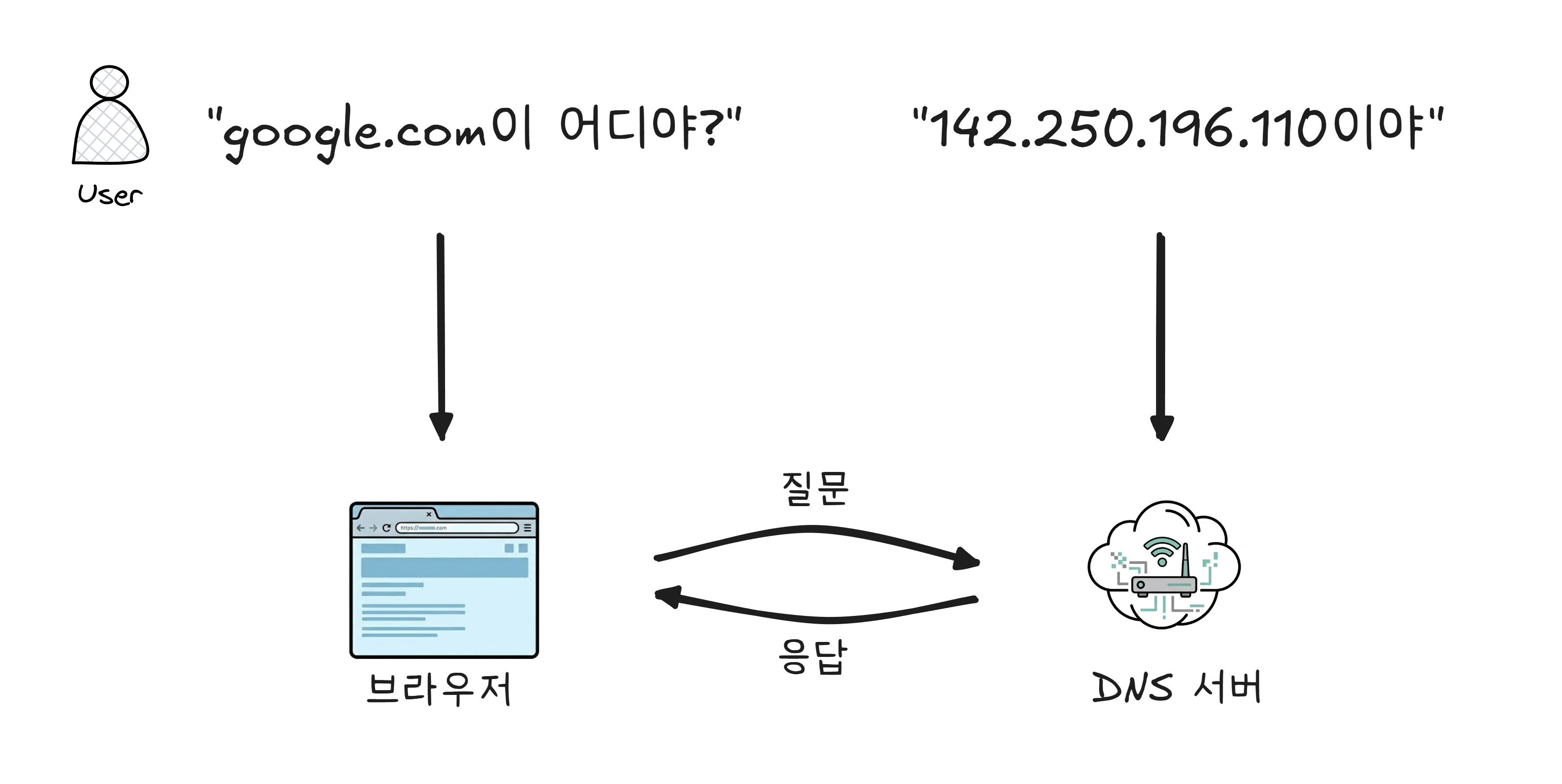
142.250.196.110
이 숫자가 무엇인지 아시나요? google.com 의 IP 주소입니다.
우리가 인터넷을 쓸 때 IP 주소를 직접 입력하는 일은 없습니다. “google.com”, “naver.com”, “baemin.com“처럼 이름을 입력합니다. 하지만 컴퓨터는 이름을 모릅니다. 오직 숫자(IP 주소)만 이해합니다.
누군가가 이름을 숫자로 변환해 줘야 합니다.
그 역할을 하는 것이 DNS(Domain Name System) 입니다. 말 그대로 인터넷의 전화번호부입니다. “김철수“라는 이름을 전화번호부에서 찾으면 전화번호가 나오듯, “google.com“을 DNS에 물어보면 142.250.196.110이라는 IP 주소가 나옵니다.
간단해 보이지만, 전 세계에는 도메인이 수십억 개 있습니다. 이걸 서버 하나가 다 알고 있을 수는 없습니다.
질문 릴레이: DNS의 계층 구조
DNS는 하나의 거대한 전화번호부가 아니라, 계층적으로 분산된 시스템입니다. “모르면 위에 물어보고, 위에서도 모르면 더 위에 물어보는” 구조입니다.
여러분이 브라우저에 “baemin.com“을 입력하면, 다음과 같은 일이 벌어집니다.
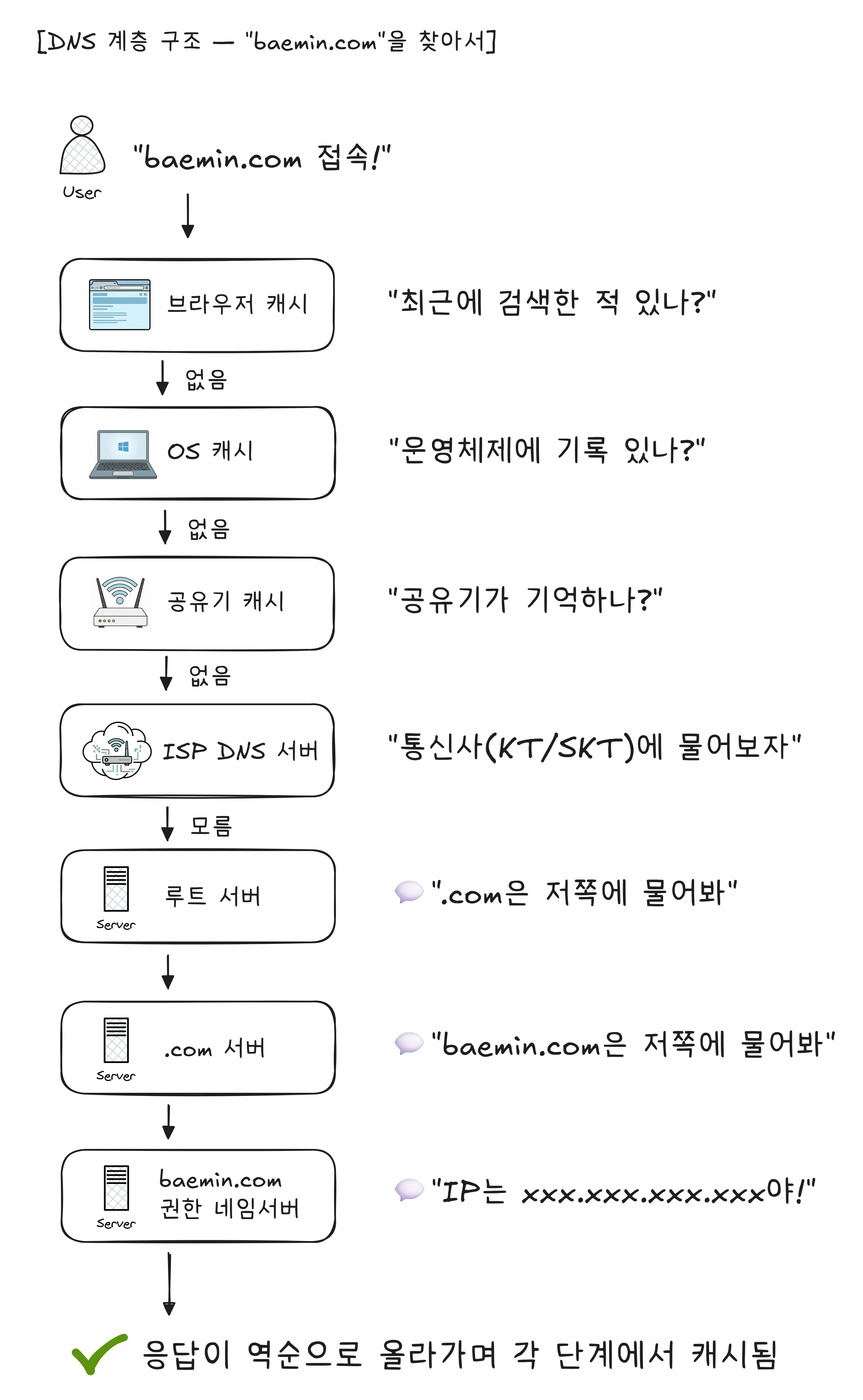
브라우저 캐시부터 OS, 공유기, ISP DNS 서버를 거치고, 그래도 모르면 루트 네임서버 → TLD1 네임서버 → 권한 네임서버까지 질문이 올라갑니다. 한 번 검색한 도메인은 각 단계에서 일정 시간 동안 기억해 둡니다. 그래서 두 번째 접속부터는 브라우저 캐시에서 바로 끝나는 경우가 많습니다. DNS가 느리다고 느끼지 못하는 이유입니다.
이 전체 과정이 보통 수십 밀리초 안에 끝납니다. 눈 깜짝할 사이에.
루트 서버: 인터넷의 출발점 13개
DNS 계층의 맨 꼭대기에는 루트 네임서버가 있습니다. 전 세계에 이름이 딱 13개입니다. A부터 M까지.

왜 13개뿐일까요? 기술적인 이유가 있습니다. DNS가 처음 설계될 때 응답 패킷의 크기가 512바이트로 제한되어 있었습니다. 이 안에 넣을 수 있는 서버 정보가 최대 13개였습니다. 그래서 13개가 된 것입니다.
하지만 “13개“는 이름이 13개라는 뜻이지, 물리적 서버가 13대라는 뜻은 아닙니다. 실제 서버는 전 세계에 수백 대 분산되어 있습니다. 애니캐스트(Anycast) 라는 기술을 사용해서, 같은 IP 주소를 여러 위치에 배치합니다. 질문을 보내면 지리적으로 가장 가까운 서버가 자동으로 응답합니다.
서울에서 루트 서버에 질문하면 미국까지 가는 게 아니라, 서울에 있는 루트 서버 미러가 응답하는 겁니다.
라우터: 갈림길의 이정표
DNS가 목적지의 IP 주소를 알려줬습니다. 이제 데이터를 그 주소로 보내야 합니다.
그런데 인터넷은 하나의 직선 도로가 아닙니다. 수십억 개의 기기가 거미줄처럼 연결된 네트워크입니다. 데이터가 출발지에서 목적지까지 도달하려면, 중간중간 갈림길에서 “이쪽으로 가“라고 안내해주는 존재가 필요합니다.
이 안내 역할을 하는 장비가 라우터(Router) 입니다.
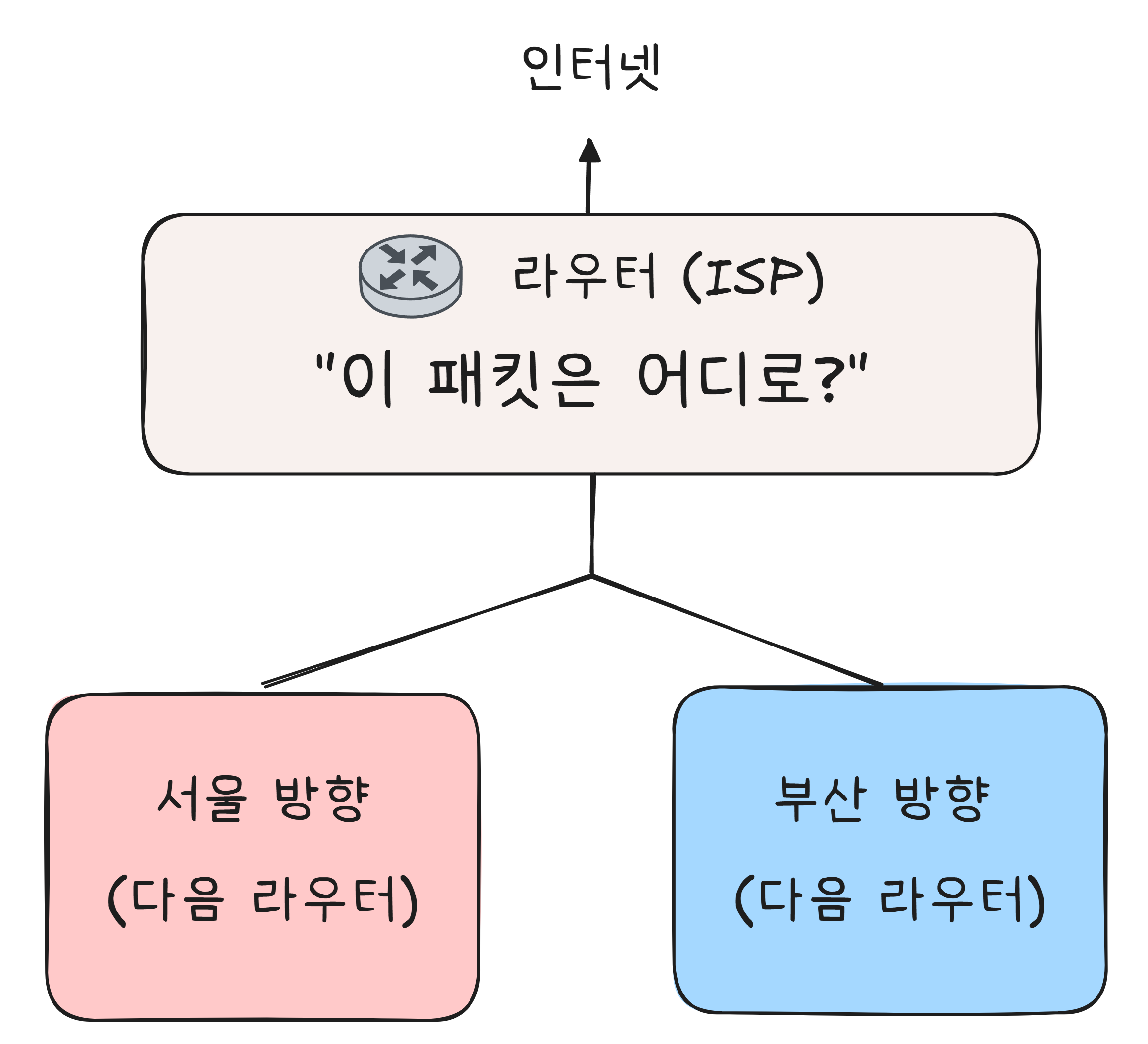
라우터는 라우팅 테이블이라는 지도를 갖고 있습니다. “이 목적지로 가는 데이터는 이쪽 방향으로 보내라“는 안내표입니다.
| 목적지 | 다음 라우터 |
|---|---|
| 10.0.0.0/8 | 직접 연결 |
| 172.16.0.0/16 | 192.168.1.1 |
| 기본 (그 외 전부) | 203.0.113.1 |
여기서 핵심이 있습니다. 라우터는 최종 목적지까지의 전체 경로를 알지 못합니다. 오직 “다음 라우터가 누구인지“만 압니다. 마치 릴레이 경주에서 바통을 넘기듯, 한 라우터가 다음 라우터에게 데이터를 넘기고, 그 라우터가 또 다음 라우터에게 넘기고… 이렇게 한 다리, 두 다리 건너면서 목적지에 도달합니다.
내비게이션처럼 출발지에서 목적지까지 전체 경로를 미리 계산하는 것이 아니라, 매 갈림길에서 “다음엔 저쪽“이라는 판단만 내리는 방식입니다.
traceroute: 데이터의 여행 경로를 눈으로 보기
이 과정을 직접 확인하는 방법이 있습니다. 컴퓨터의 명령 프롬프트(터미널)를 열고 tracert google.com(Windows) 또는 traceroute google.com(Mac/Linux)을 입력해 보세요. 다음과 같은 결과가 나옵니다.
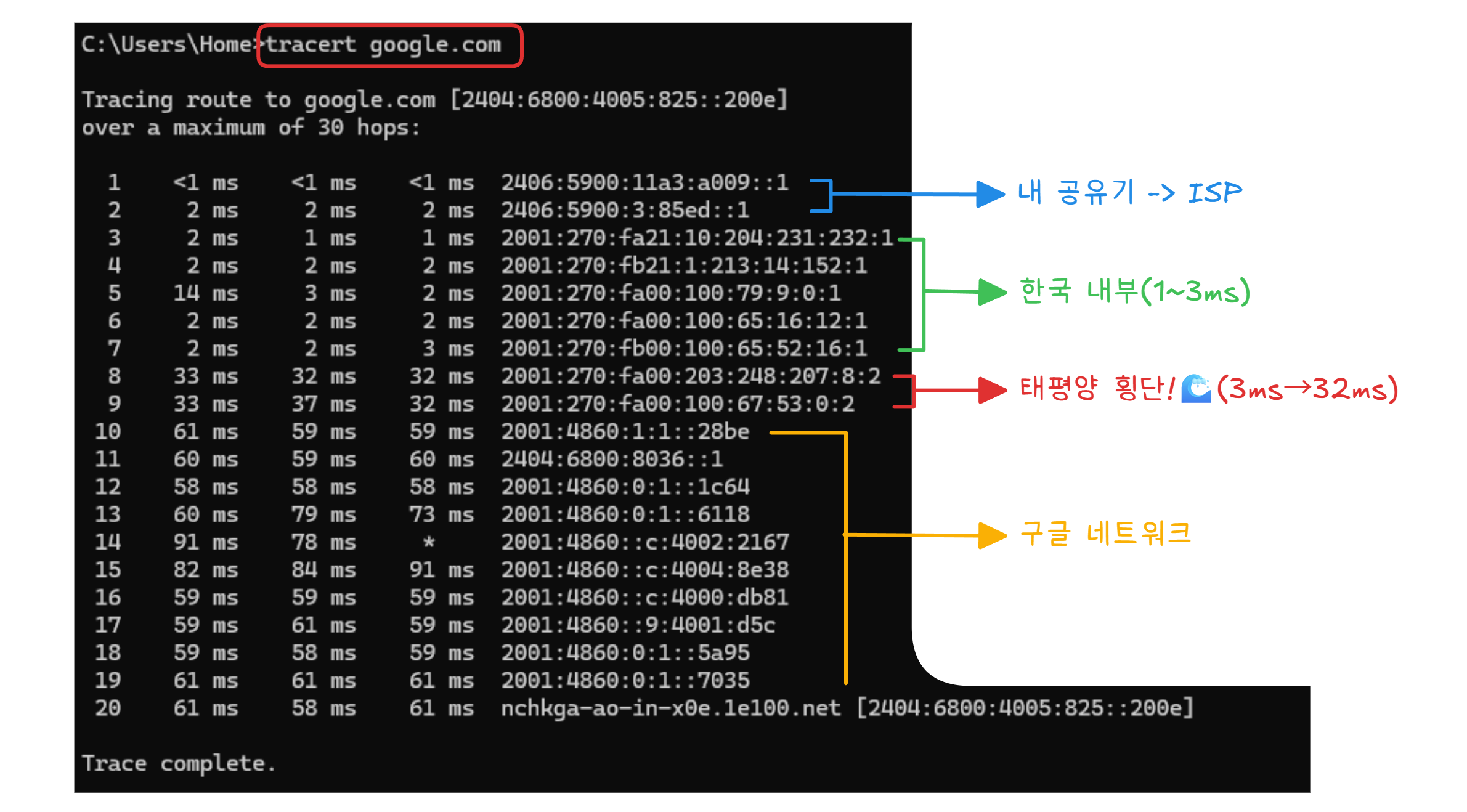
여러분의 데이터가 약 20개의 라우터를 거쳐 구글에 도착했습니다. 서울에서 태평양을 건너 약 60밀리초. 눈 한 번 깜빡이는 시간의 6분의 1입니다.
7번과 8번 사이에서 응답 시간이 3ms에서 32ms로 훌쩍 뛰는 구간이 보입니다. 이 구간이 바로 태평양 해저케이블을 지나는 지점입니다. 4장에서 이야기한 그 케이블 말입니다. 물리적 거리가 시간으로 드러나는 순간입니다.
중간에 * * *로 표시되는 구간이 있을 수도 있습니다. 해당 라우터가 보안상 자기 존재를 숨기는 것입니다. 길은 있지만 이정표를 가린 것과 같습니다.
BGP: 인터넷 전체의 내비게이션
라우터가 갈림길의 이정표라면, 한 단계 위의 이야기를 해야 합니다.
인터넷은 하나의 거대한 네트워크가 아닙니다. KT, SKT, LG U+, 구글, 아마존, 페이스북… 각 기관이 자체적으로 운영하는 네트워크들이 서로 연결된 구조입니다. 이 개별 네트워크를 AS(Autonomous System, 자율 시스템) 라고 합니다.
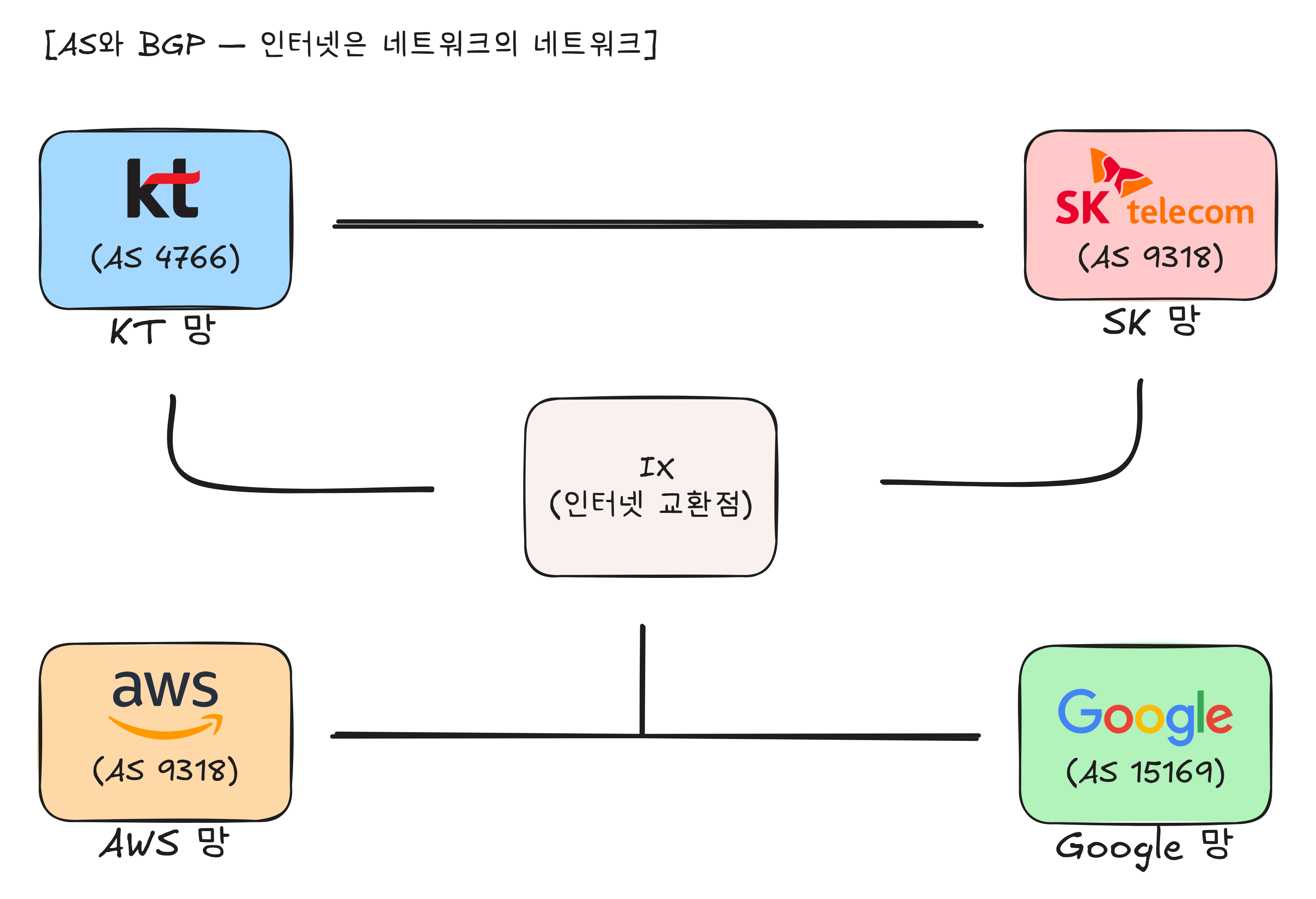
이 AS들 사이에서 “내 쪽으로 오면 어디어디에 갈 수 있어“라는 경로 정보를 교환하는 프로토콜이 BGP(Border Gateway Protocol) 입니다.
BGP는 인터넷 전체의 내비게이션 시스템입니다. 개별 라우터의 라우팅 테이블이 동네 길 안내판이라면, BGP는 도시 간, 국가 간 고속도로 표지판입니다.
BGP가 중요한 이유는 이겁니다. 인터넷에서 “구글 서버까지 어떻게 갈까?“를 결정하는 것이 결국 BGP입니다. KT 망에서 시작한 데이터가 어느 경로를 따라 구글의 AS에 도달할지, 그 판단을 BGP가 내립니다.
BGP에서는 이렇게 경로 정보를 주변에 알리는 것을 “광고(advertise)” 라고 합니다. 마케팅 광고가 아닙니다. “이 IP 주소로 가려면 내 쪽으로 보내“라고 이웃 네트워크에 알려주는 것입니다. 각 AS는 자기가 도달할 수 있는 IP 범위를 BGP로 광고하고, 이 광고가 인터넷 전체로 퍼지면서 경로가 만들어집니다.
그런데 BGP에는 치명적인 약점이 있습니다.
사건 1: Facebook이 인터넷에서 사라진 날 (2021)
2021년 10월 4일, 페이스북 엔지니어가 백본2 라우터 설정을 변경하던 중 실수를 저지릅니다. 자사의 BGP 경로를 전부 철회한 것입니다.3
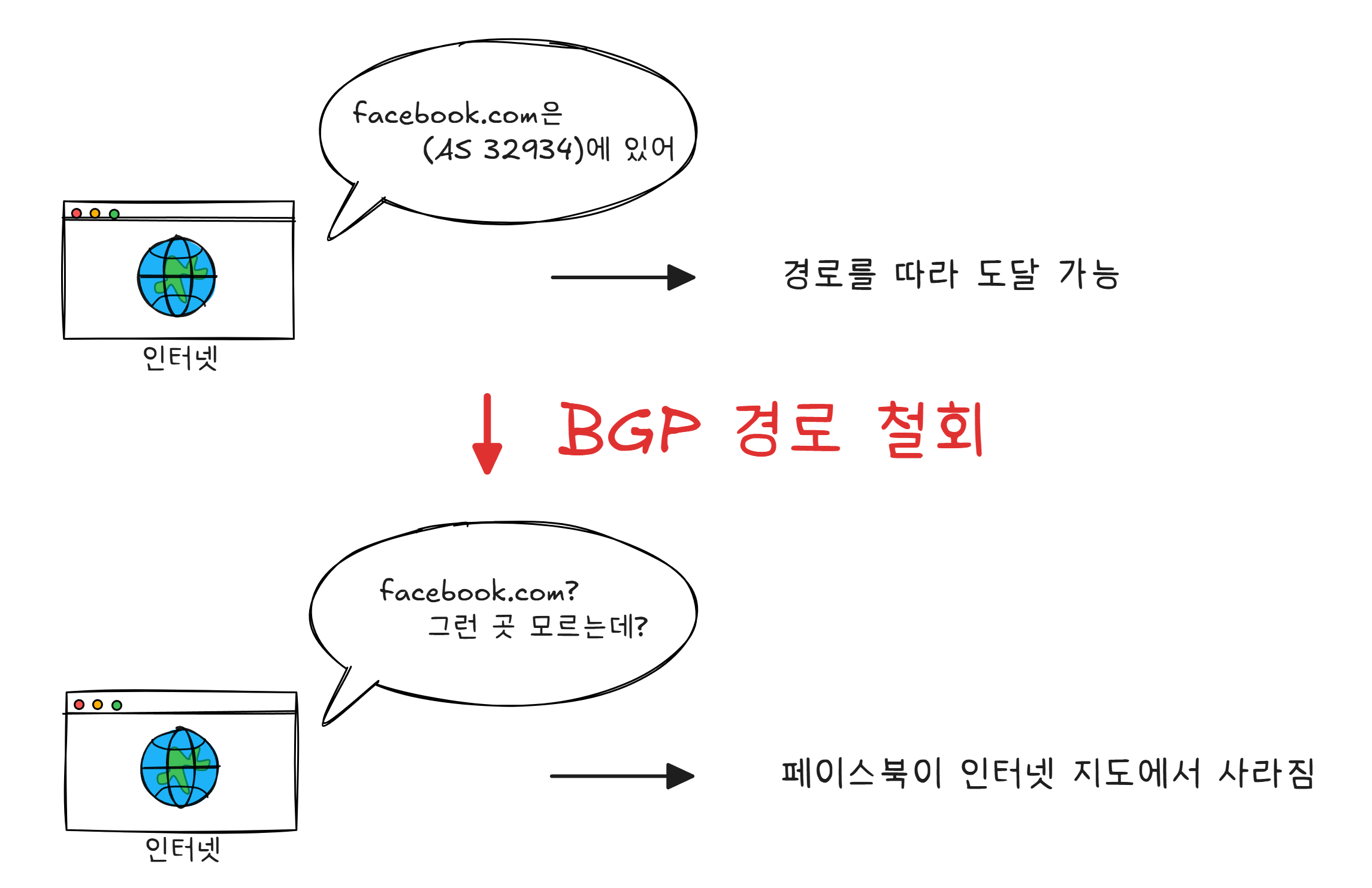
페이스북, 인스타그램, 왓츠앱이 동시에 다운되었습니다. 6시간 동안.
DNS도 함께 죽었습니다. BGP 경로가 사라졌으니 페이스북의 DNS 서버에도 도달할 수 없었습니다. facebook.com이라는 이름 자체가 어떤 숫자로도 변환되지 않는 상태가 된 겁니다.
원격 복구가 불가능했습니다. 복구를 위해 접속해야 하는 시스템이 페이스북 네트워크 안에 있었으니까요. 엔지니어들이 물리적으로 데이터센터에 가야 했습니다.
그런데 데이터센터 문을 여는 전자 배지 시스템도 페이스북 네트워크에 의존하고 있었습니다. 문이 안 열린 겁니다.
결국 물리적으로 자물쇠를 깨고 들어갔다는 후문이 있습니다.
마크 저커버그의 개인 자산은 이날 하루에 약 7조 원 감소했습니다. 주가 폭락 때문이었습니다.
설정 변경 하나가 세계 최대 소셜 네트워크를 6시간 동안 지구상에서 증발시켰습니다.
사건 2: 한 나라의 실수가 전 세계 유튜브를 멈추다 (2008)
2008년 2월, 파키스탄 정부가 자국 내에서 유튜브를 차단하기로 결정합니다. 파키스탄 텔레콤은 BGP를 이용해 “유튜브 IP 범위는 내 쪽으로 보내“라고 광고했습니다. 자국 내에서만. 받은 데이터는 버렸습니다. 블랙홀 라우팅이라고 불리는 방식입니다.
문제는 이 BGP 광고가 자국 밖으로 전파된 것입니다.
파키스탄이 의도한 것은 자국 내 차단이었습니다. 하지만 실제로 벌어진 일은 달랐습니다.
