12장. 추천 알고리즘: “이 치킨집 어떠세요?”
“추천 시스템, 머신러닝 기초, AI”
이번 장에서 알게 될 것
- 배달앱이 내 취향을 어떻게 파악하는지
- “당신과 비슷한 사람“을 찾는 알고리즘
- 넷플릭스가 추천 정확도 10% 향상에 100만 달러를 건 이유
- ChatGPT가 작동하는 원리를 한 문장으로
치킨 주문 여정: 다음에 앱을 열면
치킨이 도착했습니다. 맛있게 먹었습니다. 며칠 후, 배달앱을 다시 엽니다. “이 치킨집 어떠세요?” “교촌치킨 신메뉴 출시!” 내가 치킨을 좋아한다는 걸 어떻게 아는 걸까요?
당신과 비슷한 사람들이 이걸 좋아했습니다
넷플릭스에서 영화를 보면 “이 영화를 좋아한 사용자가 본 다른 영화“가 추천됩니다. 배달앱에서도 “치킨을 자주 시키는 사용자가 함께 주문한 메뉴“가 추천됩니다.
이것이 협업 필터링(Collaborative Filtering) 입니다. 핵심 아이디어는 간단합니다.
“나와 취향이 비슷한 사람이 좋아한 것은, 나도 좋아할 확률이 높다.”
| 사용자 | 치킨 | 피자 | 족발 |
|---|---|---|---|
| A (나) | ★★★★★ | ★★★ | ??? |
| B | ★★★★★ | ★★★ | ★★★★ |
| C | ★★ | ★★★★★ | ★★ |
A와 B는 치킨과 피자 평점이 비슷합니다. 취향이 비슷한 거죠. B가 족발에 별 네 개를 줬으니, A에게도 족발을 추천합니다. 내가 직접 족발을 먹어본 적이 없어도, 나와 취향이 비슷한 사용자가 족발을 좋아했으므로 나에게도 추천하는 것입니다.
이 방식이 강력한 이유는 이유를 몰라도 된다는 것입니다. 왜 치킨을 좋아하는 사람이 족발도 좋아하는지 알 필요가 없습니다. 데이터에서 패턴만 발견하면 됩니다.
콘텐츠 기반 필터링
협업 필터링 말고 다른 방식도 있습니다. 콘텐츠 기반 필터링(Content-Based Filtering) 은 상품의 특성을 분석합니다. 예를 들어, 내가 교촌치킨, 굽네치킨, BBQ치킨을 주문했다면 이 세 가게의 공통 특성은 “치킨“입니다. 그러면 같은 특성을 가진 BHC 뿌링클을 추천하는 식입니다.
현실의 추천 시스템은 둘을 함께 사용합니다. 협업 필터링으로 “비슷한 사용자“를 찾고, 콘텐츠 기반으로 “비슷한 상품“을 찾아서 결합합니다. 이것을 하이브리드 추천이라고 합니다.
콜드 스타트 문제
하지만 추천 시스템에는 근본적인 약점이 있습니다. 새로운 사용자가 가입하면 이 사람의 취향 데이터가 전혀 없습니다. 비슷한 사용자를 찾을 수도 없고, 과거 주문 기록도 없습니다. 이것을 콜드 스타트 문제(Cold Start Problem) 라고 합니다.
배달앱을 처음 설치하면 “좋아하는 음식 종류를 선택하세요” 같은 질문이 나오는 이유가 바로 이것입니다. 최소한의 데이터라도 확보해서 추천을 시작하려는 것이죠. 넷플릭스도 가입 직후 “좋아하는 영화 3개를 골라주세요“라고 요청합니다. 이 선택 하나하나가 추천 엔진의 씨앗이 됩니다.