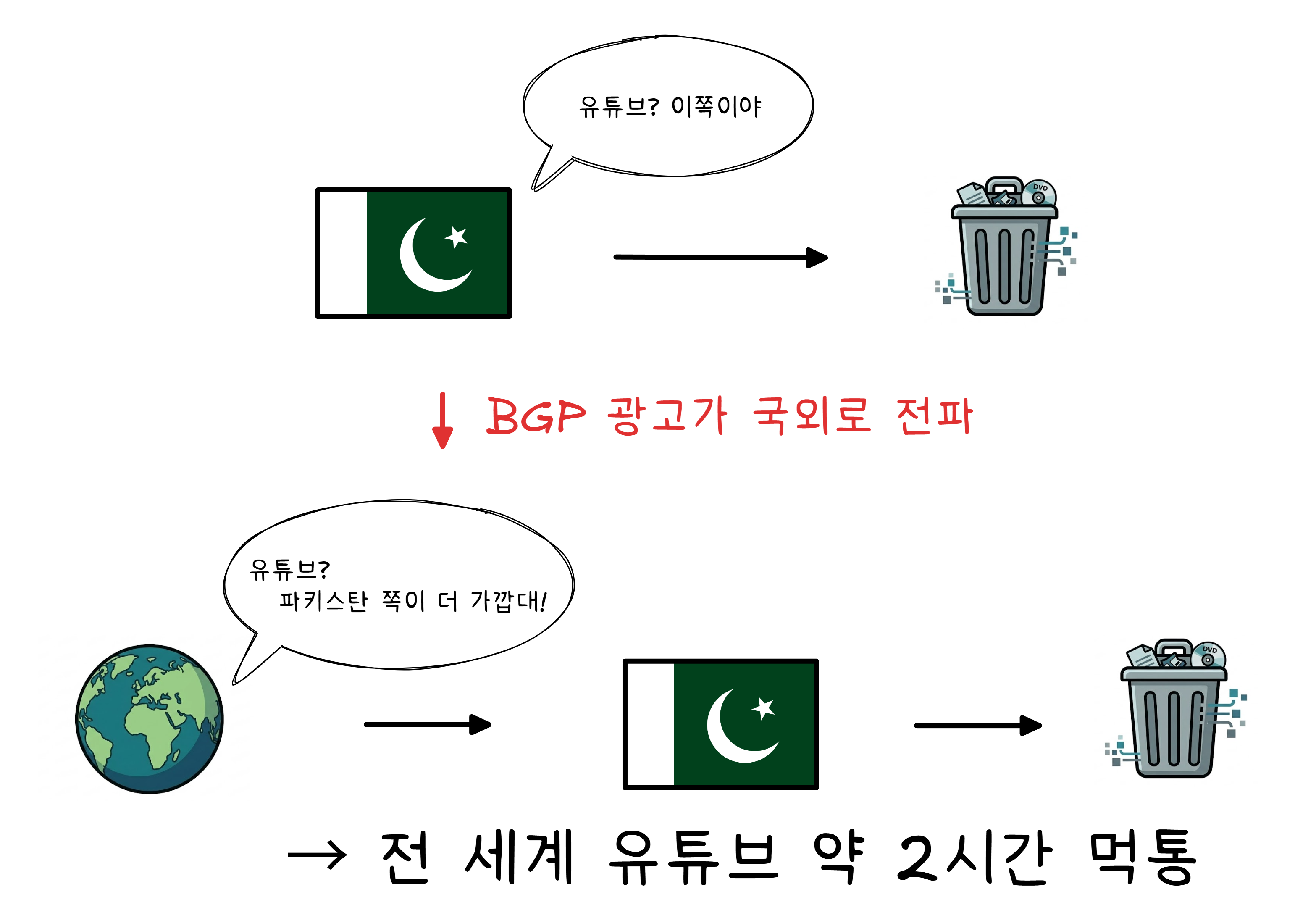
전 세계의 유튜브 트래픽이 파키스탄으로 빨려 들어가서 사라졌습니다.4
이 사건이 가능했던 이유가 있습니다. BGP는 원래 “이 광고가 진짜인가?“를 검증하는 메커니즘이 없었습니다. 1989년에 설계되었을 때, 인터넷에 연결된 네트워크가 몇 천 개에 불과했고, 모두 대학과 연구기관이었습니다. 서로 신뢰하는 관계였으니 검증이 필요 없었습니다.
하지만 인터넷이 전 세계로 확장되면서, 이 신뢰 기반 시스템은 취약점이 되었습니다. 현재는 RPKI(Resource Public Key Infrastructure) 같은 보안 확장이 도입되고 있지만, 아직 모든 AS가 적용한 것은 아닙니다.
사건 3: Dyn DDoS — 전화번호부가 죽으면 (2016)
2016년 10월 21일, DNS 서비스 업체 Dyn이 대규모 공격을 받았습니다.5
공격 도구는 미라이(Mirai) 봇넷6이었습니다. 웹캠, 공유기, DVR 같은 IoT 기기 수십만 대가 악성코드에 감염되어 하나의 공격 네트워크로 묶여 있었습니다. 이 기기들의 공통점이 있었습니다. 출하 시 설정된 기본 비밀번호(admin/admin, 1234 등)를 바꾸지 않은 것입니다.
감염된 수십만 대의 기기가 동시에 Dyn의 DNS 서버에 쓰레기 요청을 쏟아부었습니다. DDoS(Distributed Denial of Service, 분산 서비스 거부) 공격입니다.
결과는 참혹했습니다. 트위터, 넷플릭스, 레딧, 깃허브, CNN, 스포티파이… 미국 동부의 주요 웹사이트가 일제히 접속 불가 상태에 빠졌습니다.
인터넷 자체는 살아있었습니다. IP 주소를 직접 입력하면 접속할 수 있었습니다. 하지만 전화번호부(DNS)가 죽었으니, 이름으로 접속하는 대부분의 사람들에게는 인터넷이 죽은 것과 다름없었습니다.
집에 있는 웹캠이나 공유기의 비밀번호를 바꾼 적이 없다면, 한번 확인해 보시기 바랍니다.
8.8.8.8 — “인터넷이 안 될 때“의 비밀번호
“인터넷이 안 되면 DNS를 8.8.8.8로 바꿔봐.”
IT 관련 커뮤니티에서 흔히 보이는 조언입니다. 8.8.8.8은 구글이 운영하는 공개 DNS 서버의 주소입니다.

통신사(ISP)의 DNS 서버가 느리거나 불안정할 때, 이 공개 DNS로 바꾸면 나아지는 경우가 있습니다. 구글의 DNS는 전 세계에 분산된 강력한 인프라로 운영되기 때문입니다.
Cloudflare의 1.1.1.1은 더 흥미로운 사연이 있습니다. 이 IP는 원래 APNIC(아시아태평양 IP 관리 기관) 소유였는데, 워낙 많은 사람이 테스트용 더미 IP로 1.1.1.1을 마구 입력하다 보니 정상적으로 활용이 불가능한 상태였습니다. Cloudflare가 APNIC과 파트너십을 맺어 DNS 서비스로 운영하고, APNIC은 그 트래픽 데이터를 연구에 활용하는 구조입니다.
알쓸신잡
-
최초의 인터넷 메시지는 “LO”: 1969년 10월 29일, UCLA에서 스탠포드로 세계 최초의 인터넷(ARPANET) 메시지를 보내려 했습니다. 전송하려던 단어는 “LOGIN“이었습니다. L을 보내고, O를 보내고… 시스템이 다운되었습니다. 결과적으로 인류 최초의 인터넷 메시지는 “LO” 가 되었습니다. 의도치 않게 “Lo and behold(보라!)“라는 영어 감탄사가 된 셈입니다.
-
“인터넷에 192.168.1.1을 치면?”: 브라우저에 192.168.1.1을 입력하면 남의 집이 아니라 내 공유기 설정 페이지가 열립니다. 사설 IP는 인터넷 밖으로 나가지 않고, 내 네트워크 안에서만 유효합니다. 공유기 제조사마다 기본 관리 페이지 주소가 다른데, 192.168.0.1이나 192.168.1.1이 가장 흔합니다. 여기서 WiFi 비밀번호를 바꾸거나, 연결된 기기 목록을 확인할 수 있습니다.
우리의 치킨 주문 데이터는 DNS로 배달의민족 서버의 주소를 찾았고, 라우터들의 릴레이를 통해 그 서버를 향해 출발했습니다. 그런데 데이터가 목적지에 도착하기만 하면 될까요? 중간에 데이터가 사라지면? 순서가 뒤바뀌면? 인터넷에는 데이터를 확실하게 전달하는 방법과, 빠르지만 좀 대충 보내는 방법이 있습니다.
-
TLD(Top-Level Domain): 최상위 도메인. .com, .net, .kr 같은 도메인 이름의 맨 끝 부분. ↩
-
백본(Backbone): 인터넷의 고속 중심 회선. 도로로 치면 고속도로에 해당한다. ↩
-
2021년 10월 4일, 약 6시간 동안 지속. — Engineering at Meta ↩
-
2008년 2월 24일, 약 2시간 동안 전 세계 유튜브 장애 발생. — RIPE NCC 분석 ↩
-
봇넷(botnet): 악성코드에 감염된 수많은 컴퓨터나 기기를 원격 조종하여 하나의 공격 네트워크로 활용하는 시스템. “로봇 네트워크(robot network)“의 줄임말. ↩
6장. 등기 택배와 전단지
“TCP, UDP, 포트, 방화벽”
이번 장에서 알게 될 것
- 인터넷에서 데이터가 빠짐없이 도착하는 원리
- 게임에서 “핑이 높다“는 것이 정확히 무슨 뜻인지
- 하나의 서버에서 웹, 메일, 게임이 동시에 돌아가는 비밀
- 카페 WiFi에서 남의 페이스북에 로그인할 수 있었던 시절
치킨 주문 여정: 데이터가 출발했다
DNS로 배달의민족 서버의 주소를 찾았습니다. 라우터들의 릴레이를 타고 데이터가 출발했습니다. 그런데 이 데이터가 정말로 도착할까요? 중간에 사라지면? 순서가 뒤바뀌면? 절반만 도착하면?
인터넷은 생각보다 불안정하다
5장에서 데이터가 라우터를 한 다리씩 거쳐 이동한다고 했습니다. 그 과정에서 데이터는 작은 조각으로 쪼개져서 보내집니다. 이 조각을 패킷(Packet) 이라고 합니다.
문제는 이 패킷이 언제나 안전하게 도착하는 것이 아니라는 점입니다. 네트워크가 혼잡하면 패킷이 버려질 수 있고, 다른 경로로 우회하면 순서가 뒤바뀔 수도 있습니다. 100개의 패킷을 보냈는데 98개만 도착하는 일은 흔합니다.
그래서 인터넷에는 두 가지 전송 방식이 있습니다. 하나는 느리더라도 확실하게 보내는 방식이고, 다른 하나는 빠르지만 보장은 없는 방식입니다.
택배로 비유하면 이렇습니다. 등기 택배와 전단지입니다.
TCP: 등기 택배
TCP(Transmission Control Protocol) 는 인터넷에서 가장 널리 쓰이는 전송 방식입니다.
등기 택배를 떠올려 보겠습니다. 등기 택배는 보내는 사람이 발송하고, 받는 사람이 수령 확인 서명을 합니다. 중간에 분실되면 재발송합니다. 느리지만 확실합니다.
TCP가 바로 이 방식입니다.

웹 브라우징, 이메일, 파일 다운로드 — “정확하게 도착해야 하는 것” 은 전부 TCP를 사용합니다. 여러분이 배달앱에서 치킨을 검색할 때, 그 검색 요청과 결과도 TCP로 전송됩니다. 메뉴 이름이 한 글자라도 빠지면 안 되니까요.
3-way Handshake: 통화 시작 전 “여보세요”
TCP 통신을 시작하기 전에는 반드시 연결 설정 과정을 거칩니다. 전화를 걸었을 때 “여보세요?“를 주고받는 것과 비슷합니다.
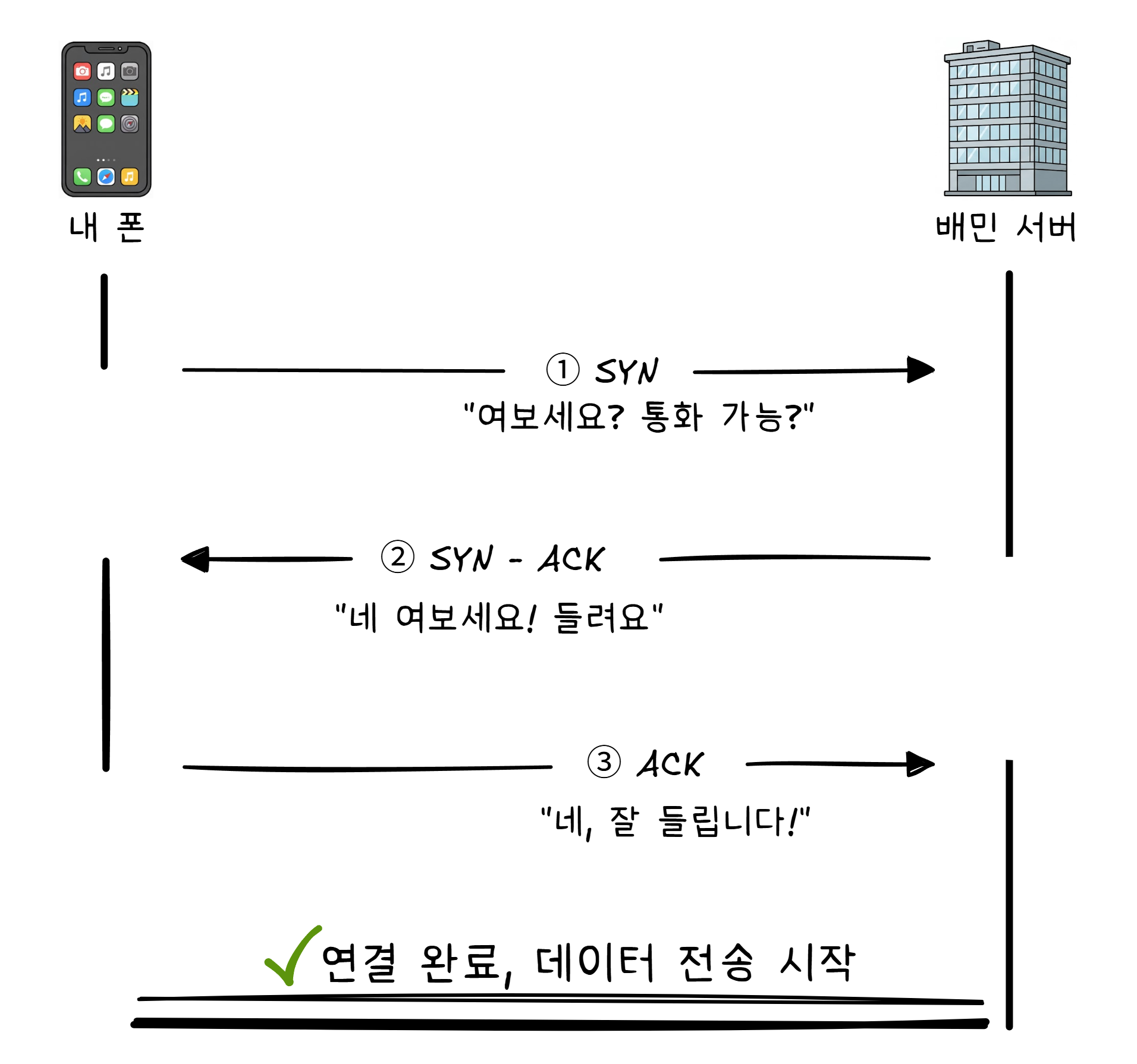
세 번 왕복합니다. 그래서 3-way Handshake1라고 합니다.
왜 세 번이나 왕복할까요? 양쪽 모두 “보내기“와 “받기“가 가능한지 확인하기 위해서입니다. 첫 번째로 클라이언트가 보낼 수 있는지, 두 번째로 서버가 보내고 받을 수 있는지, 세 번째로 클라이언트가 받을 수 있는지. 이 과정이 끝나야 비로소 데이터 전송이 시작됩니다.
전화를 걸었는데 상대가 “여보세요?“라고 안 하면, 연결이 안 된 걸로 판단하는 것과 같습니다.
슬로우 스타트: 다운로드가 처음에 느린 이유
파일을 다운로드할 때 처음에 느리다가 점점 빨라지는 걸 느낀 적 있을 겁니다.
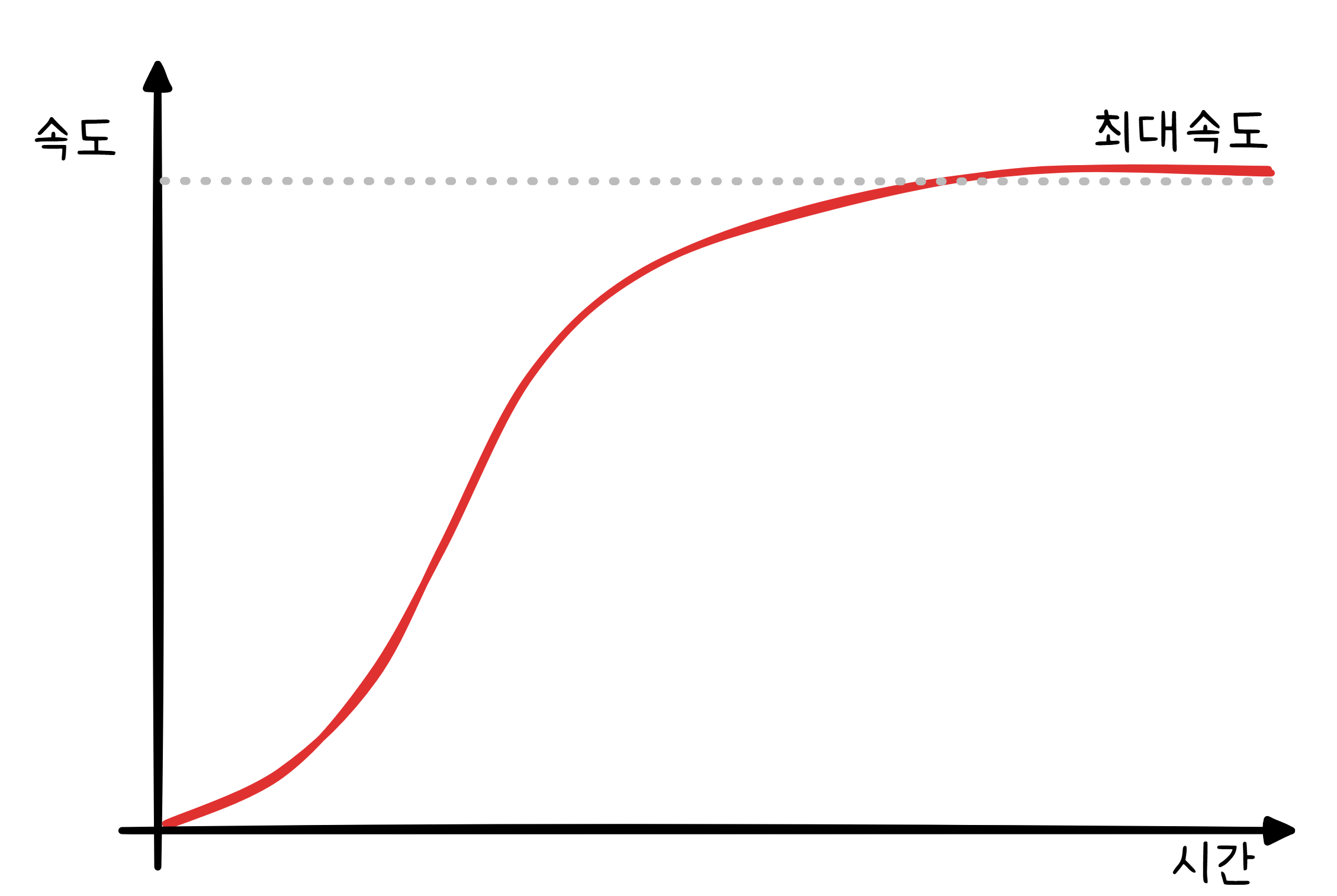
이것이 TCP의 슬로우 스타트(Slow Start) 입니다. 처음에는 패킷 1개를 보냅니다. 잘 도착하면 2개, 또 잘 도착하면 4개, 8개… 지수적으로 늘려갑니다.
처음부터 최대 속도로 쏟아부으면 네트워크가 감당 못 할 수 있습니다. 그래서 천천히 시작해서 “이 네트워크가 얼마나 버틸 수 있는지” 탐색하는 겁니다. 중간에 패킷 유실이 감지되면 속도를 확 줄이고 다시 천천히 올립니다.
고속도로에 진입할 때 서행으로 시작해서 점점 가속하는 것과 비슷합니다. 갑자기 최고 속도로 끼어들면 사고가 나니까요.
UDP: 전단지
이번에는 전단지를 생각해 보겠습니다. 전단지는 사람들에게 뿌리기만 합니다. 누가 받았는지 확인하지 않고, 받지 못한 사람에게 다시 돌아가서 주지도 않습니다. 빠르고 가볍지만, 전부 도착한다는 보장은 없습니다.
UDP(User Datagram Protocol) 가 이 방식입니다.

UDP는 어디에 쓸까요? “1초 전 데이터보다 지금 데이터가 중요한 것” 에 씁니다. 온라인 게임, 영상 통화, 라이브 스트리밍이 대표적입니다.
왜 게임은 UDP를 쓸까?
롤이나 발로란트 같은 게임에서 “핑이 높다“는 말을 들어봤을 겁니다. 핑(ping)은 데이터가 서버에 갔다 돌아오는 시간입니다. 이 게임들이 UDP를 사용하는 이유를 보면 핑의 중요성이 이해됩니다.
TCP로 게임을 만든다고 가정해 보겠습니다.
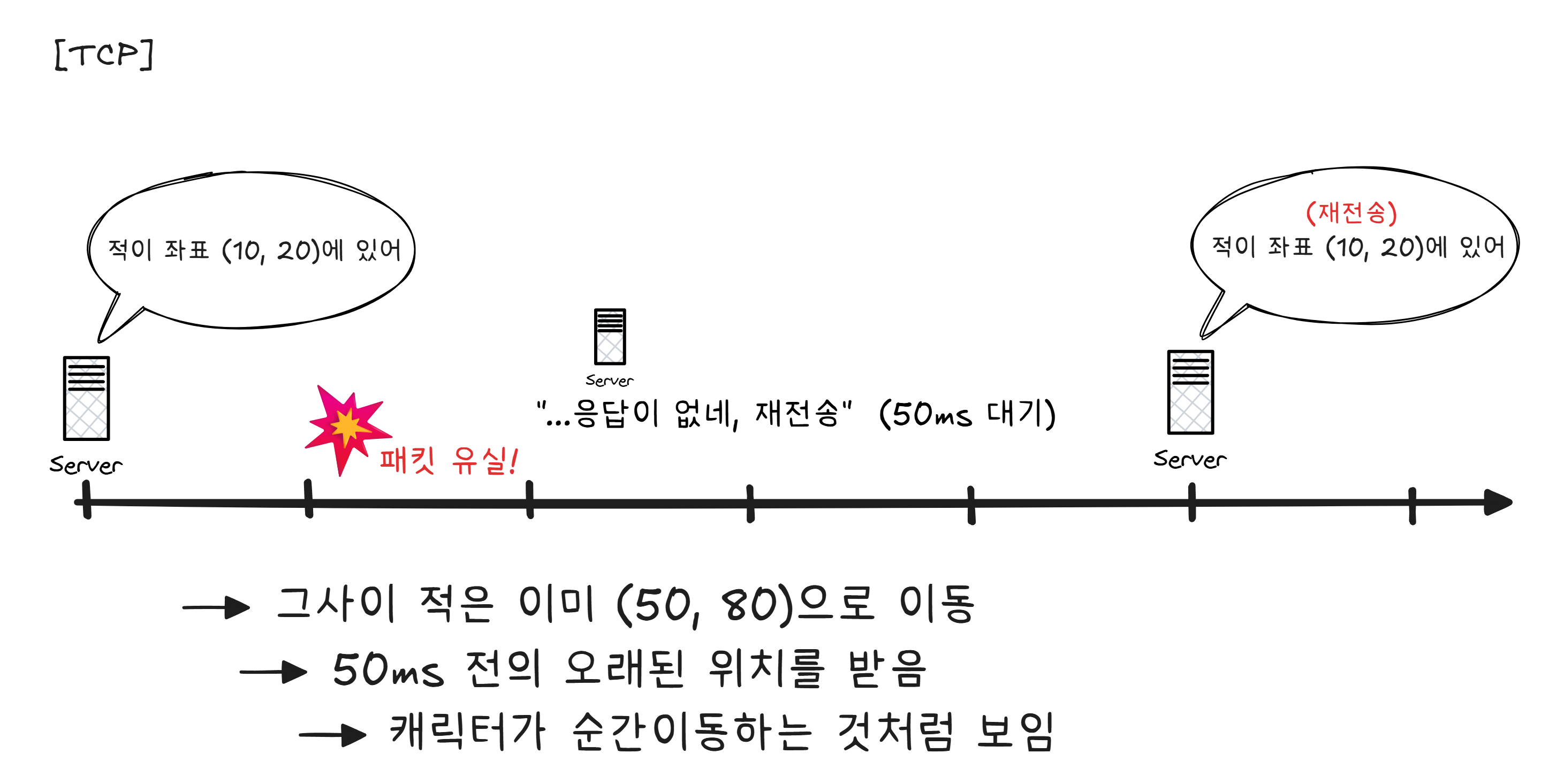
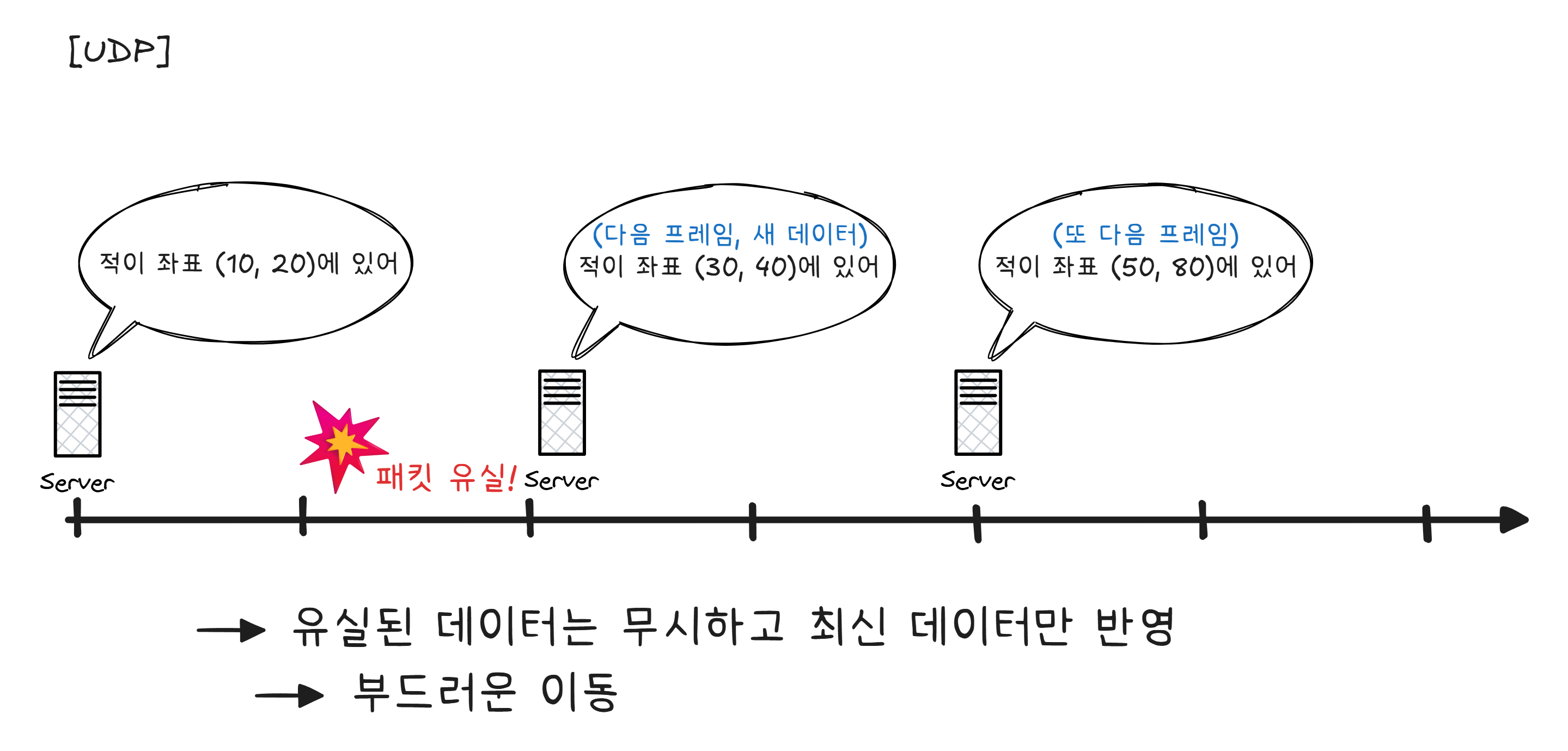
게임에서는 과거 데이터를 정확히 받는 것보다, 최신 데이터를 빨리 받는 것이 중요합니다. 0.05초 전 적의 위치를 정확히 알아봤자, 적은 이미 움직였으니까요.
영상 통화도 마찬가지입니다. 통화 중에 “여보…” “세…” 이렇게 끊기는 현상은 UDP 패킷이 유실된 것입니다. 유실된 음성을 재전송하면 더 지연되니까, 버리고 다음 음성을 재생합니다.
핑과 물리적 거리
게임에서의 핑은 곧 물리적 거리입니다. 빛의 속도에도 한계가 있기 때문입니다.
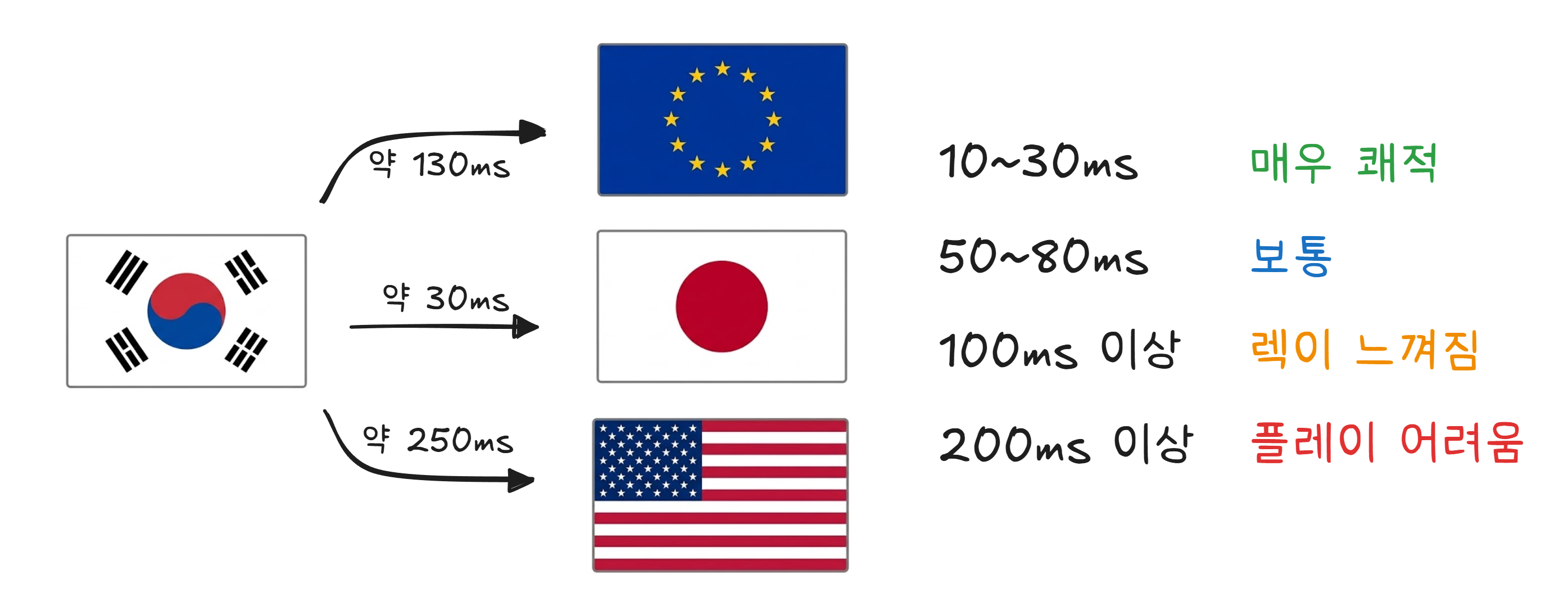
한국 서버에서 게임하면 핑이 낮고, 북미 서버에 접속하면 핑이 높은 이유입니다. 소프트웨어로 해결할 수 없는, 물리 법칙의 한계입니다. 4장에서 이야기한 해저케이블의 길이가 여기서도 영향을 줍니다.
TCP vs UDP: 한눈에 비교
| TCP (등기 택배) | UDP (전단지) | |
|---|---|---|
| 연결 설정 | 필요 (3-way) | 불필요 |
| 순서 보장 | O | X |
| 재전송 | O (유실 시) | X |
| 속도 | 상대적으로 느림 | 빠름 |
| 대표 사용처 | 웹, 이메일, 파일 | 게임, 영상통화 |
| 비유 | “확실하지만 느림” | “빠르지만 대충” |
배달앱에서 치킨을 주문하는 과정은 TCP입니다. 주문 데이터가 한 글자라도 빠지면 안 되니까요. 하지만 배달원의 실시간 위치를 지도에 표시하는 것은 UDP에 가깝습니다. 0.5초 전 위치보다 지금 위치가 중요하니까요.
포트: 같은 건물, 다른 창구
5장에서 IP 주소를 “건물 주소“에 비유했습니다. 그런데 하나의 서버(건물)에서는 웹 서비스, 이메일, 파일 전송, 데이터베이스 등 여러 프로그램이 동시에 돌아갑니다.
시청 민원실을 떠올려 보겠습니다. 같은 건물이지만 1번 창구는 주민등록, 2번 창구는 세금, 3번 창구는 인감증명을 처리합니다. 서버도 마찬가지입니다. 같은 IP 주소에서 여러 서비스가 돌아가고, 이것을 구분하는 것이 포트(Port) 번호 — 창구 번호입니다.
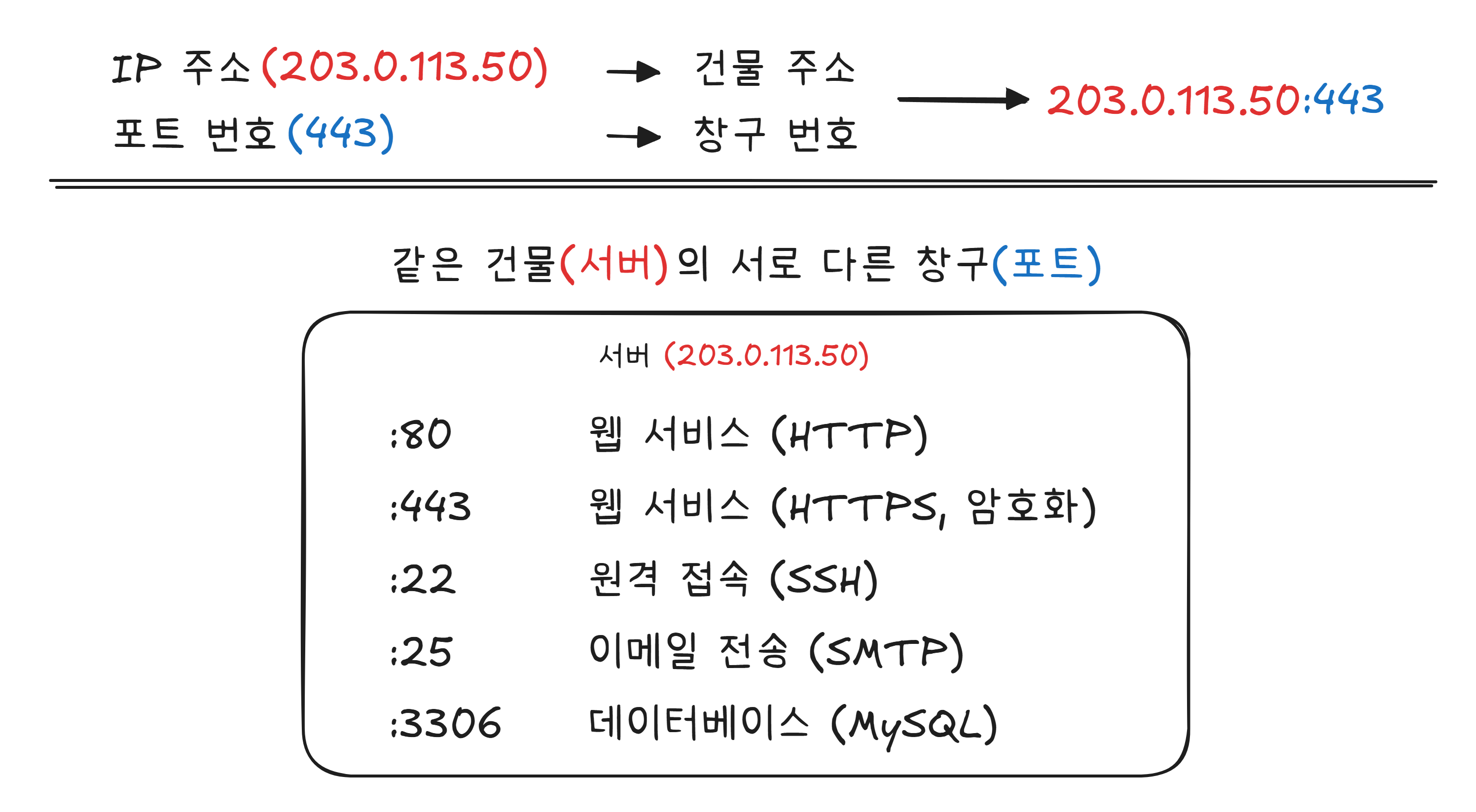
브라우저에서 웹사이트에 접속할 때, 주소창에는 baemin.com만 보이지만 실제로는 baemin.com:443으로 접속하고 있습니다. 브라우저가 HTTPS의 기본 포트인 443을 자동으로 붙여주는 겁니다.
왜 포트는 65535개까지인가?
TCP와 UDP 패킷의 헤더2에서 포트 번호는 16비트로 저장됩니다. 2^16 = 65,536. 0번은 예약이니 1번부터 65535번까지 사용 가능합니다.
| 포트 범위 | 분류 | 설명 |
|---|---|---|
| 0 ~ 1023 | 잘 알려진 포트 (Well-Known Ports) | HTTP(80), HTTPS(443), SSH(22) 등. 시스템이 예약해 둔 번호 |
| 1024 ~ 49151 | 등록된 포트 (Registered Ports) | MySQL(3306), PostgreSQL(5432) 등 |
| 49152 ~ 65535 | 동적 포트 (Dynamic Ports) | 운영체제가 임시로 할당하는 번호 |
방화벽: 건물 경비실
포트가 창구 번호라면, 방화벽(Firewall) 은 건물 입구의 경비실입니다.
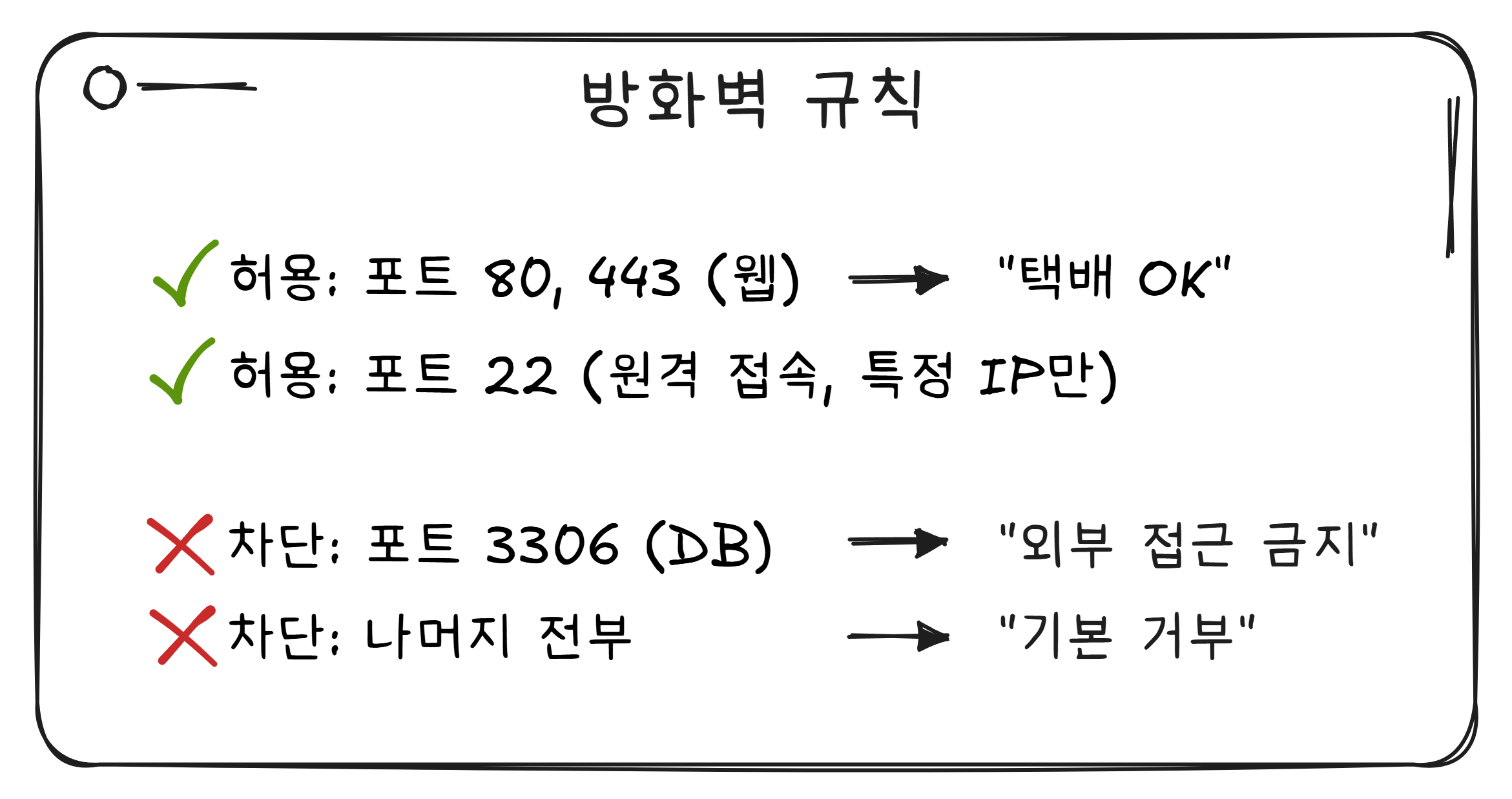
경비실에서 택배(웹 요청)는 통과시키고, 등록된 방문자(허가된 IP)도 통과시키지만, 신원 불명(알 수 없는 포트로의 접근)은 차단합니다.
여기서 중요한 개념이 있습니다. 방화벽은 내가 먼저 요청한 것의 응답은 허용합니다. 내가 구글에 접속 요청을 보냈으면, 구글에서 오는 응답은 통과시킵니다. 하지만 외부에서 아무 요청 없이 먼저 들어오는 것은 차단합니다.
윈도우에서 “이 앱이 네트워크에 액세스하는 것을 허용하시겠습니까?” 팝업이 뜨는 것, 그것이 방화벽입니다.
VPN: 암호화된 전용 터널
카페 WiFi에서 인터넷을 하면, 같은 네트워크에 있는 사람이 데이터를 엿볼 수 있습니다. 공유기를 지나가는 모든 데이터가 같은 네트워크를 거치기 때문입니다.
이 문제를 해결하는 것이 VPN(Virtual Private Network) 입니다.
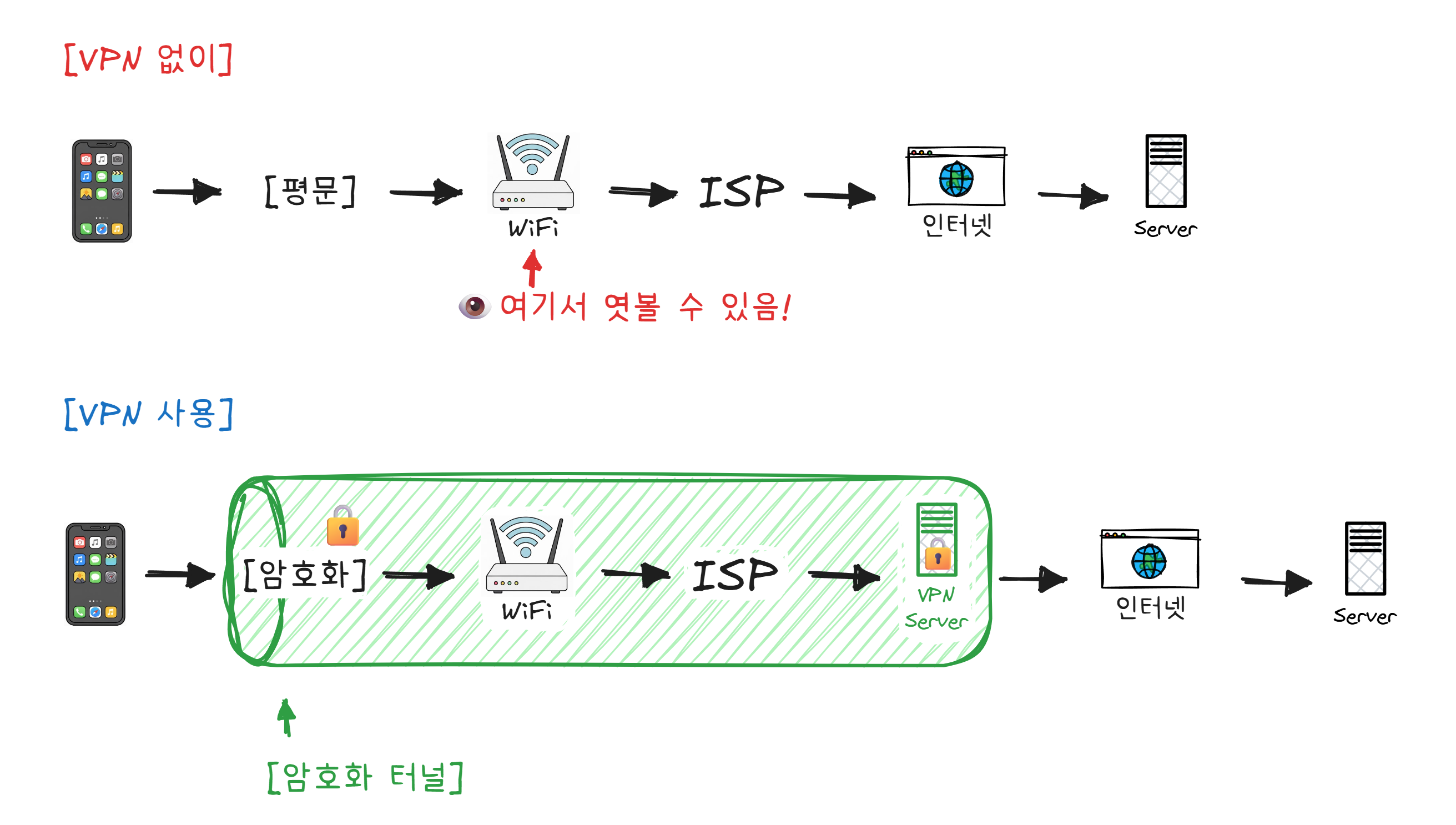
VPN은 인터넷 위에 암호화된 전용 터널을 만드는 기술입니다. 터널 안의 데이터는 암호화되어 있어서 중간에서 엿봐도 내용을 알 수 없습니다. 또한 VPN 서버의 IP 주소로 접속하기 때문에, 내 실제 IP도 숨겨집니다.
회사에서 재택근무할 때 VPN을 켜라고 하는 이유가 이겁니다. 집에서 회사 내부 네트워크에 안전하게 접속하기 위한 것입니다.
한 가지 주의할 점이 있습니다. VPN을 쓰면 ISP 대신 VPN 업체가 데이터를 볼 수 있습니다. 신뢰할 수 있는 업체를 선택해야 합니다. 무료 VPN은 특히 조심해야 합니다 — 여러분의 데이터가 “상품“일 수 있습니다.
사건: Firesheep — 카페에서 남의 페이스북에 로그인하다
2010년, 보안 연구원 에릭 버틀러가 Firesheep이라는 프로그램을 공개합니다.
이 프로그램의 기능은 충격적이었습니다. 같은 WiFi 네트워크에 있는 사람들의 로그인 세션을 가로채는 것이었습니다.
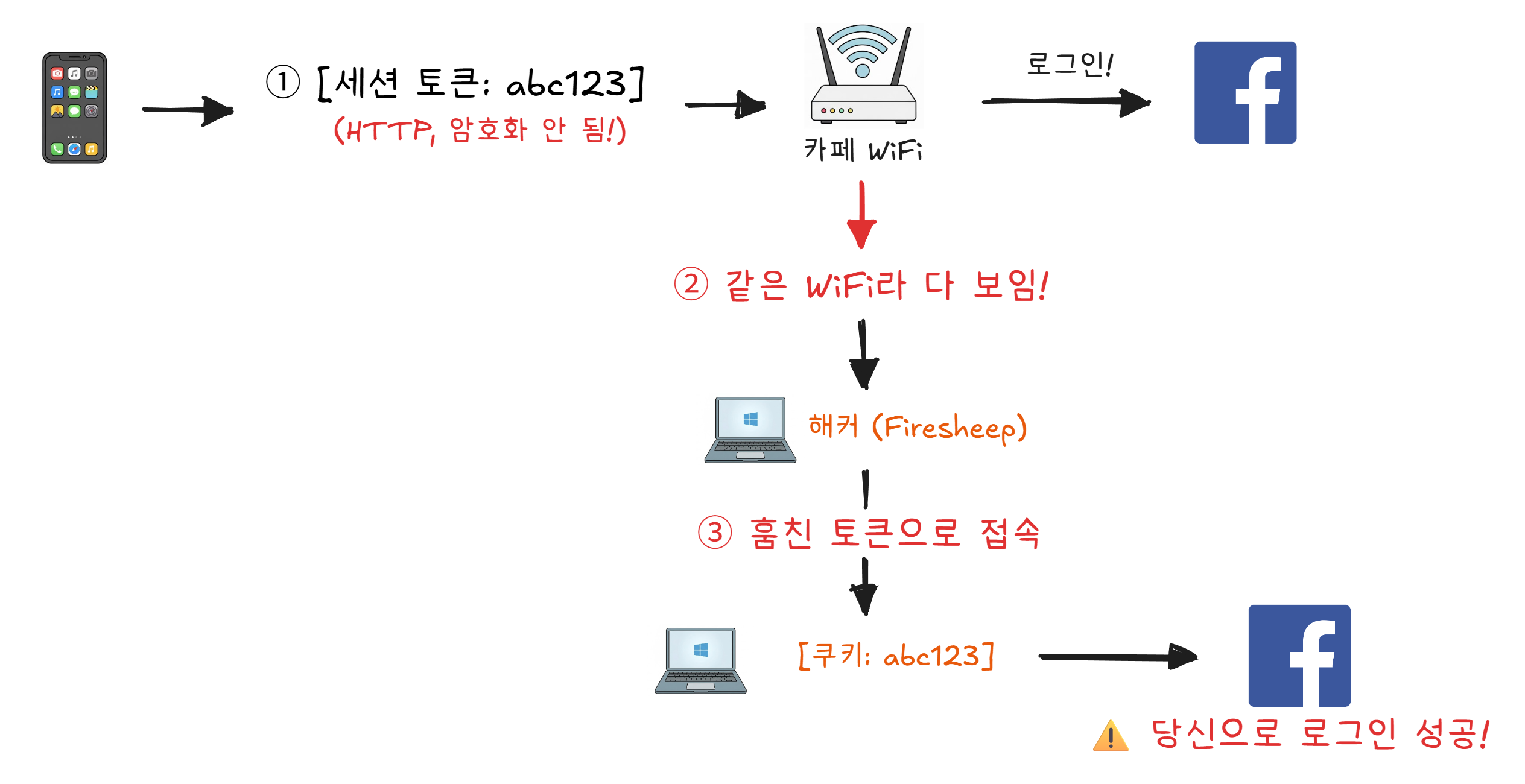
기술 지식이 없는 사람도 버튼 하나로 이 공격이 가능했습니다.
에릭 버틀러가 이 도구를 공개한 이유는 악용이 아니었습니다. 당시 페이스북, 트위터 같은 거대 서비스들이 여전히 HTTP(암호화 없음)를 사용하고 있다는 사실을 세상에 알리기 위해서였습니다.
효과는 강력했습니다. Firesheep 공개 이후 페이스북, 트위터 등 주요 서비스가 전면 HTTPS 도입을 서둘렀습니다.3 2015년에는 무료 HTTPS 인증서를 제공하는 Let’s Encrypt가 출범했고, 현재 웹 트래픽의 대부분이 HTTPS로 암호화되어 있습니다.
브라우저 주소창에 자물쇠 아이콘이 보이면, 그것이 HTTPS입니다. 카페 WiFi에서도 안전한 이유입니다. Firesheep이 세상을 바꾼 셈입니다.
알쓸신잡
-
ping의 어원은 잠수함 소나: 네트워크에서
ping명령어를 사용하면 데이터가 목적지에 갔다 돌아오는 시간을 측정합니다. 이 이름은 잠수함의 소나(SONAR) 에서 왔습니다. 잠수함이 “핑!” 소리를 보내고 반사음이 돌아오는 시간으로 물체까지의 거리를 계산합니다. 네트워크 ping도 같은 원리입니다 — 패킷을 보내고 돌아오는 시간(RTT4)을 측정합니다. -
“There’s no place like 127.0.0.1”:
127.0.0.1은 “나 자신“을 가리키는 특수한 IP 주소입니다.localhost라고도 합니다. 이 주소로 보낸 데이터는 네트워크 밖으로 나가지 않고 내 컴퓨터 안에서 돌아옵니다. 개발자들이 자기 컴퓨터에서 서버를 테스트할 때localhost:3000같은 주소를 쓰는 이유입니다. “There’s no place like 127.0.0.1“은 오즈의 마법사 명대사 “There’s no place like home(집만 한 곳은 없다)“에서 home을 127.0.0.1로 바꾼 개발자 유머입니다. -
500마일 이메일 전설: 실제로 일어난 일입니다. 어느 대학 시스템 관리자에게 교수가 “500마일(약 800km) 이상 떨어진 곳에 이메일을 보낼 수 없다“고 연락합니다. 말도 안 되는 소리라고 생각했지만, 테스트하니 진짜였습니다. 서버 업그레이드 중 이메일 서버의 타임아웃이 0ms로 초기화된 것이 원인이었습니다. 타임아웃 0ms는 “즉시 응답이 와야 한다“는 뜻인데, 광섬유에서 빛의 속도(약 200,000km/s)로 계산하면 왕복 0ms 이내인 거리가 약 500마일입니다. 그 이상은 빛이 왕복하는 데 1ms 이상 걸리므로 타임아웃 — 실패. 물리 법칙이 소프트웨어 버그가 된 순간입니다.
데이터가 TCP의 보호를 받으며 서버에 도착했습니다. 배달의민족 서버입니다. 우리가 “치킨“이라고 검색했으니, 서버는 수십만 개의 치킨집 중에서 우리에게 맞는 결과를 골라 보여줘야 합니다. 그런데 수십억 개의 데이터 중에서 원하는 것을 어떻게 0.3초 만에 찾아내는 걸까요?
-
Handshake: 악수. 네트워크에서는 통신을 시작하기 전에 양쪽이 준비 상태를 확인하는 절차를 뜻한다. ↩
-
헤더(Header): 패킷의 맨 앞에 붙는 정보 영역. 발신지, 수신지, 포트 번호 등 전송에 필요한 정보가 들어 있다. 편지의 봉투에 해당. ↩
-
2010년 10월 Firesheep 공개. — Eric Butler ↩
-
RTT(Round Trip Time): 데이터가 목적지에 갔다가 돌아오는 데 걸리는 왕복 시간. ↩
7장. 수십억 개의 웹페이지에서 0.3초 만에 찾기
“검색 엔진, 인덱싱, 알고리즘”
이번 장에서 알게 될 것
- 구글이 수십억 개의 웹페이지에서 0.3초 만에 결과를 보여주는 원리
- 인터넷의 모든 페이지를 수집하는 로봇이 실제로 존재한다는 것
- “검색 잘 되는 사이트“를 만들기 위한 보이지 않는 전쟁
- 배달앱에서 “치킨“을 검색하면 벌어지는 일
치킨 주문 여정: 서버에 도착했다
TCP의 보호를 받으며 데이터가 배달의민족 서버에 도착했습니다. 검색창에 “치킨“이라고 입력했습니다. 서버에는 수십만 개의 가게 정보가 있습니다. 이 중에서 우리에게 맞는 결과를 어떻게 골라낼까요?
책 한 권에서 “치킨“을 찾아라
구글에 뭔가를 검색하면 약 0.3초 만에 결과가 나옵니다. 수십억 개의 웹페이지 중에서입니다.
이것이 왜 놀라운지 이해하려면, 먼저 “검색“이 얼마나 어려운 일인지를 알아야 합니다.
도서관을 떠올려 보겠습니다. 100만 권의 책이 있는 도서관에서 “치킨 레시피“라는 단어가 들어간 책을 찾아야 합니다. 가장 단순한 방법은 1번 책부터 100만 번째 책까지 한 권씩 열어보는 것입니다. 이것을 순차 검색(Linear Search) 이라고 합니다. 최악의 경우 100만 권을 전부 확인해야 합니다.
사서라면 이렇게 하지 않을 겁니다. 책 뒤에 있는 “찾아보기(색인)” 를 펴겠죠.

“치킨“이라는 단어를 찾아서, 그 단어가 나오는 페이지 번호를 바로 확인합니다. 100만 권을 열어볼 필요 없이, 색인 하나를 펼치면 됩니다.
검색 엔진이 하는 일의 핵심이 바로 이것입니다. 인터넷 전체의 “찾아보기“를 미리 만들어 놓는 것입니다.
크롤러: 웹을 돌아다니는 로봇
색인을 만들려면 먼저 모든 책(웹페이지)을 읽어야 합니다. 이 일을 하는 것이 크롤러(Crawler) 입니다. 거미(spider)가 거미줄을 따라 돌아다니는 것처럼, 웹페이지의 링크를 따라 인터넷을 돌아다닌다고 해서 “웹 스파이더“라고도 합니다.
구글의 크롤러는 Googlebot이라는 이름을 가지고 있습니다.
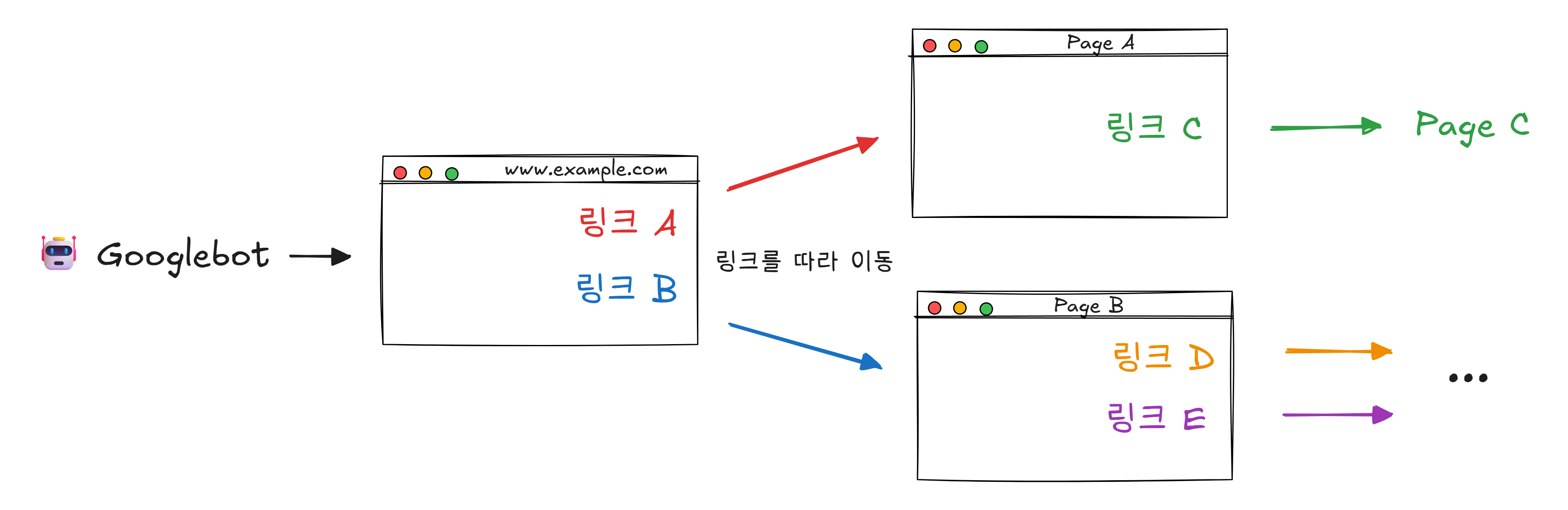
Googlebot은 하루에 수십억 개의 페이지를 방문합니다. 각 페이지의 내용을 읽고, 거기에 있는 링크를 목록에 추가하고, 다시 그 링크를 방문합니다. 이 과정을 끝없이 반복합니다.
그런데 인터넷에는 새로운 페이지가 매초 수천 개씩 생겨납니다. 기존 페이지도 수시로 내용이 바뀝니다. 크롤러는 새 페이지도 찾아야 하고, 이미 방문한 페이지도 주기적으로 다시 방문해서 변경사항을 확인해야 합니다.
중요한 페이지(뉴스 사이트, 대형 쇼핑몰)는 몇 분에 한 번씩, 덜 중요한 페이지는 며칠에 한 번씩 방문합니다. 이 우선순위를 정하는 것도 알고리즘입니다.
역 인덱스: 인터넷의 “찾아보기”
크롤러가 수집한 페이지로 만드는 것이 역 인덱스(Inverted Index) 입니다.
일반적인 인덱스(목차)는 “페이지 → 그 안에 있는 단어들“입니다. 역 인덱스는 반대입니다. “단어 → 그 단어가 있는 페이지들” 입니다.

“치킨“을 검색하면, 역 인덱스에서 “치킨“을 찾기만 하면 됩니다. 수십억 개의 웹페이지를 하나씩 열어볼 필요가 없습니다. 미리 만들어 놓은 “찾아보기“에서 해당 항목을 꺼내면 됩니다.
이것이 0.3초의 비밀입니다. 구글이 빠른 이유는 검색할 때 인터넷을 뒤지는 것이 아니라, 이미 정리해 놓은 목록에서 꺼내기만 하는 것이기 때문입니다.
물론 “치킨“이라는 단어가 포함된 페이지는 수억 개일 수 있습니다. 중요한 것은 이 중에서 어떤 페이지를 먼저 보여줄 것인가입니다.
PageRank: 투표로 중요도를 정하다
1996년, 스탠퍼드 대학원생 래리 페이지와 세르게이 브린은 하나의 아이디어를 냅니다.
“많은 페이지가 링크하는 페이지는 중요한 페이지다.”
이것이 PageRank1입니다. 구글의 시작이었습니다.
논문을 떠올려 보겠습니다. 학술 논문의 가치는 “얼마나 많은 다른 논문이 이 논문을 인용하는가“로 측정됩니다. 100편의 논문이 인용한 논문은, 2편만 인용한 논문보다 중요할 가능성이 높습니다.
웹페이지의 링크도 마찬가지입니다. 다른 페이지가 “이 페이지를 봐라“며 링크를 거는 것은 투표와 같습니다.
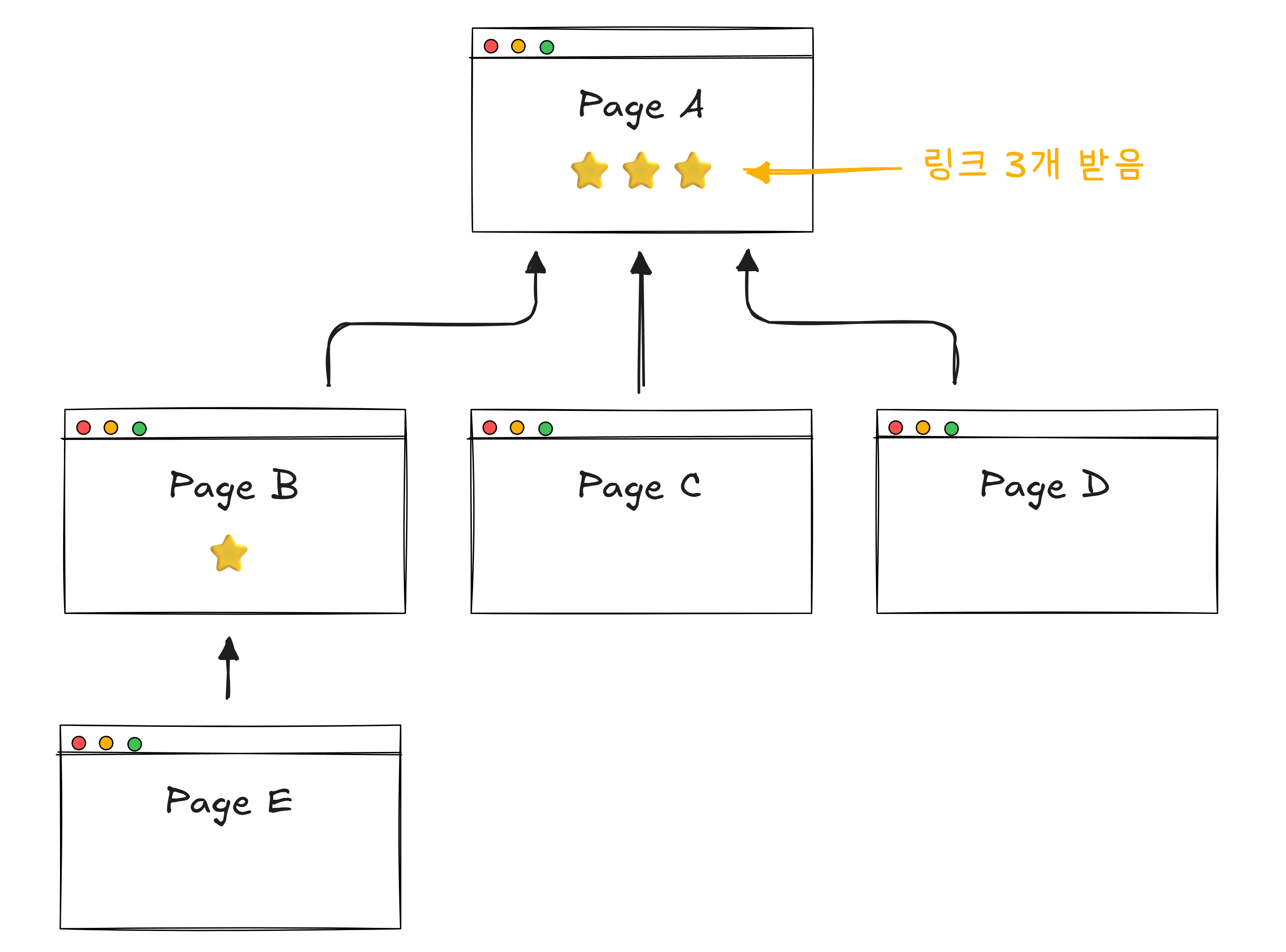
핵심은 “누가 링크했는가” 도 중요하다는 것입니다. 아무도 모르는 블로그가 링크하는 것보다, 뉴욕타임스가 링크하는 것이 더 높은 점수를 줍니다. 뉴욕타임스 자체가 이미 많은 링크(투표)를 받은 중요한 페이지이기 때문입니다.
PageRank 이전의 검색 엔진들은 “치킨“이라는 단어가 많이 나오는 페이지를 위에 보여줬습니다. 그래서 의미 없는 페이지에 “치킨 치킨 치킨 치킨…“을 도배하면 검색 상위에 올라갈 수 있었습니다. PageRank는 이 문제를 해결했습니다. 단어의 빈도가 아니라, 다른 페이지들의 “추천“으로 중요도를 판단하니까요.
물론 현재 구글의 검색 알고리즘은 PageRank 하나로 돌아가지 않습니다. 수백 개의 요소를 복합적으로 고려합니다. 검색어와의 관련성, 페이지의 최신성, 사용자의 위치, 모바일 친화성 등. 하지만 PageRank는 여전히 핵심 원리 중 하나이며, “링크 = 투표“라는 아이디어는 웹 검색의 패러다임을 바꿨습니다.
검색어 자동완성: 타이핑할 때마다 서버에 물어본다
배달앱에서 “치“를 입력하면 “치킨”, “치즈스틱”, “치즈볼“이 자동으로 나타납니다. “치ㅋ“까지 입력하면 “치킨“만 남습니다.