새 가게가 등록될 때도 마찬가지입니다. 아무도 주문한 적 없는 가게는 협업 필터링으로 추천할 수 없습니다. 이때는 가게의 메뉴, 가격대, 위치 같은 속성을 분석하는 콘텐츠 기반 필터링이 먼저 작동합니다. 주문이 쌓이면 그때부터 협업 필터링이 함께 돌아가기 시작합니다.
넷플릭스 100만 달러 챌린지
2006년, 넷플릭스는 파격적인 대회를 엽니다.
“우리의 추천 알고리즘(Cinematch) 정확도를 10% 이상 향상시키는 팀에게 100만 달러를 드립니다.”
고작 10%에 100만 달러라니, 과하다고 생각할 수 있습니다. 하지만 넷플릭스에게 추천 정확도 10%는 수억 달러의 가치가 있었습니다. 추천이 정확할수록 사용자가 볼 콘텐츠를 빨리 찾고, 만족도가 올라가고, 구독을 유지합니다. 추천이 부정확하면 “볼 게 없네” 하고 구독을 해지합니다.
3년간 186개국에서 4만 개 팀이 참가했고, 2009년 BellKor’s Pragmatic Chaos라는 팀이 10.06% 향상을 달성하며 우승합니다. 이 대회에서 발견된 핵심 교훈은 다음과 같습니다.
- 단일 알고리즘보다 여러 알고리즘의 조합, 즉 앙상블1이 훨씬 효과적이다.
- 사용자의 평점만이 아니라 “언제 봤는지“도 중요하다.
- 평점을 매기는 행위 자체가 선택 편향을 가진다. 아주 좋거나 아주 싫을 때만 평점을 매기는 경향이 있기 때문이다.
이 대회는 추천 시스템 연구의 전환점이 되었습니다. 현재 넷플릭스가 보여주는 콘텐츠의 80% 이상이 추천 알고리즘을 통해 선택된다고 합니다.
필터 버블: 추천이 너무 잘 되면 세상이 좁아진다
추천 알고리즘이 정확해질수록 좋기만 한 것일까요?
내가 치킨만 시키면, 앱은 계속 치킨만 추천합니다. 피자, 중식, 일식은 화면에서 사라집니다. 유튜브에서 게임 영상만 보면, 추천 피드가 온통 게임으로 채워집니다. 요리, 여행, 과학 영상은 눈에 띄지 않게 됩니다.
이것을 필터 버블(Filter Bubble)2 이라고 합니다.
유튜브에서 음모론 영상을 한 번 보면, 관련 영상이 끝없이 추천되면서 점점 깊은 토끼굴로 빠져드는 현상이 대표적입니다. 알고리즘은 “이 사용자가 클릭한 것“을 더 보여줄 뿐, “이 사용자에게 좋은 것“을 판단하지 못합니다. 실제로 유튜브에서 시청되는 콘텐츠의 약 **70%**가 추천 알고리즘에 의해 선택됩니다.3 내가 무엇을 볼지를 내가 아니라 알고리즘이 결정하는 셈입니다.
틱톡의 알고리즘이 유독 중독적인 이유도 여기에 있습니다. 틱톡은 짧은 영상을 끊임없이 보여주면서, 사용자가 어떤 영상에서 멈추고, 어떤 영상을 빠르게 넘기는지를 밀리초 단위로 분석합니다. 영상을 3초 만에 넘겼는지, 끝까지 봤는지, 다시 봤는지 — 이 모든 데이터가 다음 추천에 반영됩니다. 사용자가 “좋아요“를 누르기도 전에, 행동 자체가 데이터입니다.
ChatGPT: “다음 단어 예측기”
추천 알고리즘에서 한 발 더 나아가면, AI(인공지능) 이야기가 됩니다.
2022년 11월에 공개된 ChatGPT는 대화하듯 질문에 답하고, 글을 쓰고, 코드를 작성합니다. 이 기술의 핵심을 한 문장으로 요약하면 이렇습니다.