이것은 글자를 입력할 때마다 서버에 요청을 보내는 겁니다. “ㅊ” → 서버 요청 → “치” → 서버 요청 → “치ㅋ” → 서버 요청. 타이핑 속도에 맞춰 밀리초 단위로 응답이 와야 하므로, 자동완성은 검색 시스템에서 가장 빠른 응답 속도를 요구하는 기능 중 하나입니다.
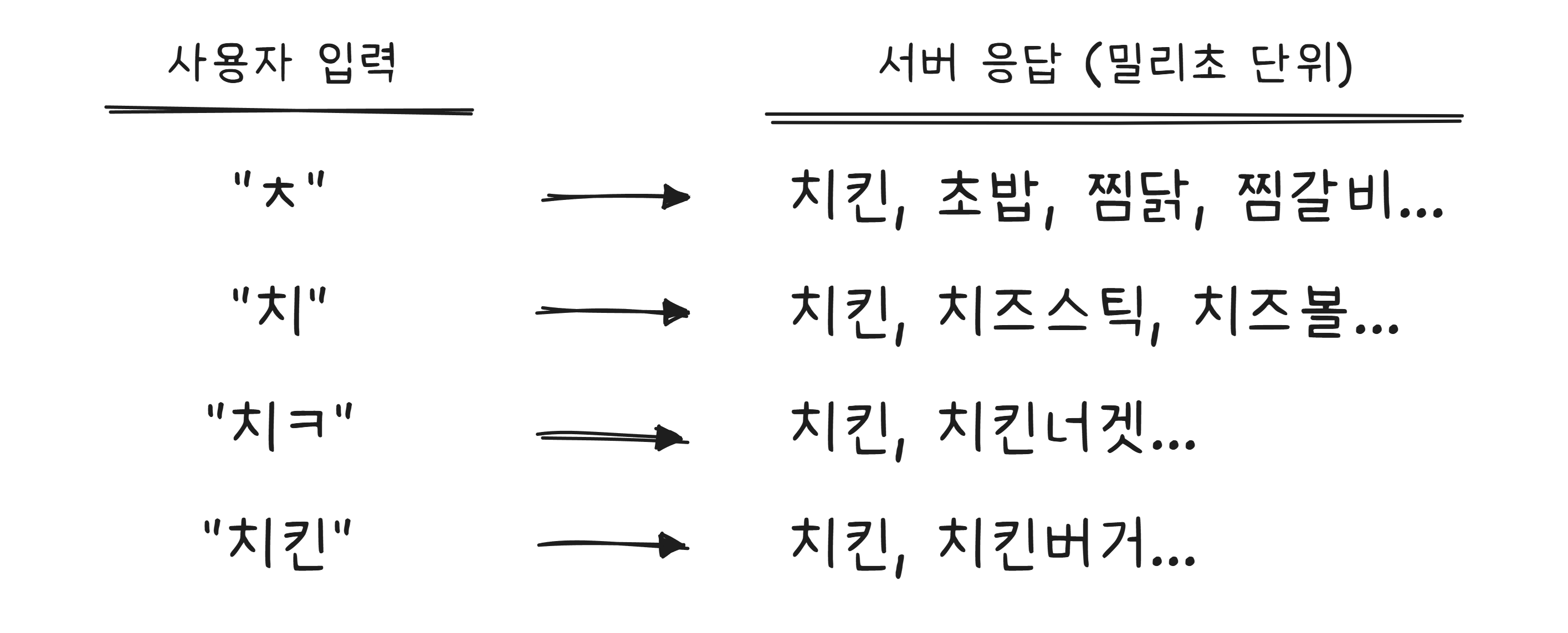
이 속도를 가능하게 하는 자료구조2가 트라이(Trie) 입니다. 트라이는 문자열을 한 글자씩 나무(트리) 형태로 저장합니다.
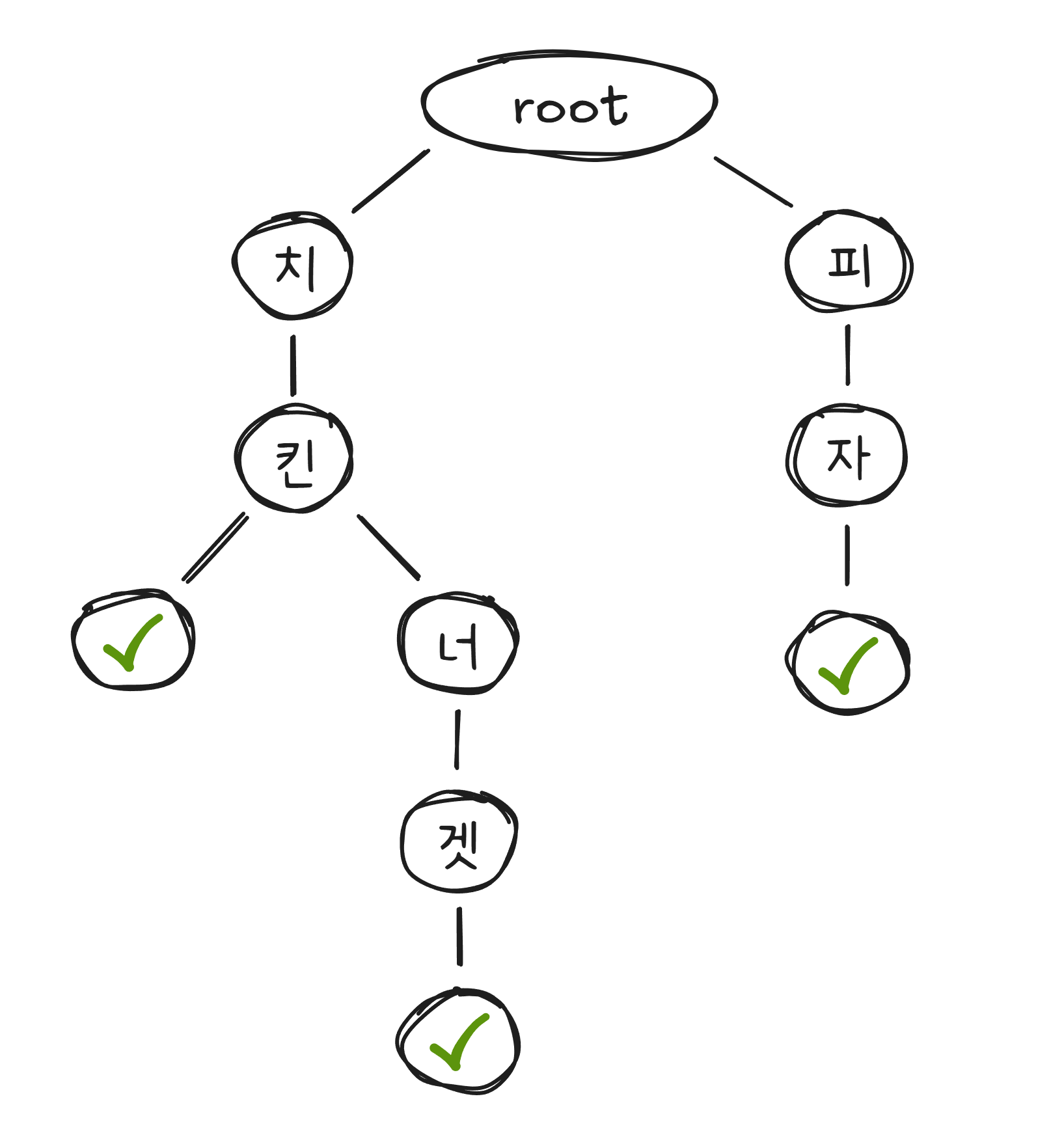
“치“까지 입력하면 트라이에서 “치” 노드로 이동하고, 그 아래에 달린 모든 단어를 후보로 보여줍니다. 처음부터 전체 목록을 검색하는 것이 아니라, 입력한 글자만큼만 트리를 따라 내려가면 되므로 매우 빠릅니다.
배달앱의 검색은 더 복잡하다
구글은 “치킨“을 검색하면 전 세계의 치킨 관련 페이지를 보여줍니다. 하지만 배달앱에서 “치킨“을 검색하면 내 주변 치킨집만 보여줍니다. 단순한 텍스트 검색이 아니라, 여러 조건을 동시에 고려해야 합니다.
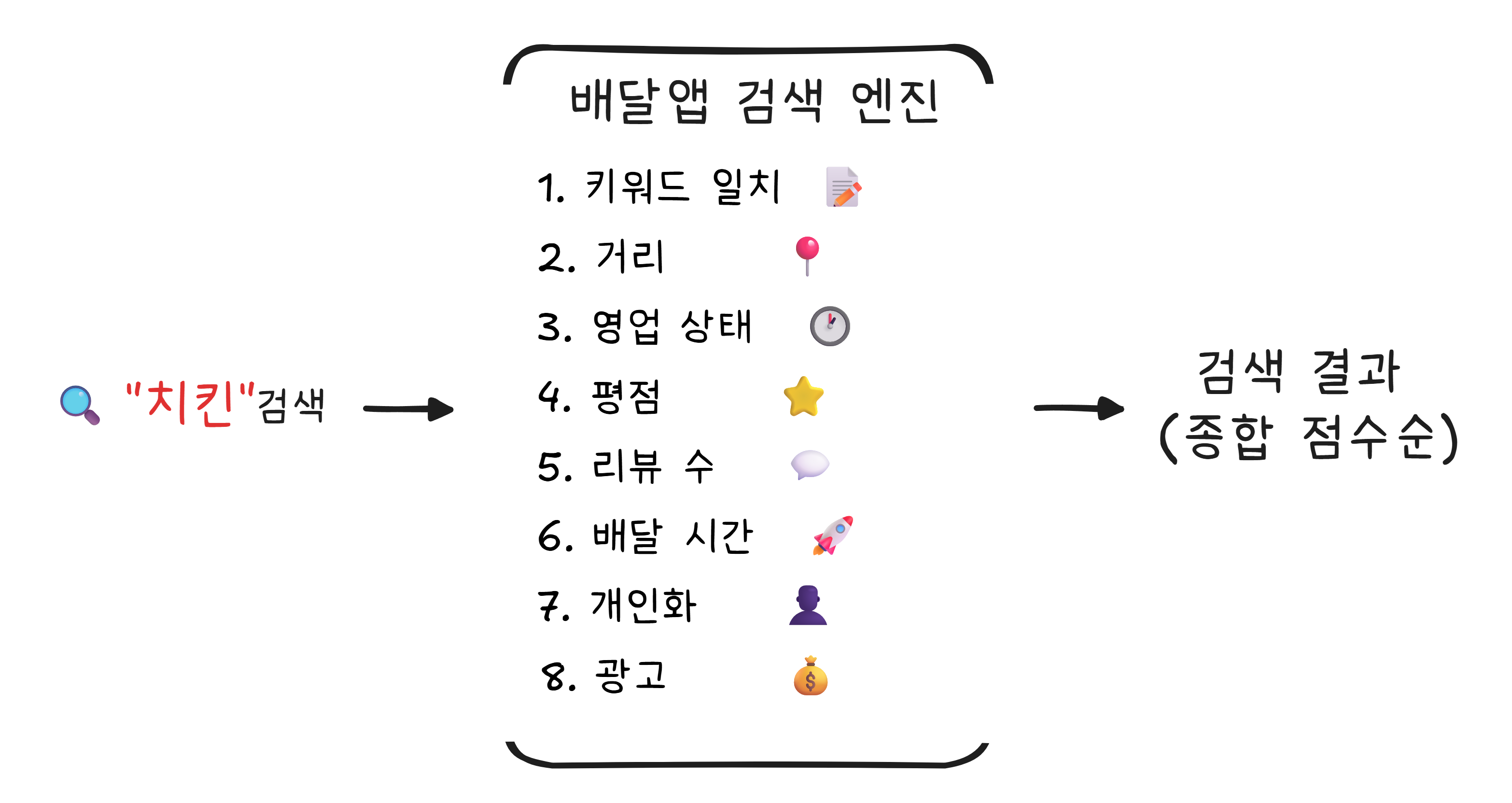
이 모든 조건에 가중치를 매기고, 종합 점수가 높은 순서대로 결과를 보여줍니다. 같은 “치킨“을 검색해도, 강남에서 검색하는 사람과 부산에서 검색하는 사람이 보는 결과는 완전히 다릅니다.
검색 결과의 맨 위에 “광고“라고 표시된 가게가 있는 것도 알고리즘의 일부입니다. 기본적으로는 관련성 순으로 정렬하되, 광고비를 낸 가게에게 상위 노출 기회를 주는 것. 이것이 배달앱의 수익 모델이기도 합니다.
사건: SEO 전쟁 — 검색 결과 1페이지를 차지하라
검색 결과의 첫 페이지에 나오는 것과 두 번째 페이지에 나오는 것은 하늘과 땅 차이입니다. 통계에 따르면 검색 사용자의 약 75% 가 첫 페이지 너머로 넘어가지 않습니다. “시체를 숨기기 가장 좋은 곳은 구글 검색 결과 2페이지“라는 우스갯소리가 있을 정도입니다.
그래서 SEO(Search Engine Optimization)3 전쟁이 벌어집니다.
초기 검색 엔진 시절에는 노골적인 수법이 통했습니다.
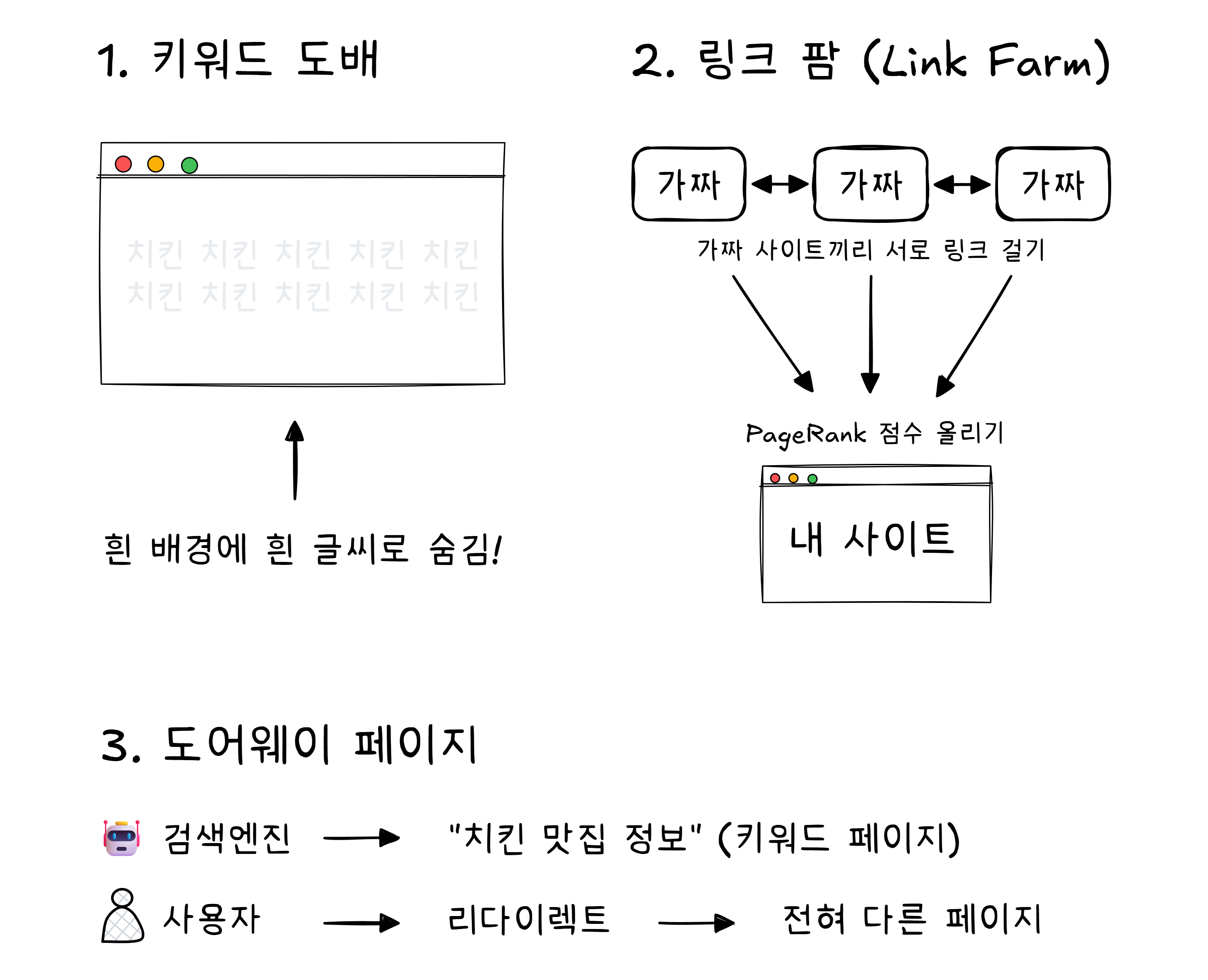
구글은 이를 막기 위해 알고리즘을 계속 업데이트합니다. 대표적인 것이 2011년의 판다 업데이트4와 2012년의 펭귄 업데이트5입니다. 판다는 저품질 콘텐츠를 걸러내고, 펭귄은 부정한 링크 조작을 감지합니다.
이 업데이트들이 적용될 때마다, 부정한 방법으로 상위에 올라와 있던 사이트들이 하루아침에 검색 결과에서 사라졌습니다. 어떤 기업들은 검색 유입이 90% 이상 급감해서 실질적으로 사업이 망하기도 했습니다.
현재도 이 전쟁은 계속되고 있습니다. 구글은 검색 알고리즘의 상세 내용을 공개하지 않으며, 매년 수천 번의 알고리즘 변경을 합니다. SEO 업계는 구글의 변경을 분석하고 대응합니다. 구글은 다시 새로운 대책을 내놓습니다. 검색 결과 1페이지를 둘러싼 이 보이지 않는 전쟁은 끝날 기미가 없습니다.
알쓸신잡
-
구글에서 가장 많이 검색하는 단어는 “youtube”: 전 세계에서 구글에 가장 많이 입력되는 검색어 1위는 “youtube“입니다. “google”, “facebook”, “amazon” 같은 사이트 이름도 최상위권입니다. 주소창에 URL을 직접 입력하는 대신 검색해서 들어가는 사람이 그만큼 많다는 뜻입니다. 웹 브라우저의 주소창과 검색창이 하나로 합쳐진 이유이기도 합니다.
-
“Google“이 동사가 된 날: 2006년, 옥스퍼드 영어 사전에 “google“이 동사로 등재됩니다. “Just google it(그냥 구글에 검색해 봐).” 브랜드 이름이 일반 동사가 된 드문 사례입니다. 한국에서도 “검색해 봐” 대신 “구글링해 봐“라는 표현을 쓸 정도로, 검색의 대명사가 된 사례입니다.
-
딥웹과 다크웹은 다르다: 구글 검색에 나오지 않는 인터넷 영역을 딥웹(Deep Web) 이라고 합니다. 이메일 받은편지함, 은행 계좌 페이지, 기업 내부 시스템 등 로그인해야 볼 수 있는 모든 페이지가 딥웹입니다. 전체 인터넷의 약 90~95% 가 딥웹입니다. 다크웹(Dark Web) 은 딥웹의 극히 일부로, Tor6 같은 특수 브라우저로만 접속 가능한 익명 네트워크입니다. 딥웹 자체는 위험한 것이 아닙니다 — 여러분의 이메일도 딥웹이니까요.
치킨집 검색 결과가 나왔습니다. 메뉴, 리뷰, 가격, 배달 예상 시간 — 화면에 보이는 이 정보들은 어디에 저장되어 있을까요? 수천만 사용자가 동시에 접속해도 데이터가 뒤섞이지 않는 이유는 무엇일까요?
-
PageRank: 래리 페이지(Larry Page)의 이름을 딴 알고리즘. “Page“는 웹페이지와 발명자의 이름을 동시에 의미하는 절묘한 이중 의미를 가진다. ↩
-
자료구조(Data Structure): 데이터를 효율적으로 저장하고 검색하기 위한 조직 방식. 사전의 가나다순 정렬, 도서관의 분류 체계 같은 것이 현실 세계의 자료구조다. ↩
-
SEO(Search Engine Optimization): 검색 엔진 최적화. 웹사이트가 검색 결과에서 더 높은 순위에 나오도록 개선하는 작업. ↩
-
구글 판다 업데이트 (2011). 저품질 콘텐츠 필터링. — Google Search Central Blog ↩
-
구글 펭귄 업데이트 (2012). 부정 링크 조작 감지. — Google Search Central Blog ↩
-
Tor(The Onion Router): 양파 라우터. 데이터를 여러 겹의 암호화로 감싸서 전송하는 익명 네트워크. 양파 껍질처럼 중간 단계마다 한 겹씩 벗겨지며, 최종 목적지만 전체 내용을 볼 수 있다. 이 기술을 기반으로 만들어진 “토르 브라우저(Tor Browser)“가 널리 알려져 있다. ↩
8장. 데이터를 담는 그릇
“데이터베이스, SQL, NoSQL”
이번 장에서 알게 될 것
- 배달앱의 수십만 가게 정보가 어디에, 어떻게 저장되는지
- “강남구에서 치킨 3번 이상 시킨 사람“을 한 줄로 찾는 방법
- 결제할 때 “내 돈만 빠지고 가게에는 안 들어가는” 사태를 막는 원리
- 2017년, 엔지니어 한 명의 실수로 데이터베이스가 통째로 날아간 사건
치킨 주문 여정: 검색 결과가 나왔다
검색 결과가 화면에 나타났습니다. 치킨집 목록, 메뉴 이름, 가격, 별점, 리뷰, 배달 예상 시간… 이 수많은 정보는 대체 어디에 저장되어 있을까요?
엑셀로는 안 되나요?
가장 먼저 떠오르는 것은 엑셀입니다. 엑셀은 데이터를 행과 열로 정리하는 도구이고, 실제로 많은 회사에서 데이터 관리에 사용합니다.
그런데 배달의민족에는 가게가 수십만 개, 메뉴는 수백만 개, 리뷰는 수억 개, 사용자는 수천만 명입니다. 이것을 엑셀로 관리할 수 있을까요?

수천만 명이 동시에 같은 데이터를 읽고 쓰는 상황 — 누군가는 리뷰를 쓰고, 누군가는 주문을 넣고, 누군가는 메뉴를 검색하고 — 이것은 엑셀이 감당할 수 있는 영역이 아닙니다.
이 문제를 해결하기 위해 만들어진 것이 데이터베이스(Database) 입니다.
데이터베이스: 거대한 서류 캐비닛
데이터베이스를 가장 쉽게 이해하는 방법은 서류 캐비닛을 떠올리는 것입니다.
서류 캐비닛의 각 서랍에는 종류별로 서류가 들어 있습니다. “고객 서류” 서랍, “주문 서류” 서랍, “가게 서류” 서랍. 각 서류는 정해진 양식에 따라 작성되어 있습니다. 데이터베이스에서 이 서랍을 테이블(Table) 이라고 합니다.
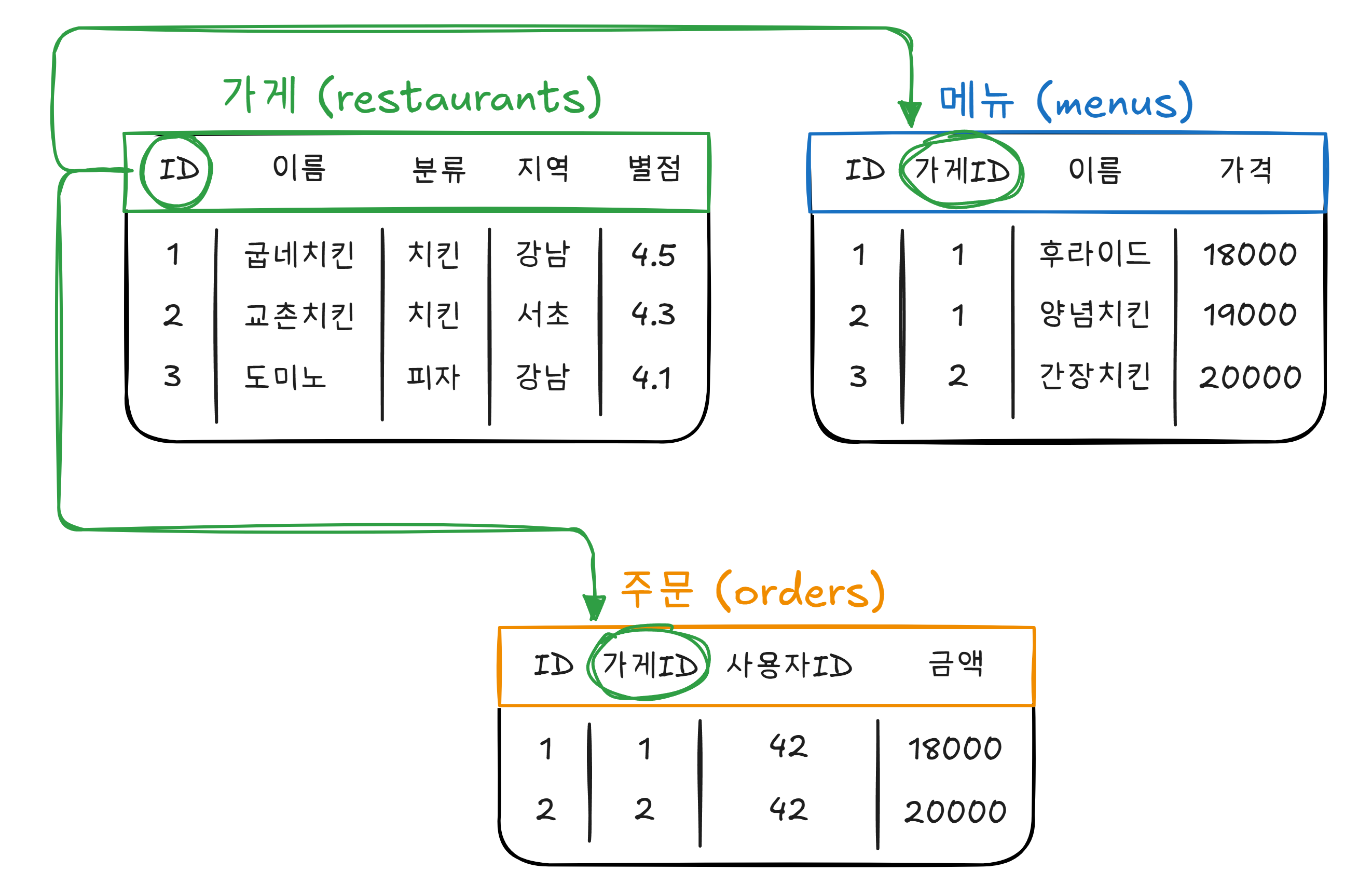
각 테이블은 행(Row) 과 열(Column) 로 구성됩니다. 행은 하나의 데이터(가게 1개, 메뉴 1개)이고, 열은 그 데이터의 속성(이름, 가격, 별점)입니다. 엑셀과 비슷해 보이지만, 데이터베이스는 수억 개의 행을 다루면서도 수천만 명이 동시에 접근할 수 있습니다.
테이블 사이에는 관계(Relation) 가 있습니다. 메뉴 테이블의 “가게ID“는 가게 테이블의 “ID“를 가리킵니다. 이렇게 테이블 간의 관계를 정의해서 데이터를 체계적으로 연결하는 데이터베이스를 관계형 데이터베이스(Relational Database) 라고 합니다. MySQL, PostgreSQL, Oracle이 대표적입니다.
SQL: 한 줄로 질문하기
데이터베이스에 질문하는 언어가 SQL(Structured Query Language)1 입니다. SQL은 프로그래밍 언어이지만, 영어 문장에 가까워서 읽기만 해도 대략 무슨 뜻인지 알 수 있습니다.
“강남에서 치킨집을 찾아줘“를 SQL로 쓰면 이렇습니다.
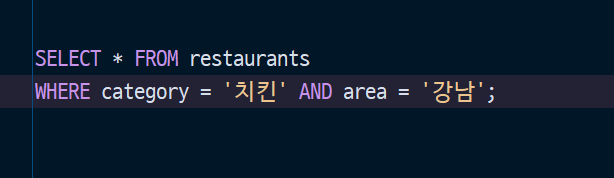
영어로 읽어 보겠습니다. “restaurants 테이블에서(FROM) 분류가 ’치킨’이고 지역이 ’강남’인 것을 전부(*) 가져와라(SELECT).” 거의 영어 문장입니다.
더 복잡한 질문도 가능합니다. “강남구에서 치킨을 3번 이상 시킨 사용자를 찾아줘.”
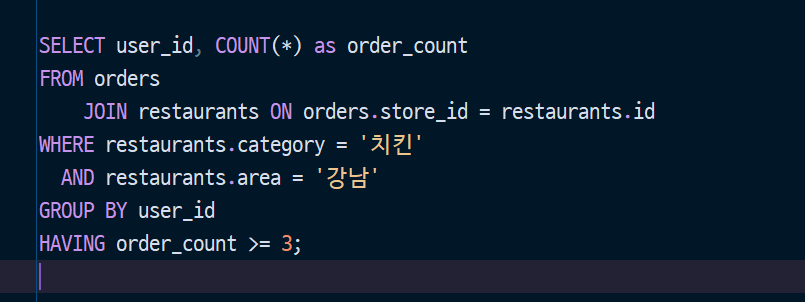
조금 복잡해 보이지만, 핵심은 같습니다. 어떤 테이블에서, 어떤 조건으로, 무엇을 가져올 것인가. 이 한 줄의 질문으로 수억 개의 데이터에서 원하는 답을 뽑아냅니다.
수억 행에서 이렇게 빠르게 찾을 수 있는 이유가 있습니다. 7장에서 역 인덱스를 설명했는데, 데이터베이스도 비슷한 원리를 사용합니다. 자주 검색하는 열(예: 지역, 분류)에 인덱스를 만들어 놓으면, 전체를 훑지 않고도 원하는 데이터를 빠르게 찾을 수 있습니다. 도서관의 “찾아보기“와 같은 원리입니다.
ACID: “반만 처리“는 안 된다
치킨을 골랐고, 결제 버튼을 눌렀습니다. 18,000원.
이때 데이터베이스에서는 두 가지 일이 일어납니다.

만약 1번이 실행된 직후 서버가 갑자기 꺼진다면? 내 돈은 빠졌는데 치킨집에는 돈이 안 들어갑니다. 18,000원이 공중에서 사라지는 겁니다.
이런 사태를 막는 것이 트랜잭션(Transaction) 입니다. 트랜잭션은 “여러 작업을 하나의 묶음으로 처리“하는 것입니다. 1번과 2번 모두 성공하거나, 모두 실패하거나. 중간 상태는 없습니다.
데이터베이스가 트랜잭션을 보장하기 위해 지키는 4가지 원칙이 있습니다. 앞글자를 따서 ACID라고 합니다.

원자성(Atomicity) 은 아까 이야기한 것입니다. 1번과 2번이 모두 성공하거나, 모두 취소되거나. 절반만 실행되는 일은 없습니다. 일관성(Consistency) 은 “계좌 잔액이 마이너스가 되면 안 된다” 같은 규칙이 트랜잭션 전후로 항상 유지된다는 뜻입니다. 격리성(Isolation) 은 내가 결제하는 동안 다른 사람의 결제가 내 결과를 바꾸지 않는다는 것이고, 지속성(Durability) 은 결제가 완료된 후 서버가 꺼져도 다시 켜면 결제 기록이 남아 있다는 뜻입니다.
ACID 덕분에 온라인 결제가 가능한 겁니다. 은행 송금, 주식 거래, 항공권 예매 — 돈이 오가는 모든 시스템은 ACID를 반드시 지킵니다.
NoSQL: 틀에 맞지 않는 데이터
관계형 데이터베이스는 강력하지만, 모든 데이터가 깔끔한 표에 맞지는 않습니다.
인스타그램 게시물을 떠올려 보겠습니다.

모든 게시물의 구조가 다릅니다. 이것을 정해진 열이 있는 테이블에 억지로 끼워 넣으면 빈 칸이 수두룩해지고, 새로운 기능(음악 태그, 스토리, 릴스)이 추가될 때마다 테이블 구조를 바꿔야 합니다.
이런 상황에서 사용하는 것이 NoSQL(Not Only SQL) 입니다. NoSQL은 정해진 표 형식 없이, 유연한 구조로 데이터를 저장합니다.
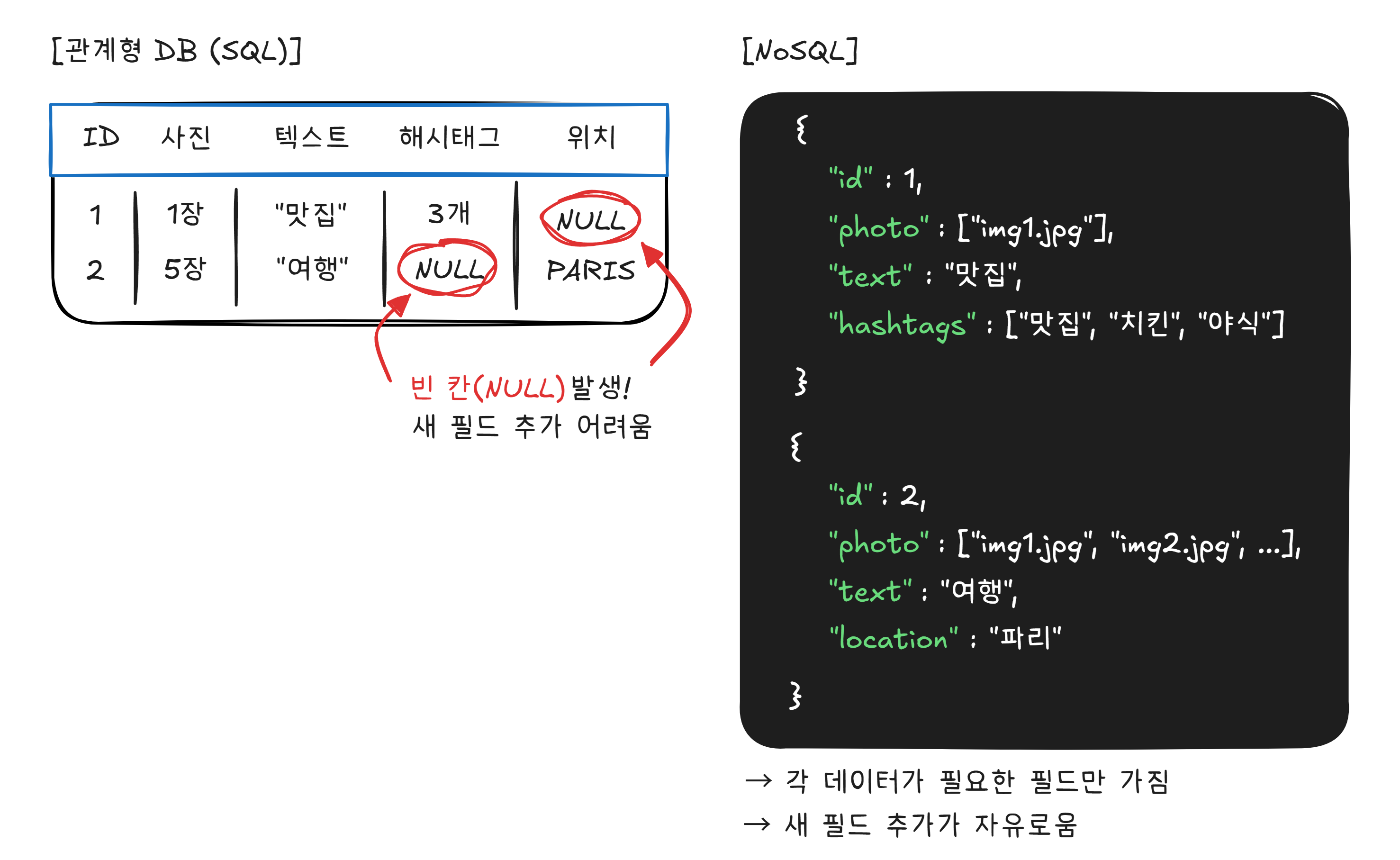
NoSQL의 대표 주자인 MongoDB는 이런 유연한 구조를 제공합니다. 데이터의 형태가 다양하고, 빠르게 변화하는 서비스(SNS, 실시간 채팅, IoT2)에 적합합니다.
그렇다고 NoSQL이 SQL을 대체하는 것은 아닙니다. 금융 거래처럼 ACID가 필수인 곳은 관계형 DB를, 소셜 미디어처럼 유연성이 필요한 곳은 NoSQL을 씁니다. 현실의 대부분의 서비스는 둘을 함께 사용합니다.
캐시: 냉장고 앞 메모
배달앱의 메인 화면을 열면 “인기 치킨집 TOP 10” 같은 목록이 뜹니다. 수천만 명이 앱을 열 때마다 데이터베이스에서 “인기순 정렬 → 상위 10개 추출“을 매번 실행하면 어떻게 될까요? 데이터베이스가 감당이 안 됩니다.
이 문제를 해결하는 것이 캐시(Cache)3 입니다.
냉장고 앞에 “우유 없음, 계란 3개 남음“이라고 메모를 붙여 놓았다고 해 보겠습니다. 우유가 있는지 확인하려고 매번 냉장고를 열 필요가 없습니다. 메모를 보면 됩니다. 냉장고를 여는 것(데이터베이스 조회)보다 메모를 보는 것(캐시 조회)이 훨씬 빠릅니다.
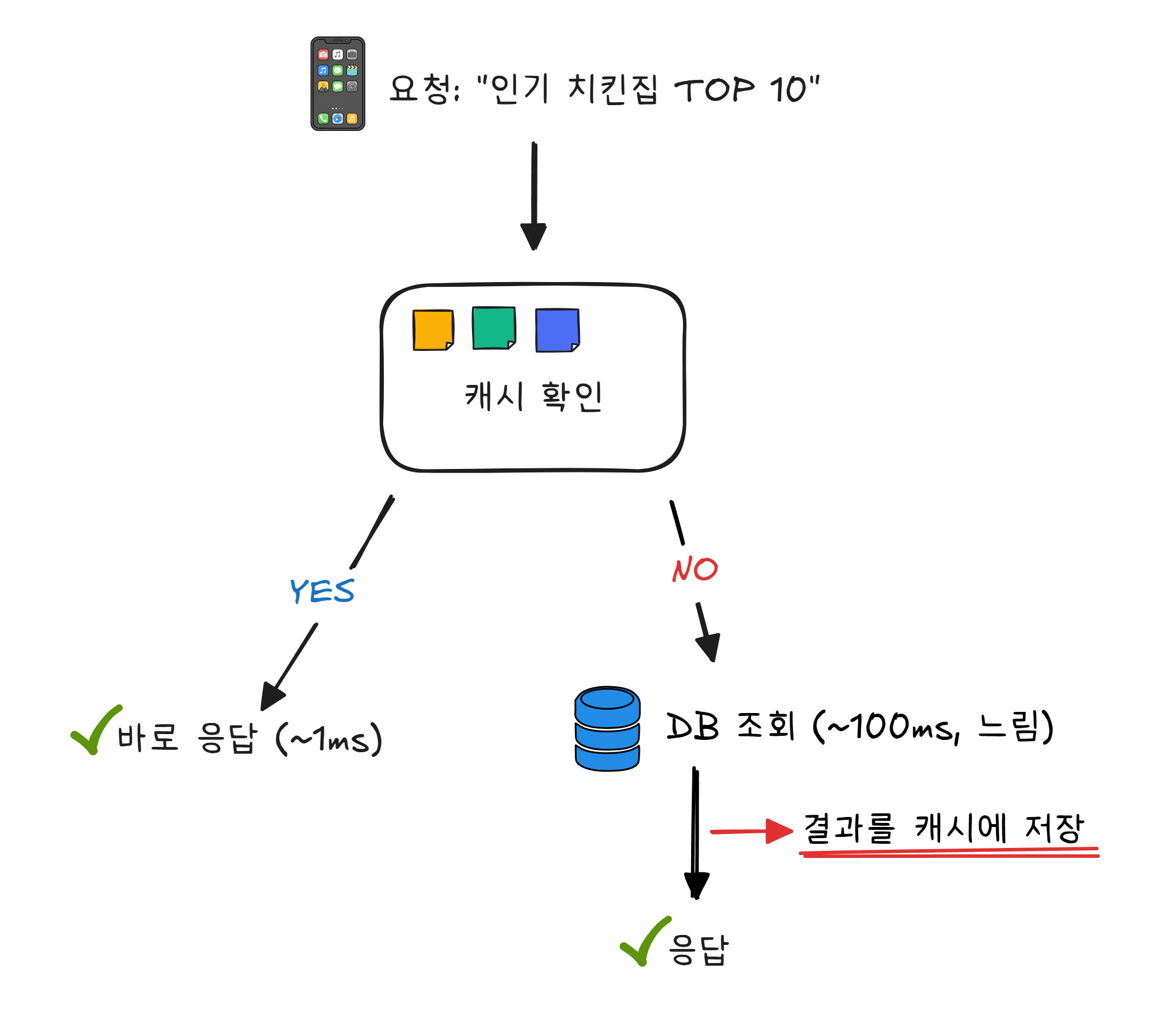
이런 캐시 용도로 널리 쓰이는 도구가 Redis입니다. Redis는 데이터를 디스크가 아니라 메모리(RAM)에 저장합니다. 디스크(하드디스크, SSD)에 저장하는 데이터베이스보다 수십~수백 배 빠릅니다. 2장에서 RAM이 책상이고 저장장치가 서랍장이라고 했던 것을 기억하시나요? 책상 위에 올려놓은 것은 바로 볼 수 있지만, 서랍에서 꺼내려면 시간이 걸립니다. 같은 원리입니다.
물론 캐시의 메모(데이터)는 영원하지 않습니다. 인기 치킨집 순위는 바뀔 수 있으니까요. 일정 시간이 지나면 캐시를 지우고, 다음 요청 때 DB에서 새로 조회합니다. 이 주기를 TTL(Time To Live) 이라고 합니다. 냉장고 앞 메모를 매일 아침 새로 쓰는 것과 같습니다.
사건: 2017 GitLab 데이터베이스 삭제 — 6시간이 사라진 밤
2017년 1월 31일, 개발자 협업 플랫폼 GitLab에서 대규모 장애가 발생합니다.4
원인은 황당할 정도로 단순했습니다. 야간 유지보수 중이던 엔지니어가, 프로덕션5 데이터베이스를 실수로 삭제한 것입니다.
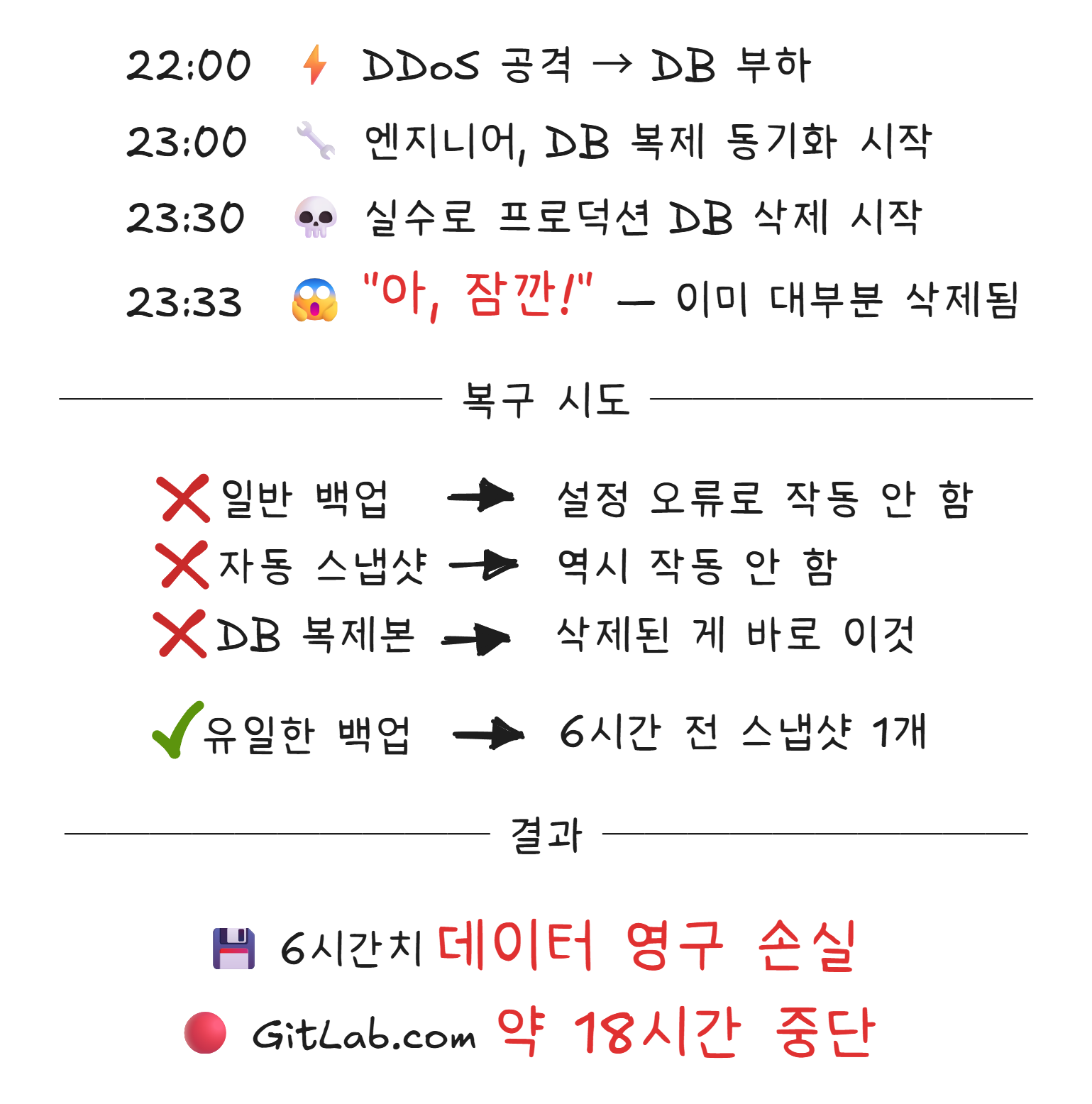
GitLab은 이 사건을 투명하게 공개했습니다. 실시간 복구 과정을 유튜브로 생중계하고, 사건 보고서를 전문 공개했습니다. 5개의 백업 방식이 모두 제대로 작동하지 않고 있었다는 충격적인 사실도 밝혔습니다.
이 사건의 교훈은 명확합니다. 백업은 “하고 있다“가 아니라 “복구할 수 있다“가 중요합니다. 백업 시스템이 돌아가고 있어도, 실제로 복구를 테스트해보지 않으면 그것이 진짜 작동하는지 알 수 없습니다.
알쓸신잡
-
SQL 읽어보기:
SELECT name, price FROM menus WHERE store_id = 1 ORDER BY price DESC;— “menus 테이블에서(FROM) 가게ID가 1인(WHERE) 메뉴의 이름과 가격을 가져와서(SELECT) 가격 내림차순으로 정렬해라(ORDER BY … DESC).” SQL이 영어 문장과 비슷하다는 것을 알 수 있습니다. 1970년대에 “비전문가도 데이터에 질문할 수 있어야 한다“는 철학으로 설계되었기 때문입니다. -
넷플릭스의 데이터: 넷플릭스의 영상 마스터 카탈로그만 약 3페타바이트(PB) 에 달하며, 사용자 데이터까지 합치면 수백 PB 규모입니다. 영상 콘텐츠뿐 아니라, 사용자가 어디서 일시정지했는지, 어느 장면에서 되감기했는지, 검색 기록, 시청 패턴까지 전부 저장합니다. 이 데이터가 12장에서 이야기할 추천 알고리즘의 연료가 됩니다.
-
DELETE와 DROP의 차이: 데이터베이스에서
DELETE는 테이블 안의 데이터(행)를 지우는 것이고,DROP은 테이블 자체를 없애는 것입니다. 서류 캐비닛에서 서류를 꺼내 버리는 것(DELETE)과, 서랍 자체를 뜯어내는 것(DROP)의 차이입니다. 신입 개발자가 프로덕션에서DROP TABLE을 실행하는 순간을 상상하면 — 이것이 GitLab 사건이 남의 일이 아닌 이유입니다.
치킨을 골랐습니다. 장바구니에 담았습니다. 이제 결제 버튼을 누릅니다. 카드 번호가 인터넷을 타고 전송됩니다. 그런데 잠깐 — 아까 6장에서 카페 WiFi가 위험하다고 했습니다. 내 카드 번호를 누군가 중간에서 엿보면 어떻게 하죠? 안전한 건가요?
-
SQL(Structured Query Language): 구조화 질의 언어. 데이터베이스에 질문(query)하거나 데이터를 추가/수정/삭제하는 데 쓰는 표준 언어. 1970년대 IBM에서 처음 개발되었다. ↩
-
IoT(Internet of Things): 사물 인터넷. 냉장고, 에어컨, 스피커 같은 일상 기기가 인터넷에 연결되어 데이터를 주고받는 것. ↩
-
캐시(Cache): 자주 사용하는 데이터를 임시로 저장해 두는 고속 저장소. 웹 브라우저의 캐시(방문한 페이지를 저장), CPU 캐시(자주 쓰는 데이터를 메모리보다 빠른 곳에 저장) 등 컴퓨터 곳곳에서 같은 원리가 사용된다. ↩
-
2017년 1월 31일. 약 18시간 중단, 6시간치 데이터 손실. — GitLab Postmortem ↩
-
프로덕션(Production): 실제 사용자가 이용하는 운영 환경. 개발자가 테스트하는 환경(개발/스테이징)과 구분된다. 프로덕션에서의 실수는 곧바로 실제 사용자에게 영향을 미친다. ↩
9장. 인터넷에서 돈을 보내는 법
“암호화, HTTPS, 인증서, 결제 시스템”
이번 장에서 알게 될 것
- 인터넷에서 카드 번호가 어떻게 안전하게 전송되는지
- 브라우저 주소창의 자물쇠 아이콘이 정확히 무엇을 의미하는지
- 결제 버튼을 누르고 2초 동안 벌어지는 일
- 전 세계 서버의 메모리를 들여다볼 수 있었던 치명적 버그
치킨 주문 여정: 결제 버튼을 누르다
치킨을 골랐습니다. 장바구니에 담았습니다. 결제 버튼을 누릅니다. 카드 번호 16자리가 인터넷을 타고 전송됩니다. 이 번호를 누군가 중간에서 훔쳐보면 어떻게 하죠?
엽서와 봉인된 편지
6장에서 카페 WiFi가 위험하다고 했습니다. 같은 네트워크에 있으면 오가는 데이터를 엿볼 수 있다고요. 그렇다면 카드 번호를 인터넷으로 보내는 것은 미친 짓일까요?
여기서 암호화(Encryption) 가 등장합니다.
암호화되지 않은 데이터를 보내는 것은 엽서를 보내는 것과 같습니다. 배달하는 사람 누구나 내용을 읽을 수 있습니다. 반면 암호화된 데이터를 보내는 것은 봉인된 편지를 보내는 것과 같습니다. 봉투를 뜯지 않는 한 내용을 알 수 없습니다.

브라우저 주소창에서 http://로 시작하면 엽서, https://로 시작하면 봉인된 편지입니다. ’s’는 Secure의 약자입니다.
대칭 암호: 같은 열쇠로 잠그고 열기
암호화의 가장 기본적인 방식은 대칭 암호(Symmetric Encryption) 입니다. 잠글 때와 열 때 같은 열쇠를 사용합니다.
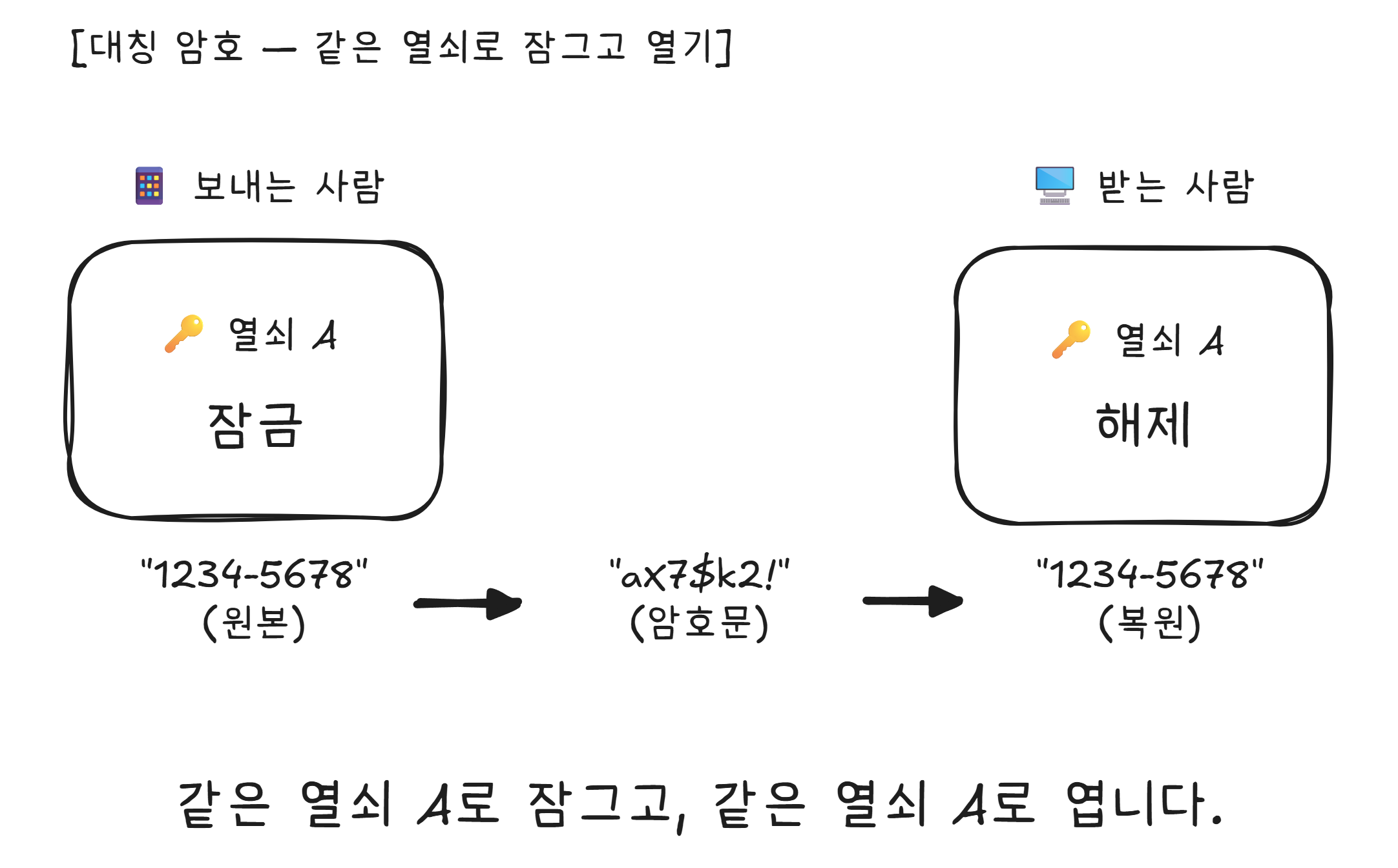
빠르고 효율적입니다. 하지만 치명적인 문제가 하나 있습니다.
열쇠를 어떻게 전달하지?
처음 만나는 사이인 내 폰과 배달의민족 서버가 같은 열쇠를 가져야 합니다. 그 열쇠를 인터넷으로 보내면? 열쇠 자체가 도청당합니다. 열쇠를 안전하게 보내려면 암호화가 필요한데, 암호화를 하려면 열쇠가 필요하고… 닭이 먼저냐 달걀이 먼저냐 같은 문제입니다.
비대칭 암호: 누구나 잠그지만, 열 수 있는 건 나뿐
이 문제를 해결하는 것이 비대칭 암호(Asymmetric Encryption) 입니다. 열쇠가 한 쌍으로 존재합니다. 공개 키(Public Key) 와 개인 키(Private Key).
아파트 무인택배함을 떠올려 보겠습니다.
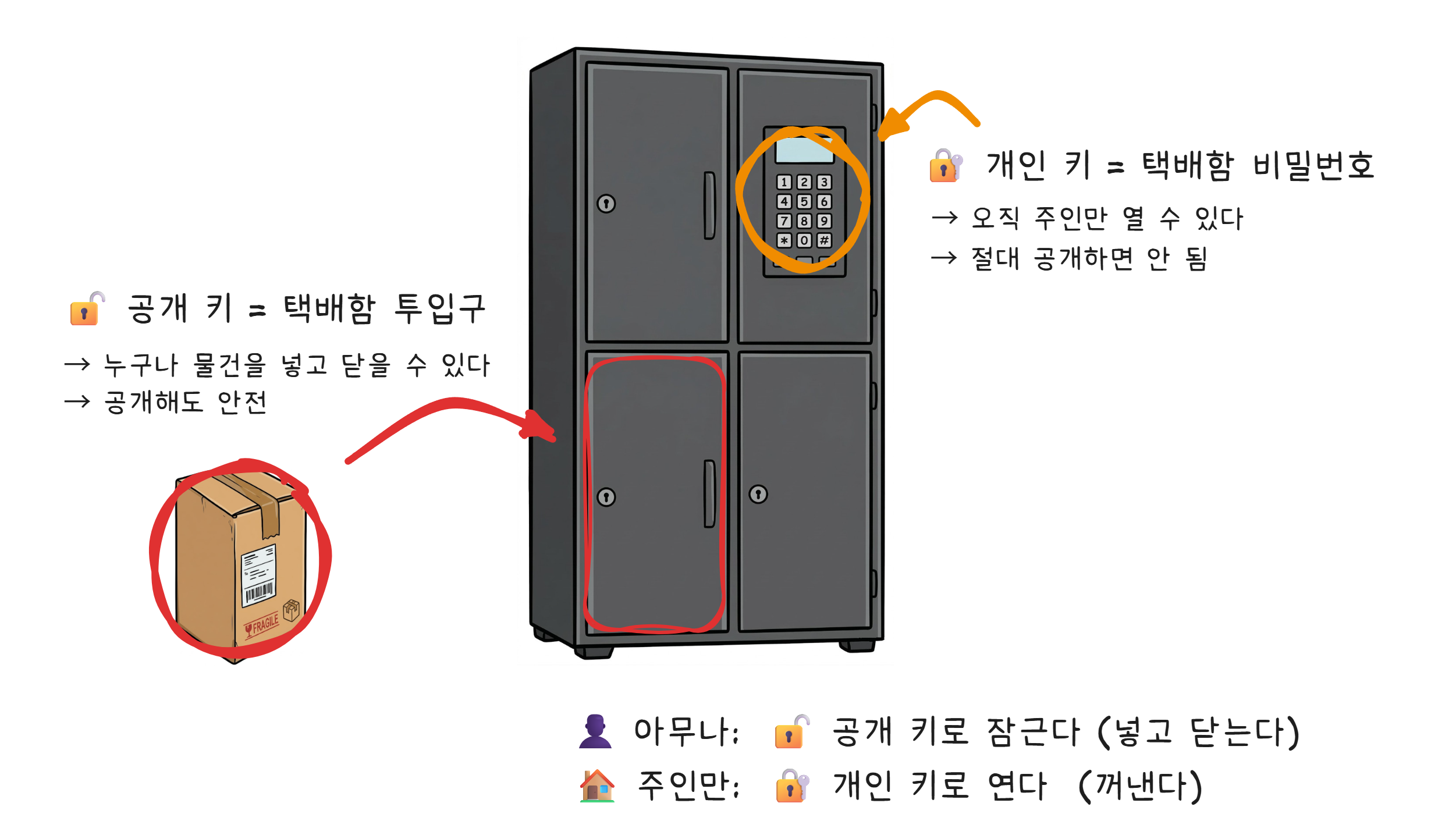
공개 키로 잠근 것은 개인 키로만 열 수 있고, 개인 키로 잠근 것은 공개 키로만 열 수 있습니다. 공개 키는 전 세계에 뿌려도 괜찮습니다. 어차피 열 수 있는 것은 개인 키를 가진 사람뿐이니까요.
이것으로 “열쇠를 어떻게 전달하지?” 문제가 해결됩니다.
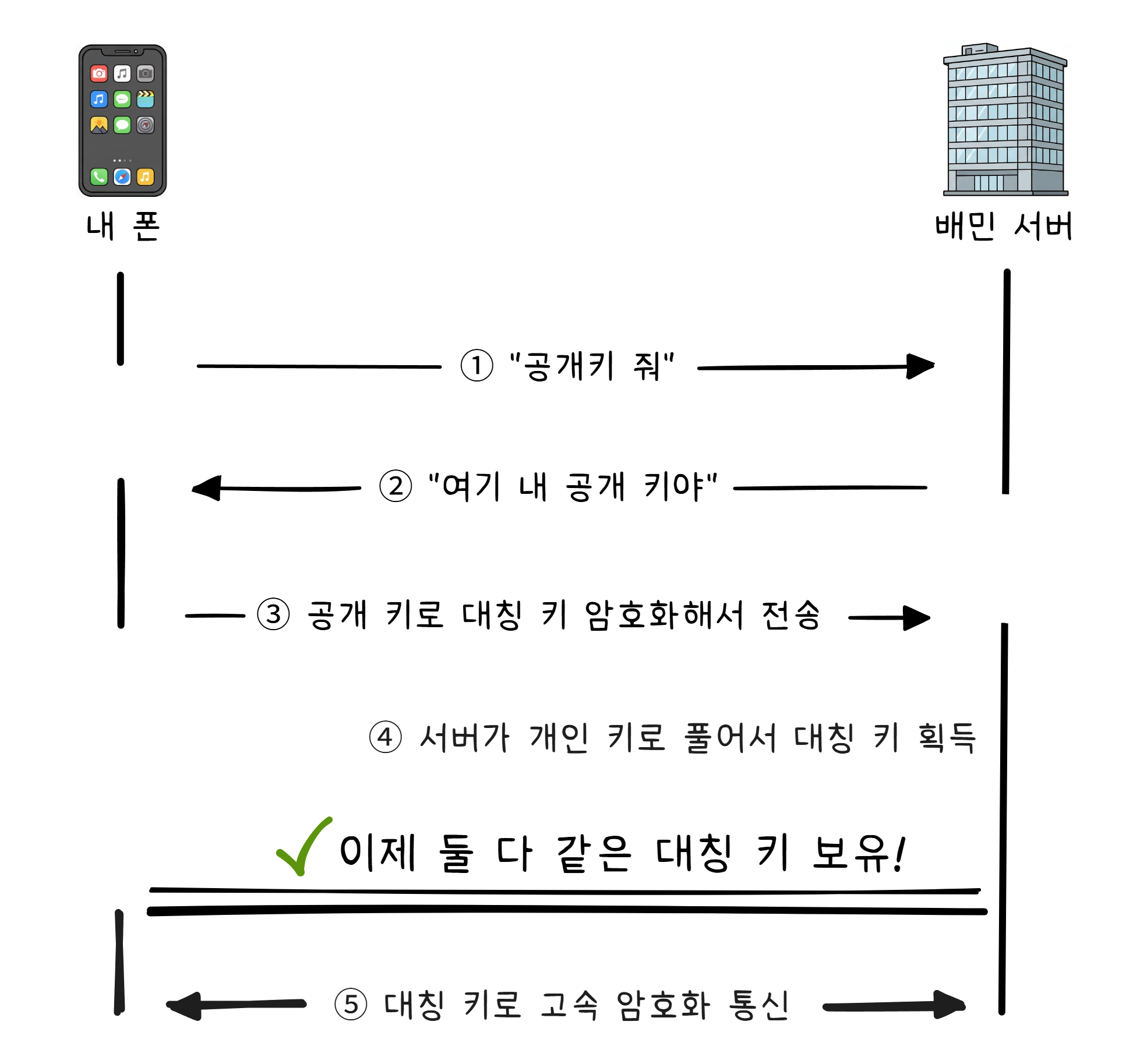
처음에 비대칭 암호로 대칭 키를 안전하게 교환하고, 이후 실제 데이터는 빠른 대칭 암호로 주고받습니다. 두 방식의 장점을 합친 것입니다. 이 과정을 TLS1 Handshake라고 합니다.
인증서: 이 서버가 진짜 배달의민족인지 확인하기
그런데 한 가지 문제가 더 있습니다. 내 폰이 통신하는 상대가 정말 배달의민족 서버인지 어떻게 알까요? 해커가 가짜 배달의민족 서버를 만들고, 자기 공개 키를 보내면? 나는 해커의 공개 키로 카드 번호를 암호화해서 보내게 됩니다. 해커는 자기 개인 키로 풀어서 카드 번호를 가져갑니다.
이 문제를 해결하는 것이 인증서(Certificate) 입니다.
인증서는 디지털 신분증입니다. “이 공개 키는 정말로 배달의민족의 것이 맞습니다“라고 인증 기관(CA)2 이 보증하는 것입니다.
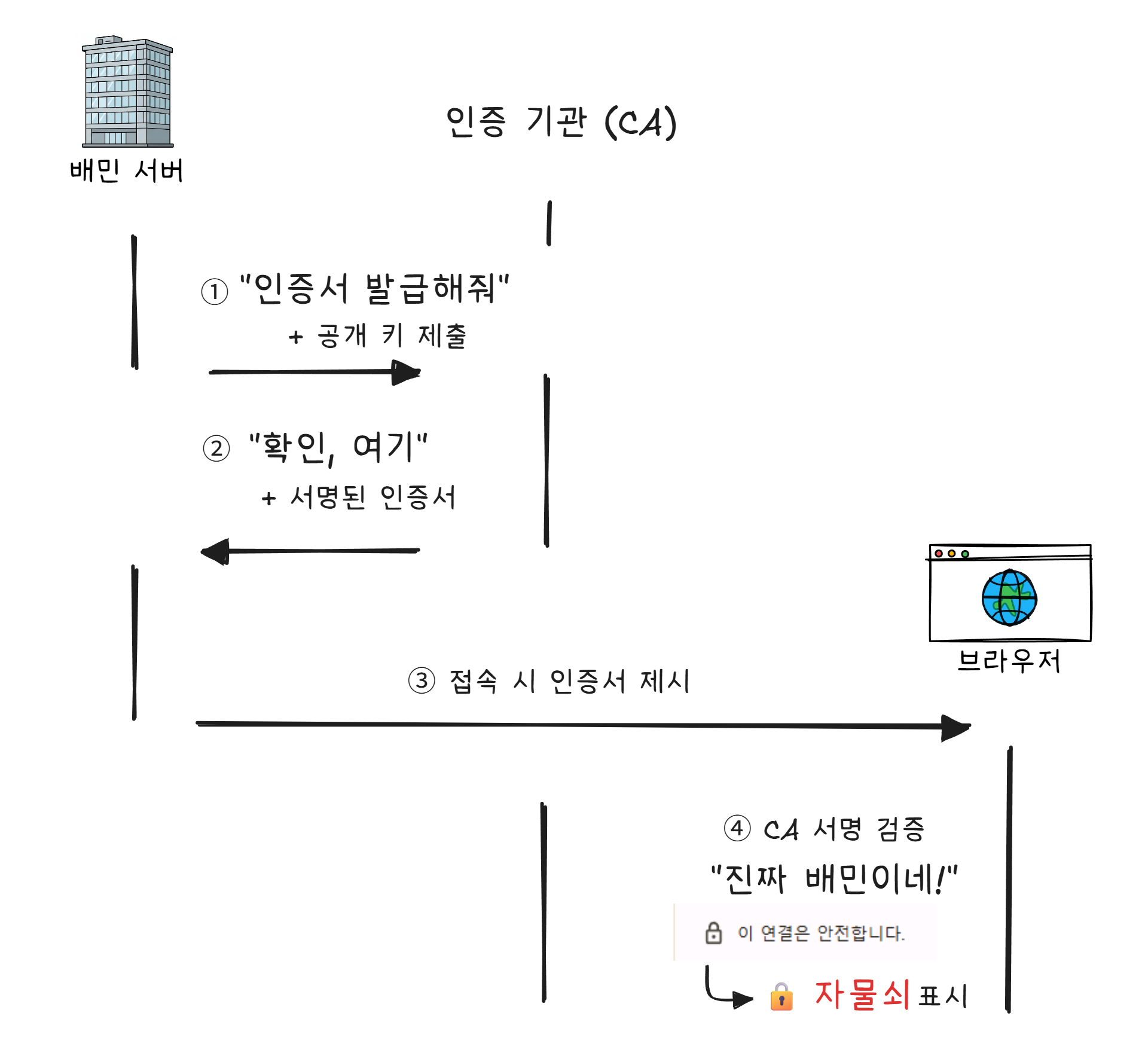
브라우저 주소창의 자물쇠 아이콘이 바로 이것입니다. “이 사이트의 인증서를 인증 기관이 보증했으며, 통신이 암호화되어 있다“는 뜻입니다.