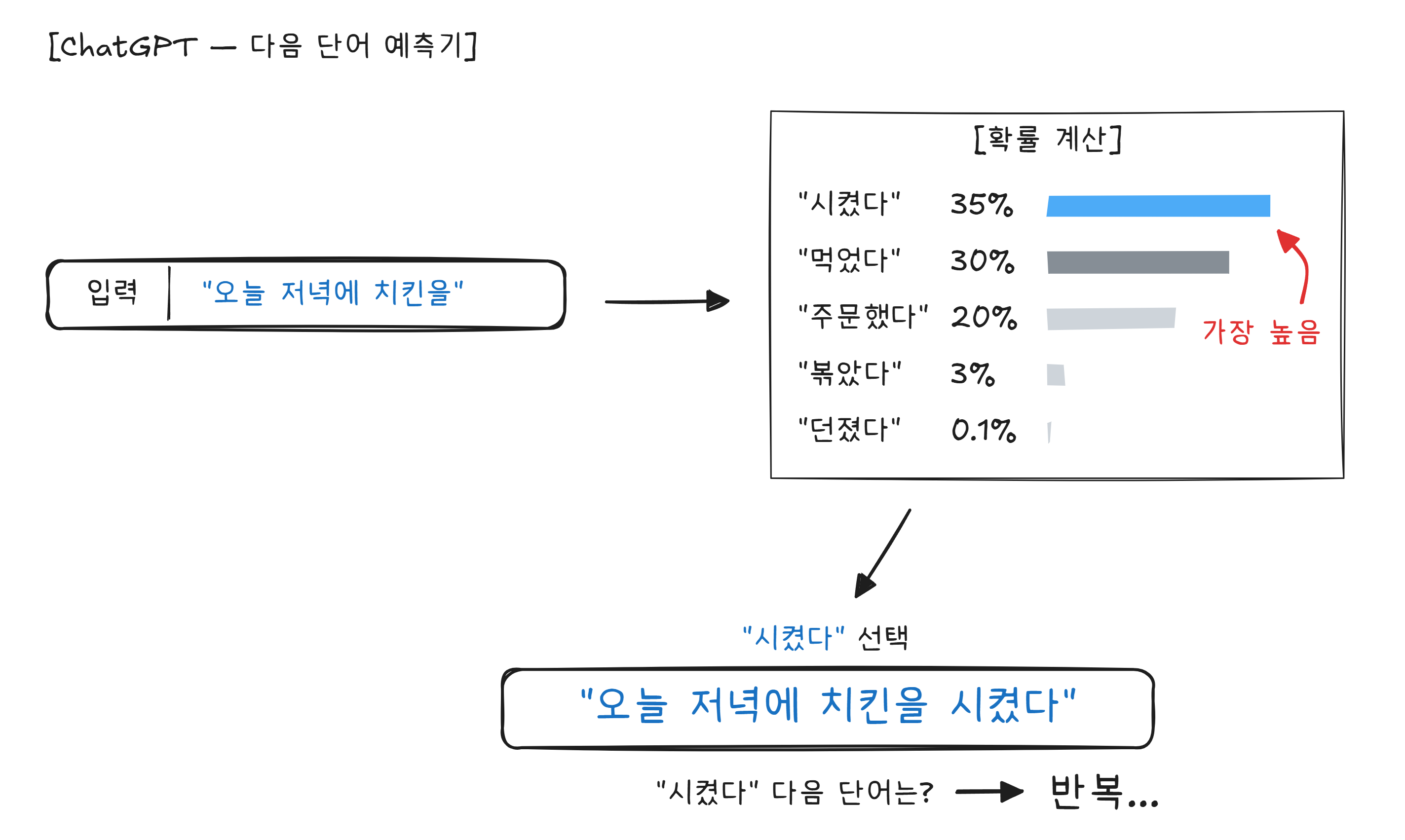
“주어진 텍스트 다음에 올 확률이 가장 높은 단어를 예측하는 것”
“오늘 저녁에 치킨을“이라는 문장 다음에 올 단어로 “시켰다“가 올 확률은 높고, “던졌다“가 올 확률은 낮습니다. 이 확률을 수조 개의 텍스트 데이터에서 학습한 것이 대규모 언어 모델(LLM)4 입니다.
수만 권의 책, 수십억 개의 웹페이지를 학습한 모델은 “다음 단어 예측“이라는 단순한 과제를 수행할 뿐인데, 그 결과물이 마치 이해하고 사고하는 것처럼 보입니다. 번역을 하고, 시를 쓰고, 수학 문제를 풀고, 코드를 작성합니다.
이것이 진정한 “이해“인지, 아니면 패턴의 정교한 모방인지는 현재 AI 분야에서 가장 뜨거운 논쟁 중 하나입니다.
학습의 규모는 상상을 초월합니다. ChatGPT의 기반이 된 GPT 시리즈는 위키피디아 전체, 수백만 개의 웹페이지, 수만 권 분량의 텍스트를 학습 데이터로 사용했습니다. 모델 내부에는 수천억 개의 **매개변수(parameter)**가 있으며, 이것이 텍스트의 패턴을 저장합니다. 뇌의 시냅스가 경험을 저장하듯, 매개변수가 언어의 패턴을 저장하는 것이죠.
그런데 이 모델이 바로 ChatGPT가 되는 것은 아닙니다. 대량의 텍스트로 학습한 모델은 “다음 단어 예측“은 잘하지만, 사람과 자연스럽게 대화하지는 못합니다. 여기에 **인간 피드백 강화학습(RLHF)5**이라는 단계가 추가됩니다. 사람이 모델의 여러 답변 중 더 나은 것을 골라주면, 모델이 그 선호를 학습합니다. “이렇게 대답하면 사람이 더 만족한다“를 배우는 과정입니다.
사건: 아마존 채용 AI의 성별 편향
2018년, 아마존이 채용에 사용하던 AI 시스템이 여성 지원자를 체계적으로 불이익 처리하고 있었다는 사실이 밝혀집니다.6