인증서가 없거나 만료되면 브라우저가 “이 사이트는 안전하지 않습니다” 경고를 띄웁니다. 이 경고가 뜨는 사이트에 카드 번호를 입력하면 안 되는 이유입니다.
2015년에 출범한 Let’s Encrypt는 무료로 인증서를 발급해 줍니다. 이전에는 인증서 발급에 비용이 들었기 때문에 소규모 사이트는 HTTPS를 적용하지 못하는 경우가 많았습니다. Let’s Encrypt 덕분에 현재 웹 트래픽의 90% 이상이 HTTPS로 암호화되어 있습니다.
결제 버튼을 누르면 2초 동안 벌어지는 일
암호화가 보장된 상태에서, 결제 버튼을 누르면 실제로 무슨 일이 일어나는지 따라가 보겠습니다. 치킨 18,000원을 카드로 결제합니다.
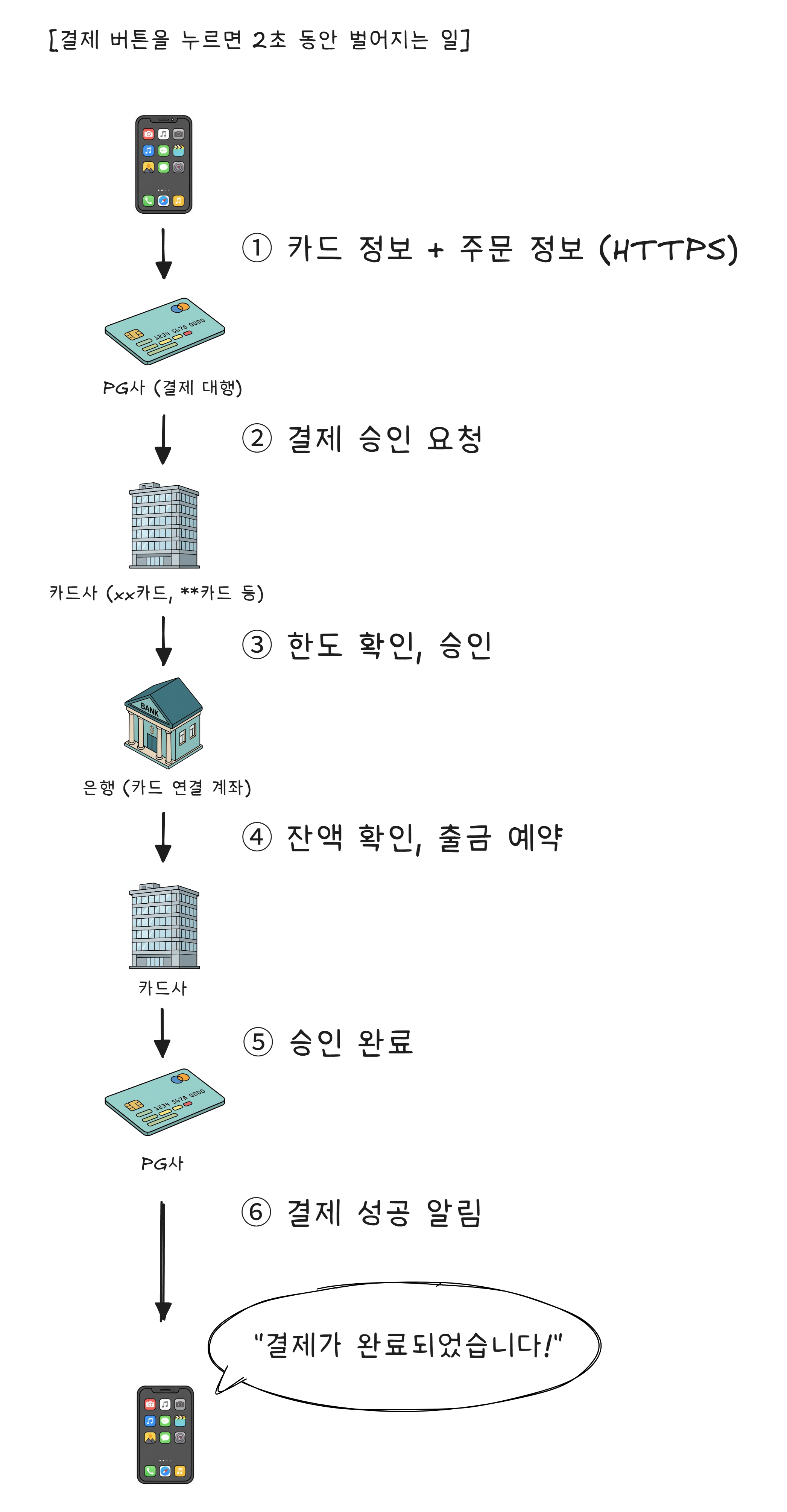
여기서 중요한 점은, 배달의민족 서버는 내 카드 번호를 저장하지 않습니다. 카드 정보는 PG사3가 처리하고, 배달앱은 “결제 성공/실패” 결과만 받습니다.
토큰화: 카드번호 대신 일회용 토큰
더 안전한 방법이 있습니다. 토큰화(Tokenization) 입니다.
카드번호 1234-5678-9012-3456 대신, 아무 의미 없는 일회용 번호 tk_8a7f2c...를 생성해서 전송합니다. 이 토큰은 한 번 사용하면 폐기됩니다. 해커가 토큰을 가로채도 재사용이 불가능합니다.
삼성페이, 애플페이 같은 간편결제가 이 방식을 사용합니다. 실제 카드번호는 기기의 보안 영역에만 저장되고, 결제할 때는 매번 새로운 토큰을 생성해서 보냅니다.
사건 1: 2013 Target 해킹 — 4천만 장의 카드가 유출되다
2013년 미국 대형 마트 Target에서 역대 최대 규모의 카드 정보 유출 사건이 발생합니다. 약 4천만 장의 신용카드/체크카드 정보가 도난당했습니다.4
해커들의 침입 경로는 의외였습니다. Target의 **냉난방 업체(HVAC)**를 먼저 해킹한 것입니다.
- 냉난방 업체 직원에게 피싱 이메일을 보내 시스템에 침입합니다.
- 이 업체는 Target 네트워크에 원격 접속 권한을 가지고 있었습니다. 냉난방 설비를 관리하기 위해서였습니다.
- 해커는 이 권한을 이용해 Target 내부 네트워크에 들어가, POS 단말기5에 악성코드를 설치합니다.
- 고객이 카드를 긁는 순간 정보가 수집되어 외부 서버로 빠져나갔습니다.
이 사건의 핵심 교훈은 공급망 공격(Supply Chain Attack) 입니다. 목표를 직접 공격하지 않고, 목표와 연결된 가장 약한 고리를 먼저 공격합니다. 냉난방 업체의 보안이 뚫리면서, 미국 최대 유통기업의 결제 시스템이 통째로 뚫렸습니다.
사건 2: Heartbleed — 인터넷의 심장에 구멍이 뚫리다
2014년 4월, Heartbleed라는 이름의 취약점이 공개됩니다.6
이 버그는 HTTPS 암호화를 담당하는 핵심 소프트웨어 OpenSSL7 에서 발견되었습니다. 전 세계 웹 서버의 약 3분의 2가 이 소프트웨어를 사용하고 있었습니다.
버그의 내용은 이렇습니다. TLS에는 연결이 살아있는지 확인하는 Heartbeat(심장 박동) 기능이 있습니다. “나 살아있어, 5글자 보낼게: HELLO“라고 보내면 서버가 “HELLO“를 그대로 되돌려 보냅니다. 그런데 악의적으로 “나 살아있어, 500글자 보낼게: HI“라고 보내면? 서버는 실제로 2글자만 받았는데도, 요청대로 500글자를 채우려고 메모리에서 나머지 498글자를 읽어서 보내버립니다. 서버 메모리에는 다른 사용자의 비밀번호, 암호화 키, 개인 정보가 들어 있습니다. 이것이 외부로 유출된 겁니다.
이 버그가 Heartbleed(심장 출혈)라는 이름을 얻은 이유입니다 — Heartbeat 기능에서 피가 새듯 정보가 새어나갔습니다.
가장 충격적인 것은 이 버그가 2년 넘게 발견되지 않았다는 사실입니다. 2011년 말에 코드에 들어간 버그가 2014년에야 발견되었습니다. 그 사이에 얼마나 많은 정보가 유출되었는지는 알 수 없습니다 — Heartbleed는 로그를 남기지 않기 때문입니다.
알쓸신잡
-
카드 뒷면 CVV의 역할: 카드 뒷면의 3자리 숫자를 CVV(Card Verification Value) 라고 합니다. 온라인 결제에서 “실물 카드를 가지고 있다“는 것을 증명하는 역할입니다. 카드 번호와 유효기간은 카드 앞면에 있어서 사진만 찍어도 유출되지만, CVV는 뒷면에 있어서 별도로 확인해야 합니다. 물론 완벽한 보안은 아니지만, 한 겹의 방어선을 더하는 것입니다.
-
비트코인과 블록체인: 기존 결제 시스템은 “은행“이라는 중앙 기관이 거래를 검증합니다. 비트코인은 은행 없이 거래를 검증하는 시스템입니다. 모든 거래 내역을 블록체인(Blockchain) 이라는 공개 장부에 기록하고, 네트워크 참여자 전원이 이를 검증합니다. 누군가 장부를 조작하려면 전체 네트워크의 과반수를 동시에 속여야 하므로 사실상 불가능합니다. 은행이 하던 “신뢰“의 역할을 수학과 네트워크로 대체한 것입니다.
-
“이 사이트는 안전하지 않습니다“의 진짜 의미: 이 경고는 “이 사이트가 해킹당했다“는 뜻이 아닙니다. “이 사이트가 HTTPS를 사용하지 않거나, 인증서에 문제가 있다“는 뜻입니다. 통신이 암호화되지 않을 수 있으므로 개인정보 입력을 주의하라는 것입니다. 단, 피싱 사이트가 유효한 인증서를 가지고 있는 경우도 있으므로, 자물쇠가 있다고 해서 100% 안전한 것은 아닙니다 — “통신은 안전하지만, 상대방이 사기꾼일 수 있다“는 뜻입니다.
결제가 완료되었습니다. 그런데 잠깐 — 이 결제를 하려면 먼저 배달앱에 로그인을 해야 했습니다. 비밀번호를 입력하고 로그인 버튼을 누르면, 그 비밀번호는 어디로 가는 걸까요? 서버에 저장되나요? 그렇다면 해킹당하면 내 비밀번호가 그대로 노출되는 건 아닐까요?
-
TLS(Transport Layer Security): 전송 계층 보안. HTTPS에서 실제 암호화를 담당하는 프로토콜. 과거에는 SSL(Secure Sockets Layer)이라 불렀으나, 현재는 TLS로 대체되었다. SSL이라는 이름이 더 익숙하지만, 실제로 사용되는 것은 TLS다. ↩
-
CA(Certificate Authority): 인증 기관. 디지털 인증서를 발급하고 검증하는 신뢰할 수 있는 제3자 기관. Let’s Encrypt, DigiCert, GlobalSign 등이 있다. ↩
-
PG사(Payment Gateway): 결제 대행사. 온라인 쇼핑몰이 직접 카드사와 계약하지 않아도 결제를 처리할 수 있도록 중간에서 대행하는 회사. 한국에서는 NHN KCP, 토스페이먼츠, 나이스페이 등이 대표적. ↩
-
카드 정보 4천만 건 + 개인정보 7천만 건, 총 1억 1천만 건 영향. — Krebs on Security ↩
-
POS 단말기(Point of Sale Terminal): 매장에서 카드를 긁거나 태그하는 결제 장치. ↩
-
CVE-2014-0160. 2011년 말 코드에 도입, 2014년 4월 7일 공개. — heartbleed.com ↩
-
OpenSSL: 암호화 통신을 구현하는 오픈소스 소프트웨어. 전 세계 웹 서버, 이메일 서버, VPN 등에 광범위하게 사용된다. ↩
10장. 비밀번호는 어디에 저장되나
“해싱, 솔팅, 인증, 2FA”
이번 장에서 알게 될 것
- “비밀번호 찾기“를 하면 왜 원래 비밀번호를 안 알려주는지
- 서비스가 비밀번호를 저장하지 않으면서도 로그인을 확인하는 원리
- “123456“이 세상에서 가장 위험한 비밀번호인 이유
- 비밀번호가 사라지는 시대가 오고 있다는 것
치킨 주문 여정: 잠깐, 로그인부터
결제가 완료되었습니다. 그런데 이 결제를 하려면 먼저 배달앱에 로그인을 해야 했습니다. 비밀번호를 입력하고 로그인 버튼을 누르면, 그 비밀번호는 어디에 저장되어 있을까요?
비밀번호 찾기의 비밀
누구나 한 번쯤 비밀번호를 잊어본 적이 있을 겁니다. “비밀번호 찾기“를 누르면 어떤 일이 일어나나요?
원래 비밀번호를 알려주는 게 아니라, “새 비밀번호를 설정하세요” 라고 합니다.
왜 원래 비밀번호를 안 알려줄까요? 의지가 없는 것이 아닙니다. 못 알려주는 겁니다. 서비스도 여러분의 비밀번호를 모르기 때문입니다.
“내 비밀번호를 모른다고? 그러면 로그인할 때 어떻게 확인하지?”
여기서 해싱(Hashing) 이 등장합니다.
해싱: 고기를 다지면 되돌릴 수 없다
해싱은 데이터를 일정한 길이의 무작위처럼 보이는 값으로 변환하는 것입니다. 이 변환은 일방향입니다 — 변환할 수는 있지만 원래 값을 복원할 수 없습니다.
고기를 다지는 것을 생각하면 됩니다. 소고기를 다지기로 갈면 다진 고기가 나옵니다. 하지만 다진 고기에서 원래 소고기 덩어리를 복원할 수는 없습니다. 해싱도 마찬가지입니다.
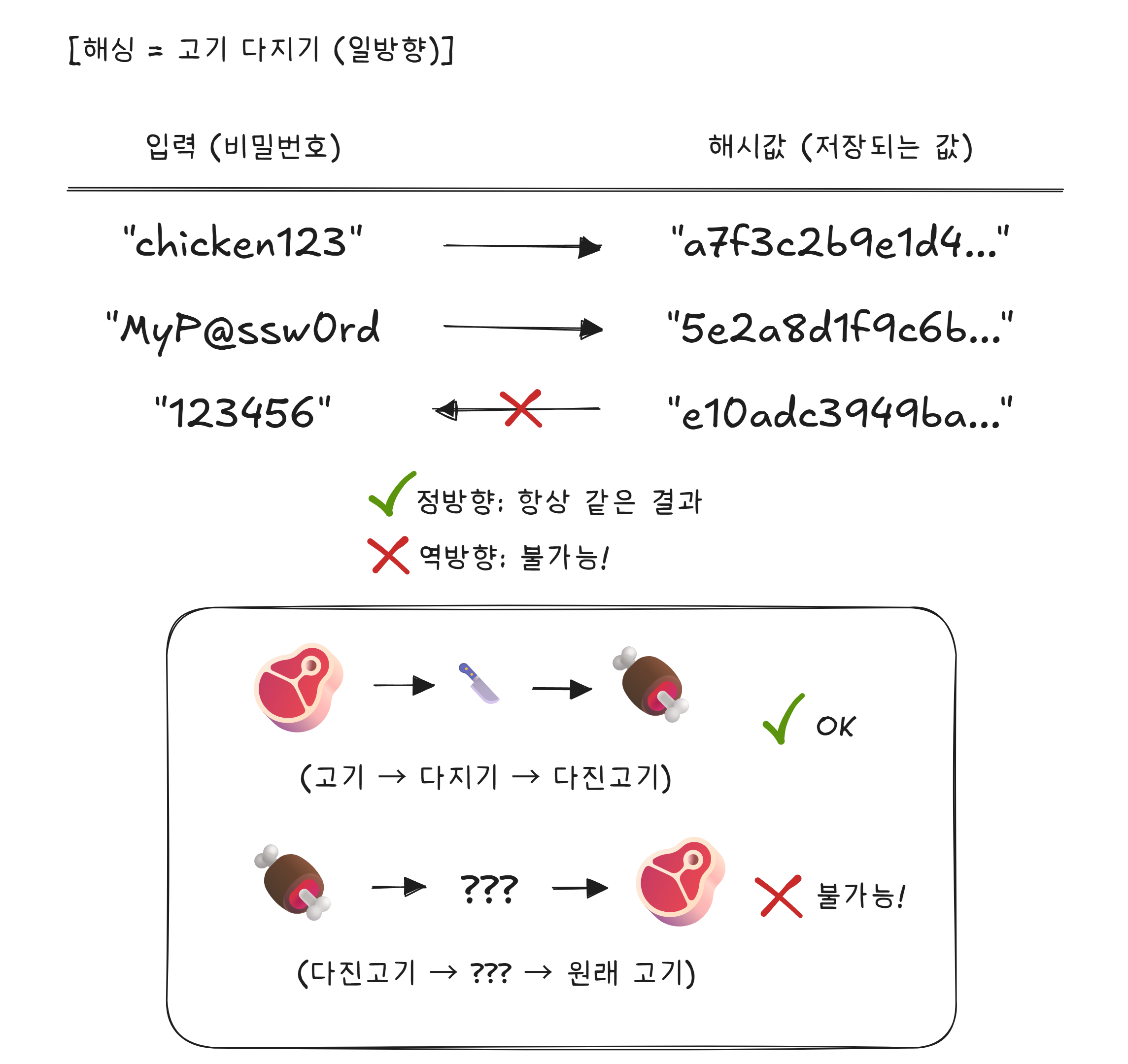
서비스는 회원가입 시 비밀번호를 해싱해서 저장합니다. 원본 비밀번호가 아니라 해시값만 저장하는 겁니다.
로그인할 때는 어떻게 할까요?
- 사용자가 비밀번호 입력: “chicken123”
- 서버가 입력값을 해싱: “chicken123” → “a7f3c2b9e1d4…”
- DB에 저장된 해시값과 비교
- 일치하면 로그인 성공
서버는 비밀번호 원본을 한 번도 보지 않았습니다. 해시값끼리 비교했을 뿐입니다.
그래서 “비밀번호 찾기“를 해도 원래 비밀번호를 알려줄 수 없는 겁니다. 서버에는 해시값만 있고, 해시값에서 원본을 복원하는 것은 불가능하니까요. 새 비밀번호를 설정하면 새 해시값을 저장하는 것이 전부입니다.
만약 어떤 서비스가 “비밀번호 찾기“를 했을 때 원래 비밀번호를 이메일로 보내준다면? 그 서비스는 비밀번호를 해싱하지 않고 원본 그대로 저장하고 있다는 뜻입니다. 매우 위험한 서비스입니다.
솔팅: 같은 재료에 소금을 다르게 넣기
해싱만으로 충분할까요? 문제가 있습니다.
같은 비밀번호는 항상 같은 해시값을 만듭니다. “123456“의 해시값은 언제나 “e10adc3949ba…“입니다. 해커가 미리 수백만 개의 비밀번호에 대한 해시값 표를 만들어 놓으면?
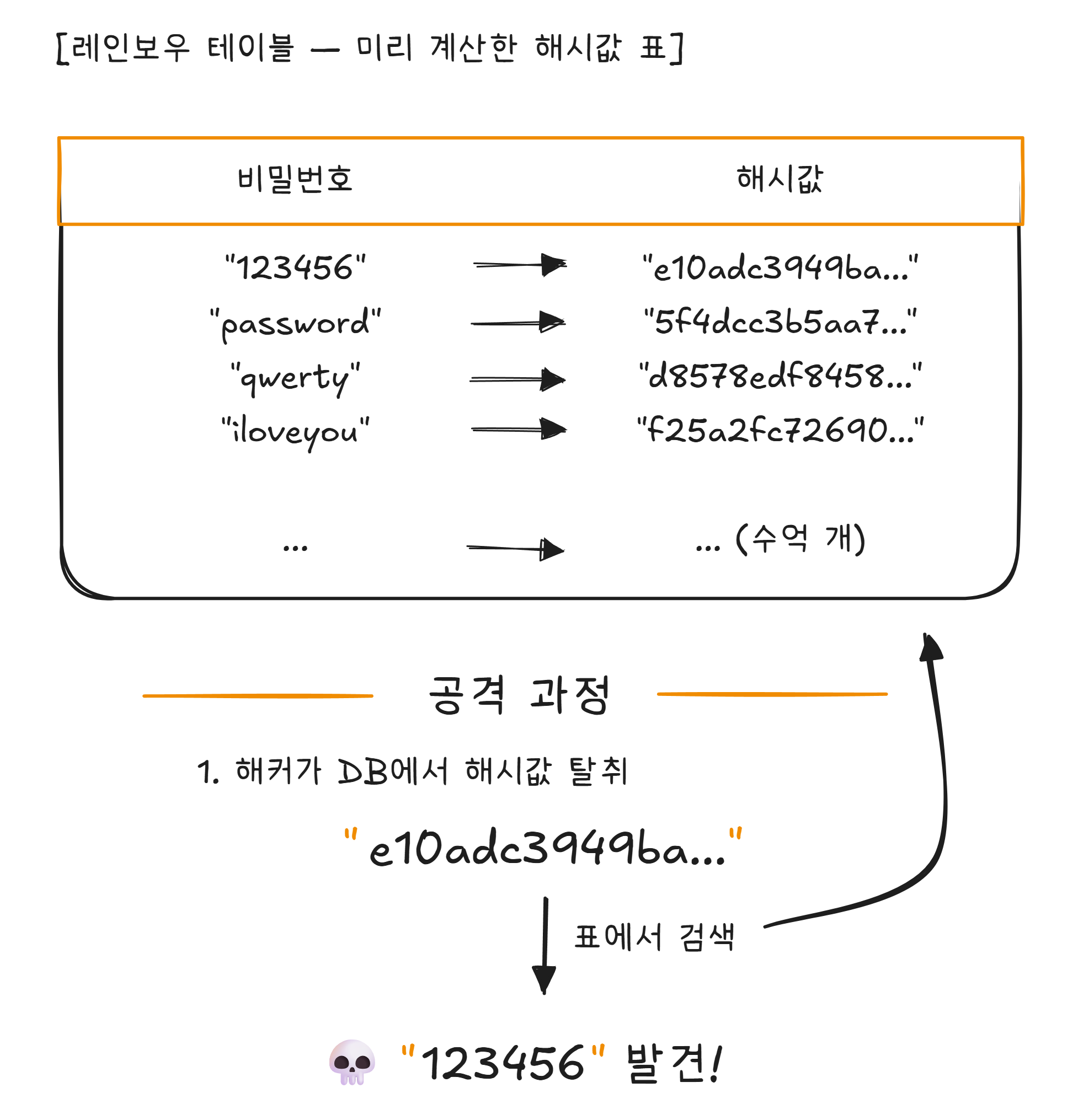
이 표를 **레인보우 테이블1**이라고 합니다. 자주 쓰이는 비밀번호의 해시값을 미리 계산해 놓은 것입니다. 해커가 해시값을 탈취하면, 이 표에서 역으로 비밀번호를 찾을 수 있습니다.
이 문제를 해결하는 것이 솔팅(Salting) 입니다. 해싱하기 전에 소금(Salt) — 무작위 문자열 — 을 비밀번호에 붙이는 것입니다.

사용자마다 다른 소금을 사용하기 때문에, 같은 비밀번호라도 해시값이 전부 다릅니다. 레인보우 테이블은 소금이 없는 경우에만 작동하므로, 솔팅을 적용하면 무용지물이 됩니다.
소금은 비밀이 아닙니다. 해시값과 함께 DB에 저장됩니다. 소금의 목적은 비밀을 유지하는 것이 아니라, 같은 비밀번호가 같은 해시값을 만들지 못하게 하는 것입니다.
“123456“이 위험한 진짜 이유
매년 공개되는 “가장 많이 사용되는 비밀번호” 목록에서 “123456“은 수 년째 1위를 차지하고 있습니다.
세계에서 가장 많이 쓰이는 비밀번호(2024년 기준)를 보면 그 심각성을 알 수 있습니다.
- 123456
- 123456789
- password
- 12345678
- qwerty
- 1234567890
- 111111
- 1234567
- abc123
- password1
이 비밀번호들이 위험한 이유는 간단합니다. 해커가 로그인을 시도할 때, 이 목록의 비밀번호부터 넣어봅니다. 이것을 사전 공격(Dictionary Attack) 이라고 합니다. “123456“은 사전의 첫 페이지인 셈입니다.
솔팅과 해싱이 아무리 강력해도, 비밀번호 자체가 “123456“이면 해커가 “123456“을 직접 넣어보면 그만입니다. 자물쇠가 아무리 튼튼해도 열쇠가 “1111“이면 의미가 없는 것과 같습니다.
비밀번호의 길이와 복잡도에 따라 크래킹에 걸리는 시간은 극적으로 달라집니다.
비밀번호 크래킹 예상 시간 (최신 GPU 기준):
| 길이 | 숫자만 | 소문자 | 소문자+숫자+특수문자 |
|---|---|---|---|
| 6자리 | 즉시 | 즉시 | 5초 |
| 8자리 | 즉시 | 수 분 | 8시간 |
| 10자리 | 즉시 | 수 시간 | 5년 |
| 12자리 | 25초 | 수 주 | 3만 년 |
| 16자리 | 수 시간 | 수백만 년 | 수조 년 |
길이가 핵심입니다. 같은 소문자라도 6자리와 16자리는 하늘과 땅 차이입니다. 특수문자를 넣는 것보다 길이를 늘리는 것이 훨씬 효과적입니다.
2FA: 자물쇠를 두 개 달기
비밀번호만으로는 부족합니다. 비밀번호가 유출되면 끝이니까요. 그래서 등장한 것이 2FA(2-Factor Authentication)2 입니다.
2FA는 로그인할 때 두 가지 다른 종류의 인증을 요구합니다.
인증에는 3가지 요소가 있습니다.
- 내가 아는 것 — 비밀번호, PIN 번호
- 내가 가진 것 — 휴대폰(OTP3 수신), 보안 키
- 나 자신 — 지문, 얼굴, 홍채
2FA는 이 중 서로 다른 2가지를 조합합니다.
예를 들어 1단계에서 비밀번호를 입력하고(“내가 아는 것”), 2단계에서 휴대폰으로 전송된 6자리 인증 코드를 입력합니다(“내가 가진 것”). 비밀번호를 훔쳐도, 내 폰까지 훔치지 않으면 로그인할 수 없습니다.
은행 앱에서 비밀번호를 입력한 뒤 OTP 번호를 추가로 입력하는 것이 2FA입니다. 구글, 네이버 같은 서비스에서 로그인할 때 “새 기기에서 로그인을 시도합니다. 본인이 맞습니까?“라는 알림이 오는 것도 2FA의 일종입니다.
비밀번호는 유출될 수 있습니다. 하지만 비밀번호와 내 폰이 동시에 해커 손에 넘어갈 확률은 매우 낮습니다. 이것이 2FA의 핵심입니다.
패스키: 비밀번호의 종말?
비밀번호의 근본적인 문제는, 사람이 기억해야 한다는 것입니다. 기억하기 쉬운 비밀번호는 해킹도 쉽고, 어려운 비밀번호는 사람이 기억을 못 합니다. 서비스마다 다른 비밀번호를 쓰라고 하지만 현실적으로 지키기 어렵습니다.
그래서 등장한 것이 패스키(Passkey) 입니다.
패스키는 비밀번호를 아예 없애는 기술입니다. 대신 기기 자체가 인증합니다.
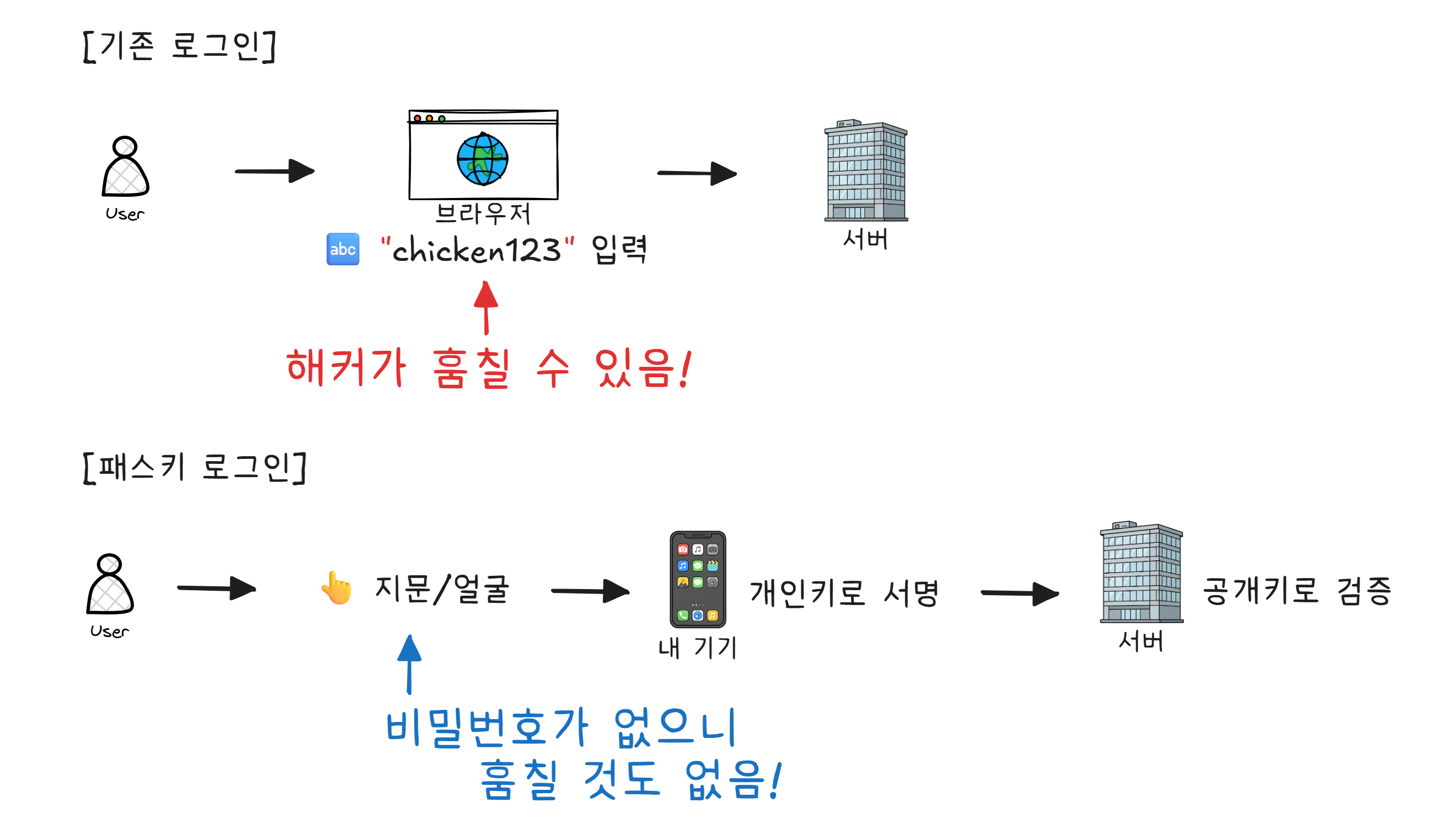
9장에서 설명한 비대칭 암호가 여기서도 쓰입니다. 개인 키는 기기 밖으로 나가지 않고, 서버에는 공개 키만 있으므로 서버가 해킹당해도 인증 정보가 유출되지 않습니다.
애플, 구글, 마이크로소프트가 이미 패스키를 지원하고 있습니다. “비밀번호 없는 미래“가 멀지 않았습니다.
사건: 2012 LinkedIn 해킹 — 1억 개의 비밀번호가 유출되다
2012년, 비즈니스 전문 SNS LinkedIn에서 약 1억 1,700만 개의 사용자 비밀번호가 유출됩니다.4
문제는 LinkedIn이 비밀번호를 저장한 방식이었습니다.
- 이미 취약하다고 알려진 SHA-1 알고리즘으로 해싱했습니다.
- 솔팅을 하지 않았습니다. 같은 비밀번호는 같은 해시값을 가졌습니다.
- 해커가 레인보우 테이블로 대부분의 해시값을 역추적했습니다.
- 수천만 개의 비밀번호 원문이 복원되었습니다.
솔팅을 하지 않았기 때문에, “123456“을 쓴 모든 사용자의 해시값이 동일했습니다. 하나만 풀면 같은 비밀번호를 쓴 수십만 명의 계정이 동시에 뚫리는 겁니다.
더 심각한 문제는 비밀번호 재사용입니다. LinkedIn에서 유출된 비밀번호로 같은 사용자의 Gmail, 페이스북, 은행 계정에 로그인을 시도하는 것입니다. 이것을 크리덴셜 스터핑(Credential Stuffing)5 이라고 합니다. 서비스마다 다른 비밀번호를 사용해야 하는 이유가 바로 이것입니다.
이 사건 이후 업계 전체가 bcrypt, scrypt 같은 더 강력한 해싱 알고리즘과 솔팅을 표준으로 도입합니다.
알쓸신잡
-
비밀번호에 특수문자를 강제하는 게 정말 안전한가?: 2003년, 미국 국립표준기술연구소(NIST)의 빌 버는 “비밀번호에 대문자, 숫자, 특수문자를 포함하라“는 가이드라인을 발표합니다. 14년 후인 2017년, 그는 이 가이드라인을 후회한다고 밝힙니다. “P@ssw0rd!“처럼 예측 가능한 치환을 하게 만들 뿐이라는 겁니다. 현재 NIST는 “길고 외우기 쉬운 문장형 비밀번호” 를 권장합니다. “correcthorsebatterystaple“이 “P@55w0rD!“보다 더 안전합니다.
-
“나는 로봇이 아닙니다” CAPTCHA의 이중 목적: 웹사이트에서 “나는 로봇이 아닙니다“를 클릭하거나 “신호등이 있는 사진을 모두 고르세요” 같은 테스트를 요구합니다. 이것을 CAPTCHA6 라고 합니다. 봇(자동화 프로그램)의 접근을 차단하는 것이 주 목적이지만, 동시에 여러분의 응답이 AI 학습 데이터로 사용됩니다. 구글의 reCAPTCHA에서 왜곡된 글자를 읽거나 사진을 분류할 때, 여러분은 무료로 구글의 AI 학습에 기여하고 있는 겁니다.
-
세션 하이재킹에서 JWT까지: 6장에서 세션 토큰을 이야기했습니다. 초기 웹에서는 서버가 “이 사용자가 로그인했다“는 정보를 서버 메모리에 저장했습니다. 하지만 사용자가 수천만 명이 되면 서버의 부담이 커집니다. 그래서 현재는 JWT(JSON Web Token)7 라는 방식을 많이 사용합니다. 로그인 정보를 서버가 아닌 토큰 자체에 담아서 사용자에게 주는 것입니다. 서버는 토큰의 서명만 확인하면 되므로, 메모리에 세션을 저장할 필요가 없어집니다.
결제가 완료되었습니다. “주문이 접수되었습니다. 배달 예상 시간: 35분.” 화면에 배달원의 위치가 실시간으로 표시됩니다. 배달원이 우리 집을 향해 이동하는 파란 점. 이 점은 어떻게 내 폰에 실시간으로 표시되는 걸까요? 배달원의 위치는 어떻게 아는 걸까요?
-
레인보우 테이블(Rainbow Table): 해시값과 원본 비밀번호의 대응표. 미리 수억 개의 해시값을 계산해 놓고, 탈취한 해시값에서 원본을 역으로 찾는 데 사용하는 공격 도구. ↩
-
2FA(2-Factor Authentication): 이중 인증. 로그인 시 서로 다른 두 가지 인증 수단을 요구하는 보안 방식. MFA(Multi-Factor Authentication, 다중 인증)로 확장되기도 한다. ↩
-
OTP(One-Time Password): 일회용 비밀번호. 보통 30초마다 새로운 6자리 숫자가 생성되며, 한 번 사용하면 폐기된다. ↩
-
2012년 6월 유출, 2016년 전체 규모(1억 1,700만 건) 확인. — Krebs on Security ↩
-
크리덴셜 스터핑(Credential Stuffing): 한 서비스에서 유출된 아이디/비밀번호 조합을 다른 서비스에 자동으로 대입해보는 공격. 비밀번호를 재사용하는 사용자를 노린다. ↩
-
CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart): 컴퓨터와 사람을 구별하기 위한 자동화된 공개 튜링 테스트. ↩
-
JWT(JSON Web Token): 사용자 인증 정보를 JSON 형식으로 인코딩한 토큰. 서버가 세션을 저장하지 않아도 되는 무상태(stateless) 인증 방식. ↩
11장. 지도 앱은 어떻게 길을 찾는가
“GPS, 지도, 경로 탐색 알고리즘”
이번 장에서 알게 될 것
- 스마트폰이 내 위치를 수 미터 오차로 아는 원리
- 아인슈타인의 상대성이론이 GPS에 적용되고 있다는 사실
- 지도 앱이 가장 빠른 길을 찾는 알고리즘
- 배달 예상 시간 “35분“이 어떻게 계산되는지
치킨 주문 여정: 치킨이 출발했다
“주문이 접수되었습니다.” “배달원이 가게에서 출발했습니다.” 화면에 지도가 뜨고, 배달원의 위치가 실시간으로 움직입니다. 배달원의 위치를 어떻게 아는 걸까요?
하늘 위 20,200km에서 쏘는 시간 신호
배달원의 위치를 아는 것, 즉 GPS(Global Positioning System) 의 원리부터 알아보겠습니다.
지구 궤도 약 20,200km 높이에는 31개의 GPS 위성이 돌고 있습니다. 이 위성들은 끊임없이 하나의 메시지를 보냅니다 — “나는 지금 여기에 있고, 지금 시각은 이것이다.”
스마트폰은 이 신호를 받아서 자신의 위치를 계산합니다. 원리는 이렇습니다. 각 위성이 “내 위치는 여기, 시각은 12시 정각“이라고 보냈는데 스마트폰에 0.067초 뒤에 도착했다면, 전파 속도(빛의 속도)에 시간을 곱해 그 위성으로부터의 거리를 알 수 있습니다.
위성 하나로는 “위성에서 20,100km 떨어진 구(球) 위의 어딘가“까지만 알 수 있습니다. 위성 두 개면 두 구의 교차선, 세 개면 두 점, 네 개면 정확한 한 점이 됩니다. 이것을 삼변측량1 이라고 합니다.
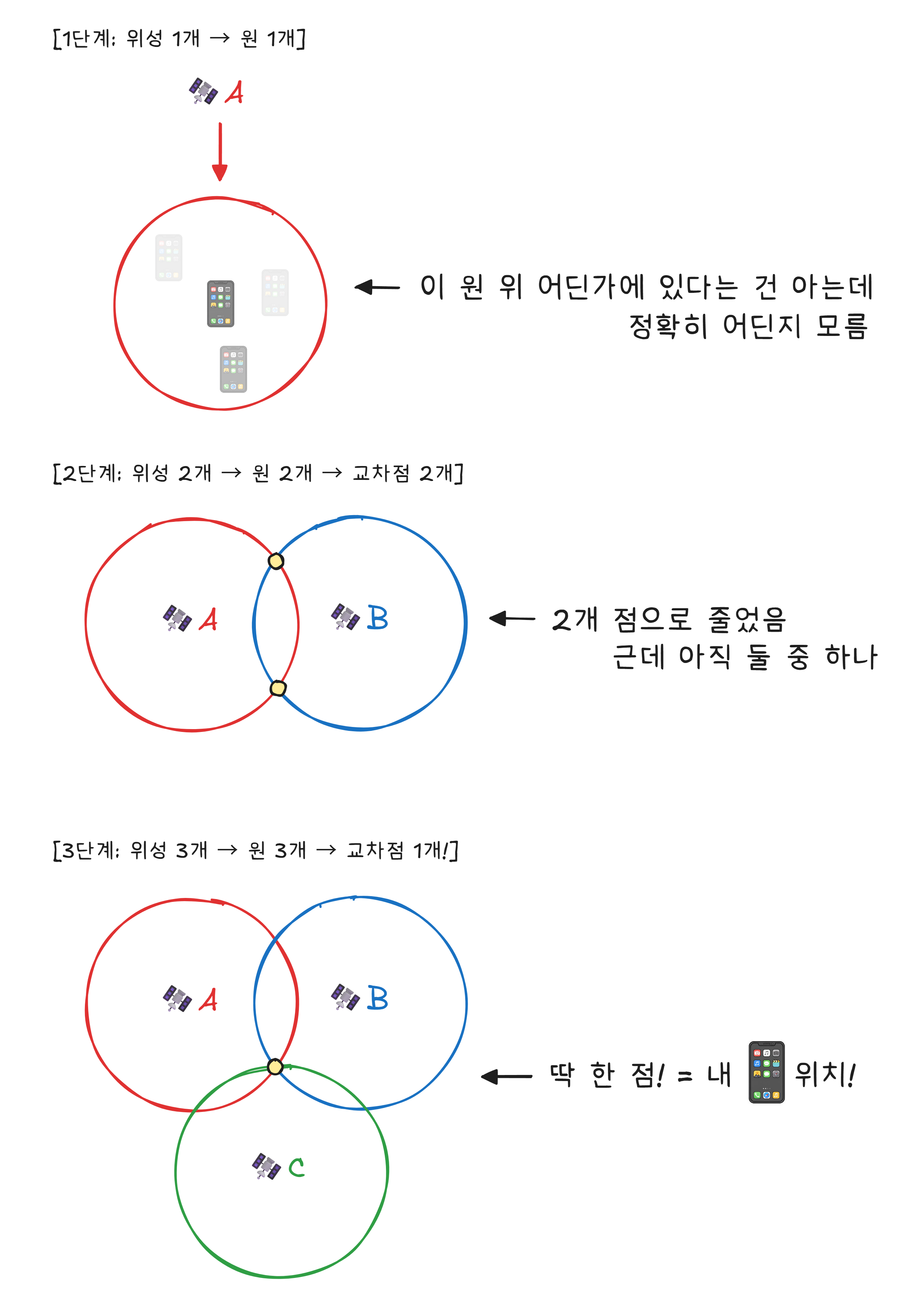
실제로는 위성 최소 4개가 필요합니다. 3개로 위치를 정하고, 4번째로 시간 오차를 보정합니다.
1나노초 = 30cm 오차
GPS에서 시간은 생명입니다. 전파는 빛의 속도(초속 약 30만 km)로 이동합니다. 1초에 30만 km를 가니까, 10억분의 1초(1나노초) 의 시간 오차는 약 30cm의 거리 오차가 됩니다.
이 정밀한 시간을 측정하기 위해 GPS 위성에는 원자시계가 탑재되어 있습니다. 원자시계는 10만 년에 1초 정도의 오차만 발생하는, 인류가 만든 가장 정확한 시계입니다.
아인슈타인이 GPS를 가능하게 했다
GPS 위성은 초속 약 3.9km로 움직이고, 지상 20,200km 높이에 있습니다. 여기서 아인슈타인의 상대성이론이 등장합니다.
| 효과 | 방향 | 크기 |
|---|---|---|
| 특수 상대성이론 | 느려짐 | -7μs/일 |
| 일반 상대성이론 | 빨라짐 | +45μs/일 |
합산 = +38μs/일 (하루에 38마이크로초 빨라짐)
위성의 시계가 하루에 38마이크로초씩 빨라지는 것을 보정하지 않으면, GPS 위치가 하루에 약 11km씩 틀어집니다. 내비게이션이 한강을 가리키고 있을 수 있다는 뜻입니다. 100년 전 이론물리학자가 쓴 공식이 오늘날 배달 추적에 사용되고 있는 셈입니다.
최단 경로: 네비게이션은 어떻게 길을 찾는가
배달원의 위치를 알았으니, 이제 가게에서 우리 집까지의 최적 경로를 찾아야 합니다.
지도를 컴퓨터가 이해할 수 있는 형태로 바꾸면, 교차로는 점(노드), 도로는 선(간선), 도로의 거리나 시간은 가중치가 됩니다.
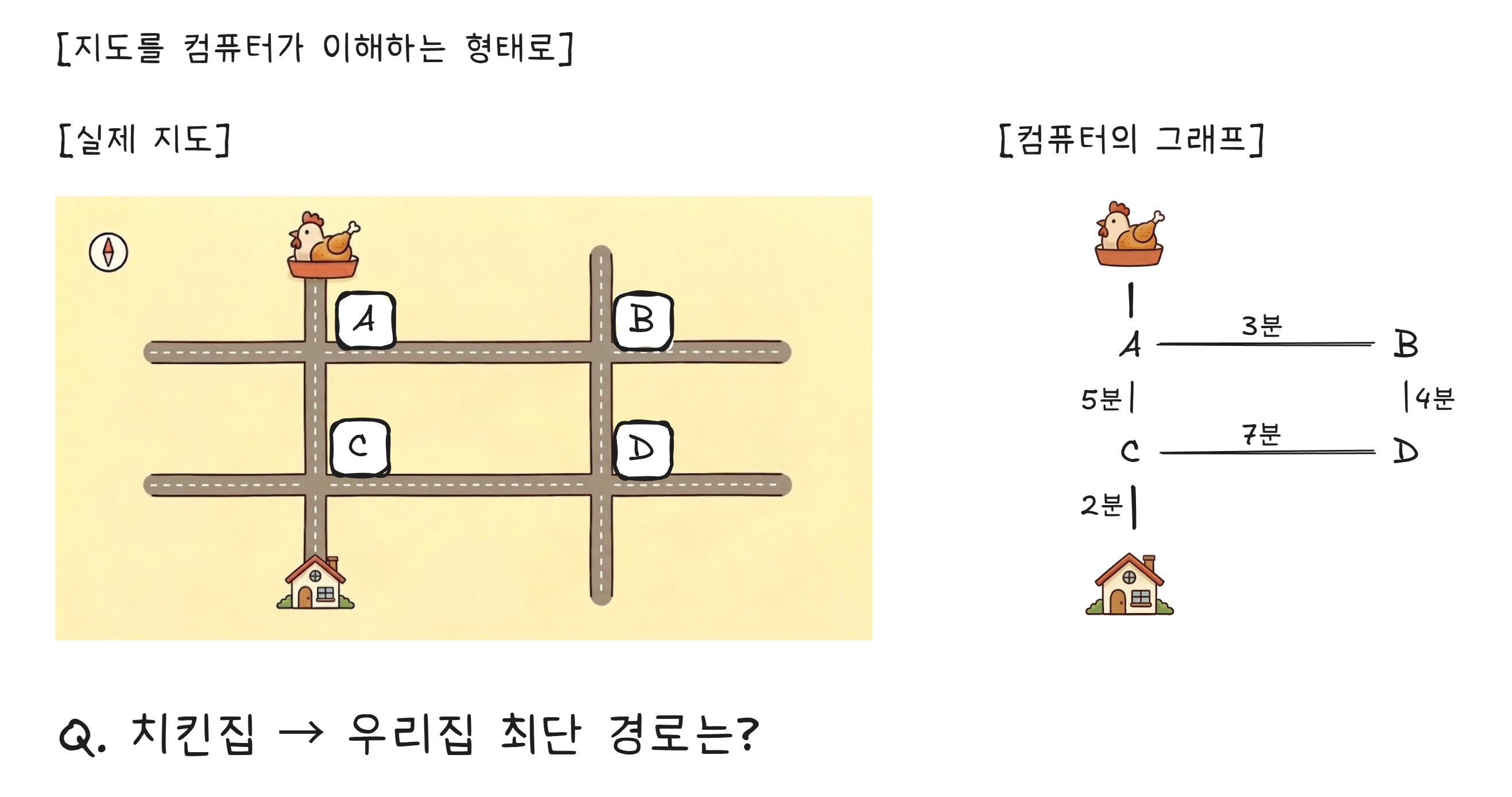
이 그래프2에서 최단 경로를 푸는 가장 유명한 알고리즘이 다익스트라(Dijkstra) 알고리즘입니다. 1956년 네덜란드 컴퓨터 과학자 에츠허르 다익스트라가 카페에서 종이 위에 20분 만에 고안했다고 합니다.
다익스트라 알고리즘의 아이디어는 간단합니다. “가장 가까운 곳부터 확정하고, 점점 넓혀간다“는 것입니다.
- 출발점(치킨집)에서 시작합니다.
- 바로 갈 수 있는 곳 중 가장 가까운 곳을 “확정“합니다.
- 확정된 곳에서 갈 수 있는 새로운 곳의 거리를 계산합니다.
- 아직 확정 안 된 곳 중 가장 가까운 곳을 다시 “확정“합니다.
- 목적지가 확정될 때까지 반복합니다.
마치 물이 퍼져나가듯, 출발점에서 가장 가까운 곳부터 차례로 확정하는 방식입니다.
구글 맵, 카카오맵, 네이버 지도 모두 이 알고리즘의 변형을 사용합니다. 물론 실제로는 도로의 수가 수백만 개이므로, 더 빠르게 계산하기 위한 다양한 최적화 기법이 추가됩니다.
실시간 교통: 지금 이 도로가 막히는지 어떻게 아는가
최단 거리가 항상 최단 시간은 아닙니다. 가장 짧은 도로가 교통 체증으로 막혀 있다면, 돌아가는 게 더 빠를 수 있습니다.
지도 앱은 실시간 교통 정보를 어디서 얻을까요? 답은 여러분의 폰입니다.
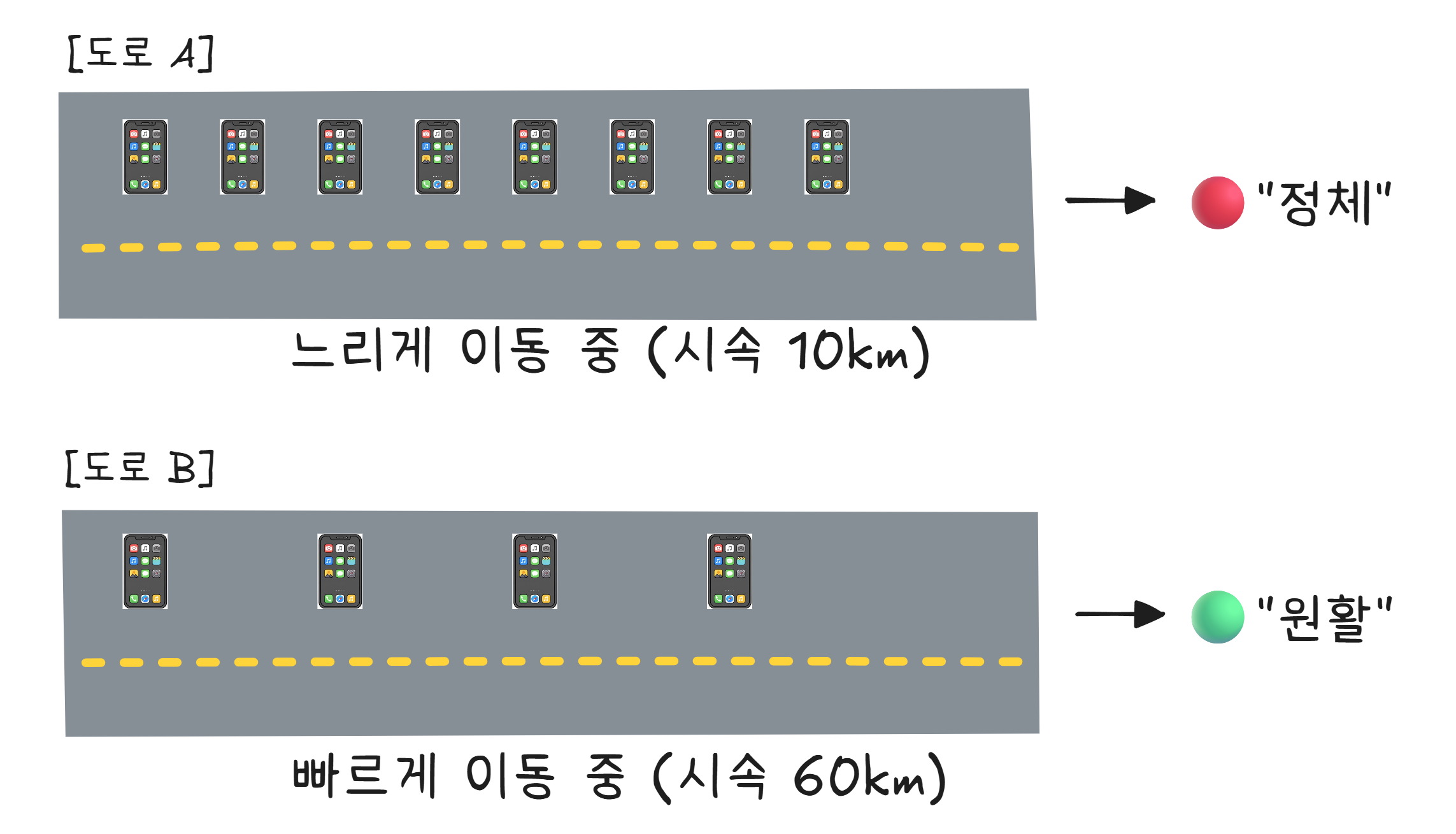
구글 맵은 안드로이드 폰의 위치 데이터를 (익명으로) 수집합니다. 카카오맵은 카카오 택시와 카카오 내비 사용자의 GPS 데이터를 활용합니다. 특정 도로에서 여러 대의 폰이 느리게 이동하면 “정체”, 빠르게 이동하면 “원활“로 판단합니다.
이것을 크라우드소싱(Crowdsourcing)3 이라고 합니다. 지도 앱을 사용하는 사람이 많을수록 교통 정보가 정확해집니다. 여러분이 내비게이션을 켜고 운전하는 것만으로도, 다른 사람의 내비게이션에 기여하고 있는 겁니다.
배달 예상 시간: “35분“은 어떻게 계산되나
“배달 예상 시간: 35분.” 이 숫자는 어떻게 나올까요? 단순히 “거리 ÷ 속도“로 계산하는 것이 아닙니다. 가게의 현재 주문량, 실시간 교통, 날씨, 요일, 시간대, 과거 배달 데이터까지 종합합니다. 이 모든 변수를 인간이 직접 계산하는 것은 불가능하므로, 머신러닝(Machine Learning)4 모델이 과거 수백만 건의 배달 데이터를 학습해서 예측합니다.
그래서 배달 예상 시간은 때로 정확하고, 때로 틀립니다. 예측 모델이 경험하지 못한 상황(갑작스러운 폭우, 사고로 인한 도로 차단)이 발생하면 오차가 커집니다.
사건: 대한항공 007편 — GPS가 민간에 개방된 계기
1983년 9월 1일, 뉴욕발 서울행 대한항공 007편이 소련 영공을 침범해 격추됩니다.5 탑승자 269명 전원이 사망했습니다.
사고 원인은 항법 장치의 설정 오류였습니다. 항로에서 수백 킬로미터 벗어나 소련 영공으로 진입한 것입니다. 소련은 이를 스파이 비행기로 판단하고 미사일을 발사했습니다.

이 사건 이후, 미국의 레이건 대통령은 군사용으로만 사용되던 GPS를 민간에 개방하겠다고 발표합니다.6 이런 비극이 다시 일어나지 않도록, 전 세계 민간 항공기가 정확한 위치를 알 수 있게 하겠다는 결정이었습니다.
다만 민간용 GPS에는 의도적으로 오차를 넣었습니다(SA: Selective Availability). 군사적 이유로 민간용 GPS의 정확도를 100m 수준으로 제한한 것입니다. 이 제한은 2000년 클린턴 대통령이 해제하면서, GPS 정확도가 약 10m 이내로 향상됩니다. 현재 스마트폰의 GPS가 이 정도 정확도를 가지는 이유입니다. 여기에 스마트폰은 GPS만 쓰는 것이 아니라 WiFi 신호, 기지국 위치, 가속도 센서까지 조합해서 위치를 보정합니다. 실내에서 GPS 신호가 약해져도 주변 WiFi 공유기의 위치 정보로 대략적 위치를 파악할 수 있는 것은 이 때문입니다.
알쓸신잡
-
GPS는 미국 것이다: GPS는 미국 국방부가 운영하는 시스템입니다. 미국이 마음먹으면 특정 지역의 GPS 신호를 의도적으로 교란하거나 끌 수 있습니다. 그래서 다른 나라들도 자체 위성 항법 시스템을 운영합니다. 러시아의 GLONASS, 유럽의 Galileo, 중국의 BeiDou(북두), 일본의 QZSS. 스마트폰은 보통 이 중 여러 개를 동시에 사용해서 정확도를 높입니다.
-
포켓몬 GO와 GPS 스푸핑: 2016년 포켓몬 GO가 출시되자, 집에서 편하게 포켓몬을 잡기 위해 GPS 스푸핑(Spoofing) — 가짜 GPS 신호를 보내서 위치를 속이는 것 — 이 유행합니다. 하지만 GPS 스푸핑은 게임에서만 쓰이는 것이 아닙니다. 2017년 흑해에서 약 20척의 선박이 동시에 GPS 위치가 내륙으로 표시되는 사건이 발생했는데, 러시아의 GPS 교란 실험으로 추정됩니다. 군사적 GPS 교란은 실제로 일어나고 있는 현실입니다.
-
스마트폰 99대로 가짜 교통 체증 만들기: 2020년, 베를린의 아티스트 Simon Weckert가 스마트폰 99대를 빨간 손수레에 싣고 텅 빈 거리를 걸어다녔습니다. 구글 맵은 이 도로를 극심한 정체로 표시했고, 실제 운전자들이 우회하기 시작했습니다. 차 한 대 없는 거리에 “가짜 교통 체증“이 만들어진 겁니다. 구글은 “자동차든, 손수레든, 낙타든, 구글 맵의 창의적인 활용을 환영합니다“라고 답했습니다.7 이 실험은 크라우드소싱 데이터를 우리가 얼마나 맹신하는지를 보여주는 사례입니다.
치킨이 오고 있습니다. 지도에서 배달원의 파란 점이 점점 가까워집니다. 그런데 다음에 배달앱을 열면, 앱이 “이 치킨집 어떠세요?“라고 추천할 겁니다. 내가 치킨을 좋아한다는 걸 어떻게 아는 걸까요? 내 취향을 어떻게 파악하는 걸까요?
-
삼변측량(Trilateration): 3개 이상의 기준점으로부터의 거리를 이용해 위치를 결정하는 방법. “삼각측량(Triangulation)“은 각도를 이용하는 것이고, GPS는 거리를 이용하므로 삼변측량이 정확한 표현이다. ↩
-
그래프(Graph): 점(노드)과 선(간선)으로 이루어진 자료구조. 지도, 소셜 네트워크(친구 관계), 인터넷(라우터 연결) 등 “연결 관계“를 표현하는 데 사용된다. ↩
-
크라우드소싱(Crowdsourcing): 대중(Crowd)에게서 정보나 서비스를 얻는(Sourcing) 것. 위키피디아(대중이 만드는 백과사전), 교통 정보(운전자가 만드는 교통 데이터) 등이 대표적. ↩
-
머신러닝(Machine Learning): 기계 학습. 컴퓨터가 데이터에서 패턴을 스스로 학습하여 예측하는 기술. 명시적으로 프로그래밍하지 않아도, 데이터를 많이 줄수록 예측이 정확해진다. ↩
-
1983년 9월 1일, 탑승자 269명 전원 사망. — Smithsonian National Air and Space Museum ↩
-
사건 2주 후 발표. — Reagan Presidential Library ↩
-
Simon Weckert, “Google Maps Hacks” (2020). 구글 대변인 공식 답변. — Android Authority ↩
12장. 추천 알고리즘: “이 치킨집 어떠세요?”
“추천 시스템, 머신러닝 기초, AI”
이번 장에서 알게 될 것
- 배달앱이 내 취향을 어떻게 파악하는지
- “당신과 비슷한 사람“을 찾는 알고리즘
- 넷플릭스가 추천 정확도 10% 향상에 100만 달러를 건 이유
- ChatGPT가 작동하는 원리를 한 문장으로
치킨 주문 여정: 다음에 앱을 열면
치킨이 도착했습니다. 맛있게 먹었습니다. 며칠 후, 배달앱을 다시 엽니다. “이 치킨집 어떠세요?” “교촌치킨 신메뉴 출시!” 내가 치킨을 좋아한다는 걸 어떻게 아는 걸까요?
당신과 비슷한 사람들이 이걸 좋아했습니다
넷플릭스에서 영화를 보면 “이 영화를 좋아한 사용자가 본 다른 영화“가 추천됩니다. 배달앱에서도 “치킨을 자주 시키는 사용자가 함께 주문한 메뉴“가 추천됩니다.
이것이 협업 필터링(Collaborative Filtering) 입니다. 핵심 아이디어는 간단합니다.
“나와 취향이 비슷한 사람이 좋아한 것은, 나도 좋아할 확률이 높다.”
| 사용자 | 치킨 | 피자 | 족발 |
|---|---|---|---|
| A (나) | ★★★★★ | ★★★ | ??? |
| B | ★★★★★ | ★★★ | ★★★★ |
| C | ★★ | ★★★★★ | ★★ |
A와 B는 치킨과 피자 평점이 비슷합니다. 취향이 비슷한 거죠. B가 족발에 별 네 개를 줬으니, A에게도 족발을 추천합니다. 내가 직접 족발을 먹어본 적이 없어도, 나와 취향이 비슷한 사용자가 족발을 좋아했으므로 나에게도 추천하는 것입니다.
이 방식이 강력한 이유는 이유를 몰라도 된다는 것입니다. 왜 치킨을 좋아하는 사람이 족발도 좋아하는지 알 필요가 없습니다. 데이터에서 패턴만 발견하면 됩니다.
콘텐츠 기반 필터링
협업 필터링 말고 다른 방식도 있습니다. 콘텐츠 기반 필터링(Content-Based Filtering) 은 상품의 특성을 분석합니다. 예를 들어, 내가 교촌치킨, 굽네치킨, BBQ치킨을 주문했다면 이 세 가게의 공통 특성은 “치킨“입니다. 그러면 같은 특성을 가진 BHC 뿌링클을 추천하는 식입니다.
현실의 추천 시스템은 둘을 함께 사용합니다. 협업 필터링으로 “비슷한 사용자“를 찾고, 콘텐츠 기반으로 “비슷한 상품“을 찾아서 결합합니다. 이것을 하이브리드 추천이라고 합니다.
콜드 스타트 문제
하지만 추천 시스템에는 근본적인 약점이 있습니다. 새로운 사용자가 가입하면 이 사람의 취향 데이터가 전혀 없습니다. 비슷한 사용자를 찾을 수도 없고, 과거 주문 기록도 없습니다. 이것을 콜드 스타트 문제(Cold Start Problem) 라고 합니다.
배달앱을 처음 설치하면 “좋아하는 음식 종류를 선택하세요” 같은 질문이 나오는 이유가 바로 이것입니다. 최소한의 데이터라도 확보해서 추천을 시작하려는 것이죠. 넷플릭스도 가입 직후 “좋아하는 영화 3개를 골라주세요“라고 요청합니다. 이 선택 하나하나가 추천 엔진의 씨앗이 됩니다.
새 가게가 등록될 때도 마찬가지입니다. 아무도 주문한 적 없는 가게는 협업 필터링으로 추천할 수 없습니다. 이때는 가게의 메뉴, 가격대, 위치 같은 속성을 분석하는 콘텐츠 기반 필터링이 먼저 작동합니다. 주문이 쌓이면 그때부터 협업 필터링이 함께 돌아가기 시작합니다.
넷플릭스 100만 달러 챌린지
2006년, 넷플릭스는 파격적인 대회를 엽니다.
“우리의 추천 알고리즘(Cinematch) 정확도를 10% 이상 향상시키는 팀에게 100만 달러를 드립니다.”
고작 10%에 100만 달러라니, 과하다고 생각할 수 있습니다. 하지만 넷플릭스에게 추천 정확도 10%는 수억 달러의 가치가 있었습니다. 추천이 정확할수록 사용자가 볼 콘텐츠를 빨리 찾고, 만족도가 올라가고, 구독을 유지합니다. 추천이 부정확하면 “볼 게 없네” 하고 구독을 해지합니다.
3년간 186개국에서 4만 개 팀이 참가했고, 2009년 BellKor’s Pragmatic Chaos라는 팀이 10.06% 향상을 달성하며 우승합니다. 이 대회에서 발견된 핵심 교훈은 다음과 같습니다.
- 단일 알고리즘보다 여러 알고리즘의 조합, 즉 앙상블1이 훨씬 효과적이다.
- 사용자의 평점만이 아니라 “언제 봤는지“도 중요하다.
- 평점을 매기는 행위 자체가 선택 편향을 가진다. 아주 좋거나 아주 싫을 때만 평점을 매기는 경향이 있기 때문이다.
이 대회는 추천 시스템 연구의 전환점이 되었습니다. 현재 넷플릭스가 보여주는 콘텐츠의 80% 이상이 추천 알고리즘을 통해 선택된다고 합니다.
필터 버블: 추천이 너무 잘 되면 세상이 좁아진다
추천 알고리즘이 정확해질수록 좋기만 한 것일까요?
내가 치킨만 시키면, 앱은 계속 치킨만 추천합니다. 피자, 중식, 일식은 화면에서 사라집니다. 유튜브에서 게임 영상만 보면, 추천 피드가 온통 게임으로 채워집니다. 요리, 여행, 과학 영상은 눈에 띄지 않게 됩니다.
이것을 필터 버블(Filter Bubble)2 이라고 합니다.