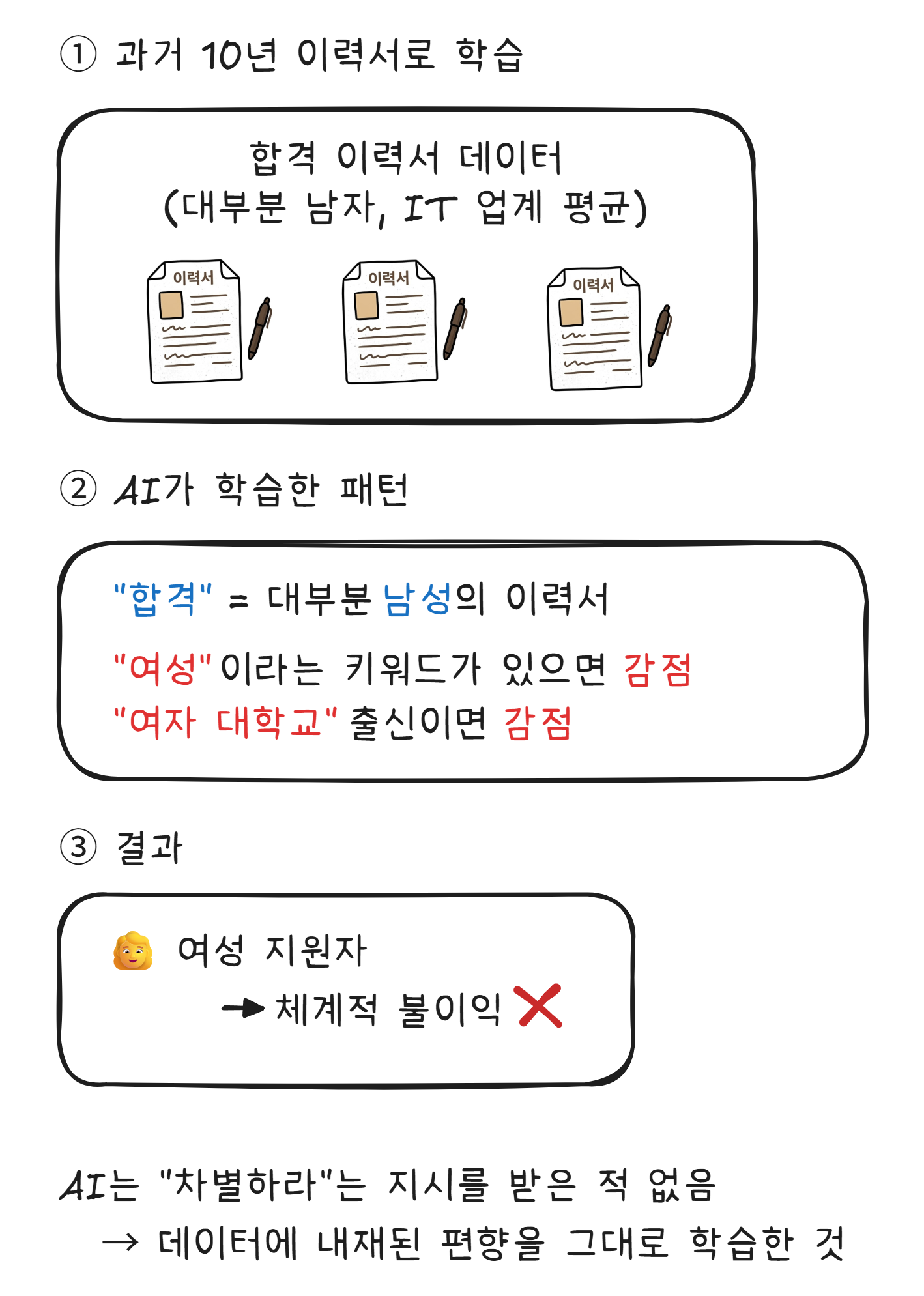
AI는 주어진 데이터에서 패턴을 학습합니다. 데이터에 편향이 있으면, AI도 편향을 학습합니다. “과거에 이런 사람이 합격했다“를 학습한 AI는 미래에도 같은 패턴을 반복합니다. 세상이 변해야 하는 부분까지 과거의 패턴으로 고정시키는 겁니다.
아마존은 이 시스템을 폐기했습니다. 하지만 이 사건은 중요한 질문을 던집니다 — AI가 공정한지는 AI가 아니라, AI에 넣는 데이터가 결정한다.
이 사건 이후, AI 윤리와 공정성은 AI 연구의 핵심 주제가 되었습니다. 학습 데이터의 편향을 감지하고 교정하는 기법, AI가 왜 그런 결정을 내렸는지 설명할 수 있게 만드는 설명 가능한 AI(Explainable AI, XAI) 연구가 활발해졌습니다.
알쓸신잡
-
CAPTCHA로 AI를 학습시키고 있다: 10장에서 CAPTCHA 이야기를 했습니다. 사실 한 발 더 나아가면, 구글의 reCAPTCHA에서 “이 사진에서 버스를 모두 고르세요” 같은 문제에 답할 때, 여러분은 자율주행 AI의 학습 데이터를 라벨링하고 있는 것입니다. 사람이 “이것은 버스다”, “이것은 신호등이다“라고 알려주면, AI가 그것을 학습합니다. 전 세계 수억 명이 무료로 AI 학습에 참여하고 있는 셈입니다.
-
AI가 그린 그림의 저작권은 누구에게?: AI 이미지 생성 모델(Midjourney, DALL-E 등)이 만든 그림의 저작권 문제는 아직 해결되지 않았습니다. AI가 학습한 원본 작가의 그림은? AI를 사용한 사람의 권리는? AI 자체의 저작권은? 2023년 미국 저작권청은 “AI가 생성한 이미지에는 저작권을 부여하지 않는다“고 결정했지만, “AI를 도구로 사용하되 인간이 창작적 기여를 한 경우“는 인정할 수 있다고 단서를 붙였습니다.7 법과 기술의 간극이 그 어느 때보다 벌어지고 있는 영역입니다.
-
추천 알고리즘은 “최적“이 아니라 “이익“을 추구한다: 유튜브 알고리즘은 사용자에게 “최고의 영상“을 추천하는 것이 아니라, “가장 오래 머물게 하는 영상” 을 추천합니다. 사용자의 시청 시간이 길수록 더 많은 광고를 보여줄 수 있기 때문입니다. 같은 논리로 배달앱은 “가장 맛있는 가게“가 아니라 “가장 많이 주문하게 만드는 가게“를 상위에 노출할 유인8이 있습니다. 알고리즘이 최적화하는 대상이 무엇인지를 아는 것이 중요합니다 — 그것이 항상 사용자의 이익과 일치하지는 않습니다.
배달 완료까지 10분
치킨이 도착했고, 맛있게 먹었습니다. 그리고 배달앱은 이 주문을 기억합니다. 다음에 앱을 열면 치킨집이 상단에 뜨고, “이 치킨집 어떠세요?“라는 추천이 나타날 것입니다.
돌아보면, 치킨 한 마리를 시키는 동안 놀라운 일들이 벌어졌습니다. 터치스크린이 손가락을 감지하고, 운영체제가 명령을 처리하고, WiFi와 LTE가 전파를 쏘고, 해저 케이블이 빛의 신호를 전달하고, DNS가 주소를 찾고, TCP가 데이터를 검증하고, 서버가 검색 결과를 돌려주고, 데이터베이스가 메뉴를 불러오고, 암호화가 결제를 보호하고, GPS가 배달 경로를 계산하고, 추천 알고리즘이 다음 주문을 예측했습니다.
컴퓨터 과학의 거의 모든 분야가 동원된 이 여정은, 여러분이 주문 버튼을 누른 그 10분 안에 모두 일어났습니다.
-
앙상블(Ensemble): 여러 개의 모델(알고리즘)의 예측을 결합해서 하나의 더 정확한 예측을 만드는 기법. 한 사람의 의견보다 여러 전문가의 종합 의견이 정확한 것과 같은 원리. ↩
-
필터 버블(Filter Bubble): 알고리즘이 사용자가 좋아할 만한 정보만 보여주면서, 사용자가 자신만의 “거품” 안에 갇히는 현상. 2011년 엘리 패리서가 만든 용어. ↩
-
유튜브 추천의 시청 시간 기여: YouTube CPO Neal Mohan 인터뷰, CNET (2018). https://www.cnet.com/tech/services-and-software/youtube-ces-2018-neal-mohan/ ↩
-
LLM(Large Language Model): 대규모 언어 모델. 방대한 텍스트 데이터로 학습한 AI 모델. GPT, Claude, Gemini 등이 대표적. ↩
-
RLHF(Reinforcement Learning from Human Feedback): 인간 피드백 강화학습. AI 모델의 답변을 사람이 평가하고, 그 평가를 바탕으로 모델을 개선하는 기법. ↩
-
아마존 AI 채용 성별 편향: Jeffrey Dastin, “Amazon scraps secret AI recruiting tool that showed bias against women”, Reuters (2018.10.10). https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G ↩
-
AI 저작권 결정: U.S. Copyright Office, “Zarya of the Dawn” Registration Decision (2023.02.21). https://www.copyright.gov/docs/zarya-of-the-dawn.pdf ↩
-
유인(Incentive): 특정 행동을 하게 만드는 동기나 보상. 경제학에서 개인이나 기업의 행동을 설명하는 핵심 개념. ↩