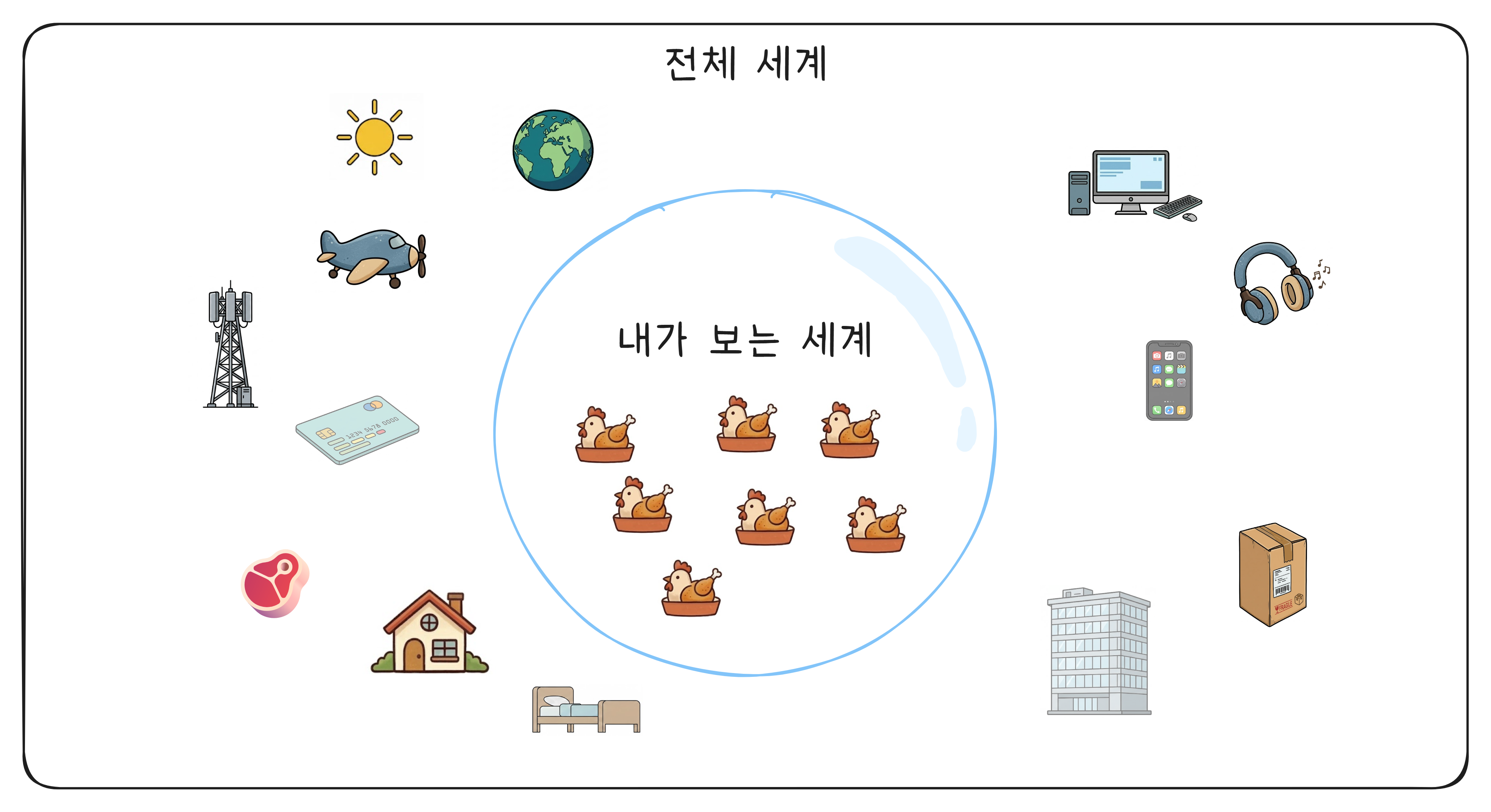
유튜브에서 음모론 영상을 한 번 보면, 관련 영상이 끝없이 추천되면서 점점 깊은 토끼굴로 빠져드는 현상이 대표적입니다. 알고리즘은 “이 사용자가 클릭한 것“을 더 보여줄 뿐, “이 사용자에게 좋은 것“을 판단하지 못합니다. 실제로 유튜브에서 시청되는 콘텐츠의 약 **70%**가 추천 알고리즘에 의해 선택됩니다.3 내가 무엇을 볼지를 내가 아니라 알고리즘이 결정하는 셈입니다.
틱톡의 알고리즘이 유독 중독적인 이유도 여기에 있습니다. 틱톡은 짧은 영상을 끊임없이 보여주면서, 사용자가 어떤 영상에서 멈추고, 어떤 영상을 빠르게 넘기는지를 밀리초 단위로 분석합니다. 영상을 3초 만에 넘겼는지, 끝까지 봤는지, 다시 봤는지 — 이 모든 데이터가 다음 추천에 반영됩니다. 사용자가 “좋아요“를 누르기도 전에, 행동 자체가 데이터입니다.
ChatGPT: “다음 단어 예측기”
추천 알고리즘에서 한 발 더 나아가면, AI(인공지능) 이야기가 됩니다.
2022년 11월에 공개된 ChatGPT는 대화하듯 질문에 답하고, 글을 쓰고, 코드를 작성합니다. 이 기술의 핵심을 한 문장으로 요약하면 이렇습니다.
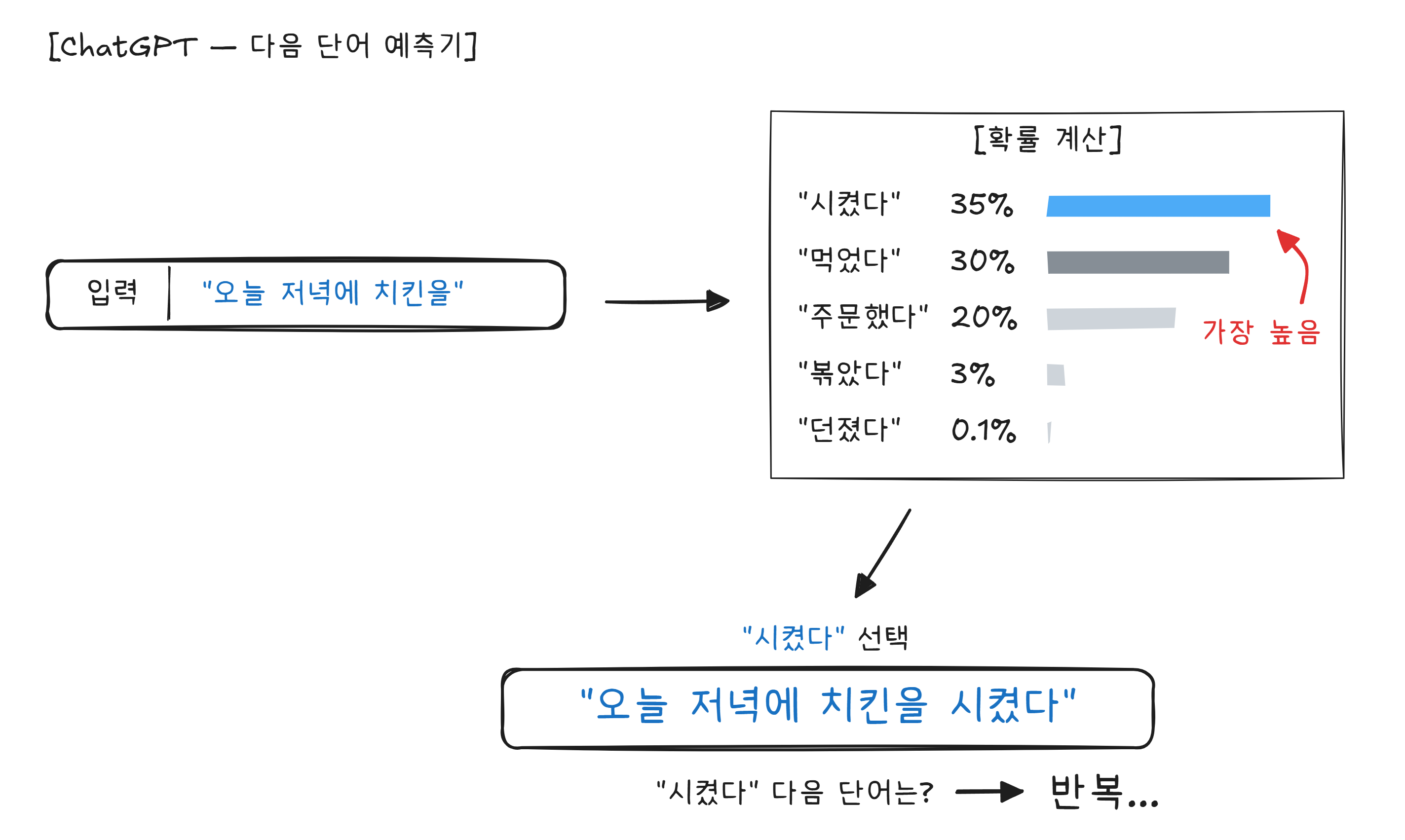
“주어진 텍스트 다음에 올 확률이 가장 높은 단어를 예측하는 것”
“오늘 저녁에 치킨을“이라는 문장 다음에 올 단어로 “시켰다“가 올 확률은 높고, “던졌다“가 올 확률은 낮습니다. 이 확률을 수조 개의 텍스트 데이터에서 학습한 것이 대규모 언어 모델(LLM)4 입니다.
수만 권의 책, 수십억 개의 웹페이지를 학습한 모델은 “다음 단어 예측“이라는 단순한 과제를 수행할 뿐인데, 그 결과물이 마치 이해하고 사고하는 것처럼 보입니다. 번역을 하고, 시를 쓰고, 수학 문제를 풀고, 코드를 작성합니다.
이것이 진정한 “이해“인지, 아니면 패턴의 정교한 모방인지는 현재 AI 분야에서 가장 뜨거운 논쟁 중 하나입니다.
학습의 규모는 상상을 초월합니다. ChatGPT의 기반이 된 GPT 시리즈는 위키피디아 전체, 수백만 개의 웹페이지, 수만 권 분량의 텍스트를 학습 데이터로 사용했습니다. 모델 내부에는 수천억 개의 **매개변수(parameter)**가 있으며, 이것이 텍스트의 패턴을 저장합니다. 뇌의 시냅스가 경험을 저장하듯, 매개변수가 언어의 패턴을 저장하는 것이죠.
그런데 이 모델이 바로 ChatGPT가 되는 것은 아닙니다. 대량의 텍스트로 학습한 모델은 “다음 단어 예측“은 잘하지만, 사람과 자연스럽게 대화하지는 못합니다. 여기에 **인간 피드백 강화학습(RLHF)5**이라는 단계가 추가됩니다. 사람이 모델의 여러 답변 중 더 나은 것을 골라주면, 모델이 그 선호를 학습합니다. “이렇게 대답하면 사람이 더 만족한다“를 배우는 과정입니다.
사건: 아마존 채용 AI의 성별 편향
2018년, 아마존이 채용에 사용하던 AI 시스템이 여성 지원자를 체계적으로 불이익 처리하고 있었다는 사실이 밝혀집니다.6
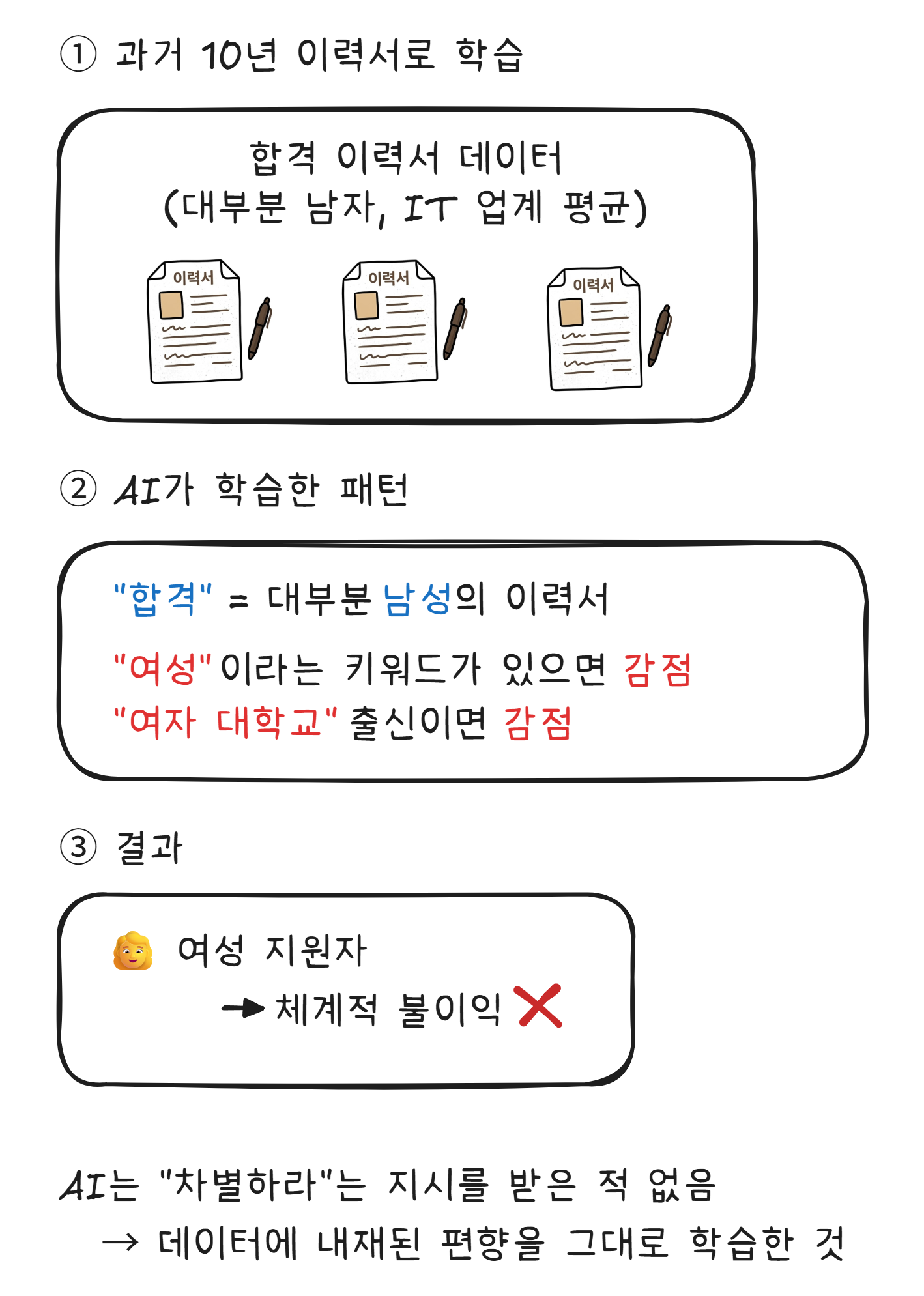
AI는 주어진 데이터에서 패턴을 학습합니다. 데이터에 편향이 있으면, AI도 편향을 학습합니다. “과거에 이런 사람이 합격했다“를 학습한 AI는 미래에도 같은 패턴을 반복합니다. 세상이 변해야 하는 부분까지 과거의 패턴으로 고정시키는 겁니다.
아마존은 이 시스템을 폐기했습니다. 하지만 이 사건은 중요한 질문을 던집니다 — AI가 공정한지는 AI가 아니라, AI에 넣는 데이터가 결정한다.
이 사건 이후, AI 윤리와 공정성은 AI 연구의 핵심 주제가 되었습니다. 학습 데이터의 편향을 감지하고 교정하는 기법, AI가 왜 그런 결정을 내렸는지 설명할 수 있게 만드는 설명 가능한 AI(Explainable AI, XAI) 연구가 활발해졌습니다.
알쓸신잡
-
CAPTCHA로 AI를 학습시키고 있다: 10장에서 CAPTCHA 이야기를 했습니다. 사실 한 발 더 나아가면, 구글의 reCAPTCHA에서 “이 사진에서 버스를 모두 고르세요” 같은 문제에 답할 때, 여러분은 자율주행 AI의 학습 데이터를 라벨링하고 있는 것입니다. 사람이 “이것은 버스다”, “이것은 신호등이다“라고 알려주면, AI가 그것을 학습합니다. 전 세계 수억 명이 무료로 AI 학습에 참여하고 있는 셈입니다.
-
AI가 그린 그림의 저작권은 누구에게?: AI 이미지 생성 모델(Midjourney, DALL-E 등)이 만든 그림의 저작권 문제는 아직 해결되지 않았습니다. AI가 학습한 원본 작가의 그림은? AI를 사용한 사람의 권리는? AI 자체의 저작권은? 2023년 미국 저작권청은 “AI가 생성한 이미지에는 저작권을 부여하지 않는다“고 결정했지만, “AI를 도구로 사용하되 인간이 창작적 기여를 한 경우“는 인정할 수 있다고 단서를 붙였습니다.7 법과 기술의 간극이 그 어느 때보다 벌어지고 있는 영역입니다.
-
추천 알고리즘은 “최적“이 아니라 “이익“을 추구한다: 유튜브 알고리즘은 사용자에게 “최고의 영상“을 추천하는 것이 아니라, “가장 오래 머물게 하는 영상” 을 추천합니다. 사용자의 시청 시간이 길수록 더 많은 광고를 보여줄 수 있기 때문입니다. 같은 논리로 배달앱은 “가장 맛있는 가게“가 아니라 “가장 많이 주문하게 만드는 가게“를 상위에 노출할 유인8이 있습니다. 알고리즘이 최적화하는 대상이 무엇인지를 아는 것이 중요합니다 — 그것이 항상 사용자의 이익과 일치하지는 않습니다.
배달 완료까지 10분
치킨이 도착했고, 맛있게 먹었습니다. 그리고 배달앱은 이 주문을 기억합니다. 다음에 앱을 열면 치킨집이 상단에 뜨고, “이 치킨집 어떠세요?“라는 추천이 나타날 것입니다.
돌아보면, 치킨 한 마리를 시키는 동안 놀라운 일들이 벌어졌습니다. 터치스크린이 손가락을 감지하고, 운영체제가 명령을 처리하고, WiFi와 LTE가 전파를 쏘고, 해저 케이블이 빛의 신호를 전달하고, DNS가 주소를 찾고, TCP가 데이터를 검증하고, 서버가 검색 결과를 돌려주고, 데이터베이스가 메뉴를 불러오고, 암호화가 결제를 보호하고, GPS가 배달 경로를 계산하고, 추천 알고리즘이 다음 주문을 예측했습니다.
컴퓨터 과학의 거의 모든 분야가 동원된 이 여정은, 여러분이 주문 버튼을 누른 그 10분 안에 모두 일어났습니다.
-
앙상블(Ensemble): 여러 개의 모델(알고리즘)의 예측을 결합해서 하나의 더 정확한 예측을 만드는 기법. 한 사람의 의견보다 여러 전문가의 종합 의견이 정확한 것과 같은 원리. ↩
-
필터 버블(Filter Bubble): 알고리즘이 사용자가 좋아할 만한 정보만 보여주면서, 사용자가 자신만의 “거품” 안에 갇히는 현상. 2011년 엘리 패리서가 만든 용어. ↩
-
유튜브 추천의 시청 시간 기여: YouTube CPO Neal Mohan 인터뷰, CNET (2018). https://www.cnet.com/tech/services-and-software/youtube-ces-2018-neal-mohan/ ↩
-
LLM(Large Language Model): 대규모 언어 모델. 방대한 텍스트 데이터로 학습한 AI 모델. GPT, Claude, Gemini 등이 대표적. ↩
-
RLHF(Reinforcement Learning from Human Feedback): 인간 피드백 강화학습. AI 모델의 답변을 사람이 평가하고, 그 평가를 바탕으로 모델을 개선하는 기법. ↩
-
아마존 AI 채용 성별 편향: Jeffrey Dastin, “Amazon scraps secret AI recruiting tool that showed bias against women”, Reuters (2018.10.10). https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G ↩
-
AI 저작권 결정: U.S. Copyright Office, “Zarya of the Dawn” Registration Decision (2023.02.21). https://www.copyright.gov/docs/zarya-of-the-dawn.pdf ↩
-
유인(Incentive): 특정 행동을 하게 만드는 동기나 보상. 경제학에서 개인이나 기업의 행동을 설명하는 핵심 개념. ↩
에필로그: 치킨이 도착했다
초인종이 울립니다.
문을 열면 배달원이 서 있습니다. “양념 반 후라이드 반이요.” 치킨을 받아들고 문을 닫습니다. 소파에 앉아 치킨 박스를 열고 한 조각을 집어 듭니다.
금요일 저녁 9시 10분. 치킨이 도착했습니다.
이 10분 동안 무슨 일이 벌어졌는지, 이제 우리는 압니다.
손가락이 스마트폰 화면에 닿는 순간 정전용량 센서가 전기 변화를 감지했습니다. 운영체제가 초당 수천 번의 컨텍스트 스위칭으로 앱을 실행시켰습니다. 전자기파가 초속 30만 킬로미터로 공유기를 향해 날아갔습니다. 데이터는 광섬유를 타고 전반사를 반복하며 데이터센터에 도착했습니다.
DNS가 주소를 찾았습니다. IP가 경로를 잡았습니다. 라우터들이 릴레이를 했습니다. TCP가 패킷 하나도 빠지지 않았는지 확인했습니다. 검색 엔진이 수십만 개의 치킨집에서 역 인덱스를 뒤져 0.3초 만에 결과를 골랐습니다. 데이터베이스가 메뉴와 가격과 리뷰를 꺼내놓았습니다.
카드 번호는 비대칭 암호로 감싸져 인터넷을 건넜습니다. 인증서가 상대방이 진짜인지 확인했습니다. 비밀번호는 해싱되어 서버조차 원본을 모르는 채로 로그인이 확인되었습니다. GPS 위성 4개가 배달원의 위치를 삼변측량으로 잡아냈고, 상대성이론이 시계 오차를 보정했습니다. 다익스트라 알고리즘이 최적의 배달 경로를 계산했습니다.
그리고 다음에 앱을 열면, 협업 필터링이 “이 치킨집은 어떠세요?“라고 물어올 겁니다.
알고 나면 같은 것도 다르게 보입니다.
WiFi가 안 터질 때 2.4GHz와 5GHz 대역을 떠올리게 됩니다. 브라우저에 자물쇠 아이콘이 보이면 TLS Handshake가 이루어졌다는 것을 알게 됩니다. 게임에서 핑이 높을 때 그것이 물리 법칙의 한계라는 것을 이해하게 됩니다. “비밀번호 찾기“를 했을 때 왜 원래 비밀번호를 안 알려주는지도 이제 알 수 있습니다.
다음에 치킨을 시킬 때, 엔터를 누르는 그 순간을 한번 떠올려 보세요.
그 여정을 아는 것만으로도, 치킨이 조금 더 맛있어질지 모릅니다.
참고 자료
본문에서 인용하거나 참고한 외부 자료의 출처를 정리합니다. 각 챕터 본문의 각주 번호가 이 페이지의 항목과 연결됩니다.
프롤로그
| # | 내용 | 출처 |
|---|---|---|
| 1 | 쇼클리, 바딘, 브래튼 — 1956년 노벨 물리학상 (트랜지스터) | NobelPrize.org |
| 2 | 찰스 카오 — 2009년 노벨 물리학상 (광섬유 통신) | NobelPrize.org |
| 3 | GPS의 상대성이론 시간 보정 | NASA |
| 4 | 마이클 패러데이 — 전자기 연구, 정전용량(farad) | Encyclopaedia Britannica |
1장: 유리판이 내 손가락을 아는 법
| # | 내용 | 출처 |
|---|---|---|
| 1 | 갤럭시 노트7 배터리 리콜 (2016) | U.S. CPSC 리콜 공고 |
| 2 | 갤럭시 노트7 항공편 반입 금지 (2016) | U.S. DOT 긴급 명령 |
| 3 | E.A. Johnson, 최초 정전식 터치스크린 (1965) | Wikipedia: Touchscreen |
| 4 | LG 프라다 — 최초 정전식 터치 휴대폰 (2007) | GSMArena |
2장: 이 앱은 어떻게 실행되는가
| # | 내용 | 출처 |
|---|---|---|
| 1 | 아이폰 1970년 날짜 버그 (2016) | 9to5Mac |
| 2 | 2038년 문제 (32비트 유닉스 시간 오버플로) | Wikipedia: Year 2038 problem |
3장: 보이지 않는 고속도로
| # | 내용 | 출처 |
|---|---|---|
| 1 | CrowdStrike 블루스크린 사태 (2024.7.19, 850만 대) | CrowdStrike 사고 보고서 |
| 2 | 하랄드 블로탄 — 블루투스 이름의 유래 | Bluetooth.com |
| 3 | 알렉산더 그레이엄 벨, 꼬임선 특허 (1881) | Google Patents: US244426 |
| 4 | 한국 세계 최초 CDMA 상용화 (1996) | IEEE Milestone |
4장: 바다 밑의 실
| # | 내용 | 출처 |
|---|---|---|
| 1 | 통가 해저케이블 절단 (2022) | NPR |
5장: 주소를 찾아서
| # | 내용 | 출처 |
|---|---|---|
| 1 | Facebook BGP 다운 (2021.10.4) | Engineering at Meta |
| 2 | 파키스탄 유튜브 BGP 차단 (2008) | RIPE NCC 분석 |
| 3 | Dyn DDoS 공격 (2016) | Wikipedia — DDoS attacks on Dyn |
6장: 등기 택배와 전단지
| # | 내용 | 출처 |
|---|---|---|
| 1 | Firesheep 세션 탈취 도구 (2010) | Eric Butler — Firesheep |
7장: 수십억 개의 웹페이지에서 0.3초 만에 찾기
| # | 내용 | 출처 |
|---|---|---|
| 1 | 구글 판다 업데이트 (2011) | Google Search Central Blog |
| 2 | 구글 펭귄 업데이트 (2012) | Google Search Central Blog |
8장: 데이터를 담는 그릇
| # | 내용 | 출처 |
|---|---|---|
| 1 | GitLab 데이터베이스 삭제 사건 (2017) | GitLab Postmortem |
9장: 인터넷에서 돈을 보내는 법
| # | 내용 | 출처 |
|---|---|---|
| 1 | Target 카드 정보 유출 (2013) | Krebs on Security |
| 2 | Heartbleed 취약점 (2014) | heartbleed.com |
| 3 | Heartbleed — CISA 보안 권고 | CISA |
10장: 비밀번호는 어디에 저장되나
| # | 내용 | 출처 |
|---|---|---|
| 1 | LinkedIn 비밀번호 유출 (2012, 1억 1,700만 건) | Krebs on Security |
11장: 지도 앱은 어떻게 길을 찾는가
| # | 내용 | 출처 |
|---|---|---|
| 1 | 대한항공 007편 격추 (1983) → GPS 민간 개방 | Smithsonian National Air and Space Museum |
| 2 | 레이건 대통령 GPS 민간 개방 발표 | Reagan Presidential Library |
| 3 | GPS 상대성이론 보정 (38.6μs/일) | NASA |
12장: 추천 알고리즘 — “이 치킨집 어떠세요?”
| # | 내용 | 출처 |
|---|---|---|
| 1 | 아마존 채용 AI 여성 차별 (2018) | Reuters |
| 2 | Netflix Prize 100만 달러 (2006~2009) | Wikipedia — Netflix Prize |
| 3 | 유튜브 추천 알고리즘 — 시청 시간의 70% 기여 | CNET — YouTube CPO Neal Mohan (2018) |
| 4 | AI 저작권 — “Zarya of the Dawn” 결정 (2023) | U.S. Copyright Office |
에필로그
| # | 내용 | 출처 |
|---|---|---|
| — | 에필로그는 본문 각 챕터의 내용을 요약한 것으로, 개별 출처는 해당 챕터를 참조합니다. |
이 책에 대하여
이 책의 구성
이 책은 하나의 행위를 처음부터 끝까지 따라갑니다.
스마트폰으로 치킨 한 마리를 주문하는 것.
손가락이 화면에 닿는 순간부터 치킨이 문 앞에 도착하기까지, 약 10분. 그 사이에 동원되는 기술을 하나씩 쫓아갑니다. 터치스크린에서 출발해 운영체제, 전파, 해저케이블, DNS, TCP, 검색엔진, 데이터베이스, 암호화, GPS, 인공지능까지 — 컴퓨터 과학의 거의 모든 분야를 한 번씩 지나게 됩니다.
전체 12장이 6개의 Part로 묶여 있고, 각 Part는 치킨 주문 여정의 한 구간에 해당합니다.
목차
프롤로그 — 치킨 한 마리 시키는 데 노벨상 수상자가 몇 명 필요할까?
Part 1. 손가락 끝에서 벌어지는 일
스마트폰을 집어 들고, 화면을 터치하고, 앱이 실행되기까지.
- 1장. 유리판이 내 손가락을 아는 법 — 터치스크린, 디스플레이, 빛의 삼원색
- 2장. 이 앱은 어떻게 실행되는가 — 운영체제, 프로세스, 메모리
Part 2. 전파를 타고 건물 밖으로
“치킨“을 검색한 데이터가 스마트폰 밖으로 나가 세계를 건너는 여정.
- 3장. 보이지 않는 고속도로 — WiFi, LTE/5G, 블루투스, 전자레인지
- 4장. 바다 밑의 실 — 해저케이블, 데이터센터, 클라우드의 정체
Part 3. “치킨집 검색” 버튼을 눌렀다
데이터가 목적지를 찾아가고, 서버에 도착하는 과정.
- 5장. 주소를 찾아서 — DNS, IP, 라우팅
- 6장. 등기 택배와 전단지 — TCP, UDP, 포트, 방화벽
Part 4. 서버 안에서 벌어지는 일
서버가 “치킨집“을 찾아 결과를 보여주기까지.
- 7장. 수십억 개의 웹페이지에서 0.3초 만에 찾기 — 검색엔진, 인덱싱, 알고리즘
- 8장. 데이터를 담는 그릇 — 데이터베이스, SQL, NoSQL
Part 5. 결제 버튼을 눌렀다
카드 정보가 인터넷을 안전하게 건너고, 본인 인증이 이루어지는 과정.
- 9장. 인터넷에서 돈을 보내는 법 — 암호화, HTTPS, 결제 시스템
- 10장. 비밀번호는 어디에 저장되나 — 해싱, 인증, 2FA
Part 6. 치킨이 출발했습니다
결제가 끝나고, 배달원이 길을 찾아 치킨을 가져오기까지.
- 11장. 지도 앱은 어떻게 길을 찾는가 — GPS, 경로 탐색 알고리즘
- 12장. 추천 알고리즘: “이 치킨집 어떠세요?” — 추천 시스템, 머신러닝, AI
에필로그 — 치킨이 도착했다
이 책을 읽는 법
이 책은 앞에서부터 순서대로 읽도록 설계되어 있습니다. 치킨 주문이라는 하나의 스토리가 1장부터 12장까지 이어지기 때문입니다.
하지만 꼭 그래야 할 필요는 없습니다. 각 장은 독립적으로 읽혀도 이해할 수 있도록 썼습니다. 목차를 보고 끌리는 제목부터 펼쳐도 됩니다. “비밀번호는 어디에 저장되나“가 궁금하면 10장부터, “WiFi가 왜 벽을 못 뚫는지“가 궁금하면 3장부터 읽으면 됩니다.
모든 장은 같은 패턴으로 구성되어 있습니다.
- 일상의 물음으로 시작합니다. “왜 장갑 끼면 터치가 안 되지?” 같은, 한 번쯤 궁금했지만 검색해보지는 않았던 질문입니다.
- 원리 설명이 이어집니다. 비유로 시작해서 실제 작동 방식으로 들어갑니다.
- 실제 사건을 다룹니다. 그 기술이 망가졌을 때 무슨 일이 벌어졌는지 — 기술의 중요성은 없어졌을 때 가장 잘 드러납니다.
- 알쓸신잡으로 쉬어갑니다. 본문에 넣기엔 아까운 잡학들입니다.
이 책에는 코드가 없고, 수식도 없습니다. 전공자가 아니어도 읽을 수 있습니다. 다만, 전공자가 읽어도 “어, 이건 몰랐는데“라는 대목이 있도록 신경 썼습니다.
작가의 말
저는 게임도 만들고, 웹 서비스도 기획하고, 요즘은 AI도 공부하고 있습니다. 하나의 분야에 정착하지 못하는 게 아니라, 기술이라는 것 자체가 좋아서 이것저것 손을 대다 보니 그렇게 되었습니다. 그러다 보면 자연스럽게 가르치는 일도 하게 됩니다. 가르치면서 알게 된 것이 있습니다.
사람들이 정말 궁금해하는 건 사용법이 아니라 원리라는 것. “이거 어떻게 써요?“보다 “이거 어떻게 돌아가는 거예요?“라는 질문이 훨씬 많았습니다. 그런데 이 질문에 제대로 답해주는 글이 의외로 없었습니다. 그래서 한번 처음부터 끝까지 이어지는 글을 써보고 싶었습니다.
치킨 한 마리를 시키는 동안 벌어지는 일을 하나의 이야기로 풀어보면, 인터넷이 돌아가는 전체 그림이 보이지 않을까 하는 생각이었습니다. 코드 없고, 수식 없습니다. 모든 설명은 비유로 시작하고, 실제 원리로 이어집니다. 각 장 끝에는 그 기술이 실제로 망가졌던 사건을 넣었습니다. 기술의 중요성은 잘 작동할 때보다 고장났을 때 더 잘 드러니까요. 다 읽고 나서 배달 앱을 열 때, 화면 뒤에서 벌어지는 일이 조금이라도 그려진다면 이 책은 제 역할을 다한 겁니다.
작가 소개
게임 개발을 가르치고, 가끔 게임 플러그인을 만들고, 틈틈이 대학원에서 AI를 공부하고 있습니다. 언리얼 엔진(UE5) 공인 인증 강사(UAI)이며, 여러 나라를 오가며 일하는 디지털 노마드이기도 합니다. 기술을 설명할 때 “쉽게“보다 “정확하게, 그런데 읽히게“를 더 중요하게 생각합니다. 복잡한 개념을 일상의 비유로 풀어내는 걸 좋아하고, 그 습관이 강의실 밖으로 삐져나오면 책이 됩니다.
YOUTUBE: Simon Jo
본 서적에 사용된 회사명 및 로고는 각 회사의 등록 상표이며, 설명 목적으로만 사용되었습니다.